
概括 这篇文章将卷积比较自然地拓展到点云的情形,思路很赞! 文章的主要创新点:“weight function”和“density function”,并能实现translationinvariance和permutationinvariance,可以实现层级化特征提取,而且能自然推广到其deconvolution的情形实现分割,在二维CIFAR10图像分类任务中精度堪比CNN(表明能够充分近似卷积网络),达到了SOTA的性能。 缺点:每个kernel都需要由“kernel function”生成,而“kernel function”实质上是一个CNN网络,计算量比较大。 思想 察觉到:二维卷积中pixel的相对centroid位置与kernel vector的生成方式有关。 以二维卷积为例...

Hough Voting 本文的标题是Deep Hough Voting,先来说一下Hough Voting。 用Hough变换检测直线大家想必都听过:对于一条直线,可以使用(r, θ)两个参数进行描述,那么对于图像中的一点,过这个点的直线有很多条,可以生成一系列的(r, θ),在参数平面内就是一条曲线,也就是说,一个点对应着参数平面内的一个曲线。那如果有很多个点,则会在参数平面内生成很多曲线。那么,如果这些点是能构成一条直线的,那么这条直线的参数(r, θ)就在每条曲线中都存在,所以看起来就像是多条曲线相交在(r,θ)。可以用多条曲线投票的方式来看,其他点都是很少的票数,而(r,θ)则票数很多,所以直线的参数就是(r,θ)。 所以Hough变换的思想就是在于,在参数空间内进行投票,投票得数...
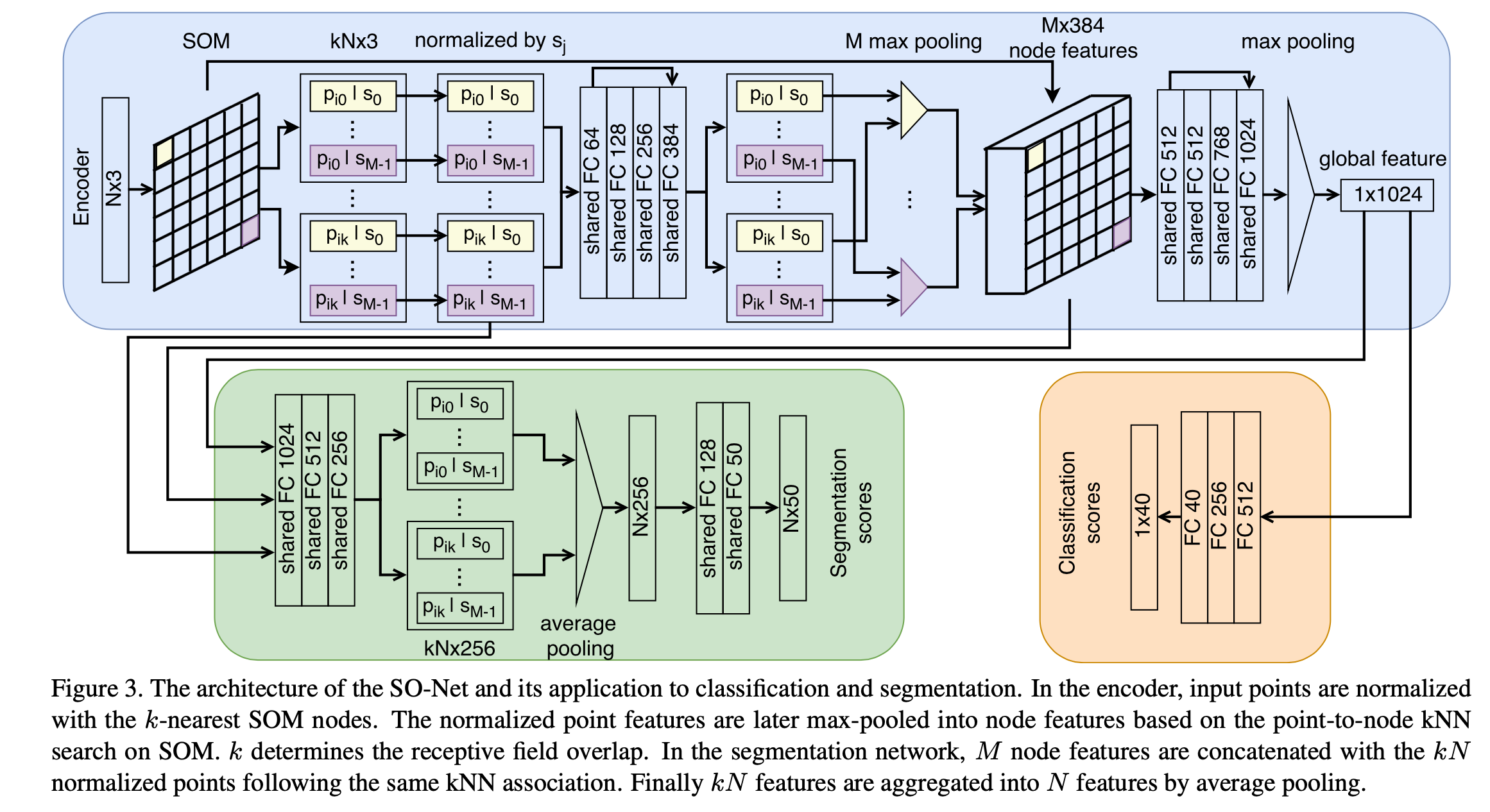
概括 针对一些网络在处理point cloud时的缺点,如:不能对点的空间分布进行建模(例如PointNet++,只是能获取局部信息不能得到局部区域之间的空间关系),提出了SONet。SO的含义是利用Selforganizing map的Net。 结果:它具有能够对点的空间分布进行建模、层次化特征提取、可调节的感受野范围的优点,并能够用于多种任务如重建、分类、分割等等。取得了相似或超过SOTA的性能,因为可并行化和架构简单使得训练速度很快。 贡献: TODO IDEA:作者发现将CNN直接用于SOM图上性能不升反降,为什么(推测:可能是SOM的2D map并不是保持了原本的空间对应关系,可能nodes之间是乱序的,导致用conv2d时精度反而降低)? 难点 如何对local regions之...
3D Model
2026-01-11
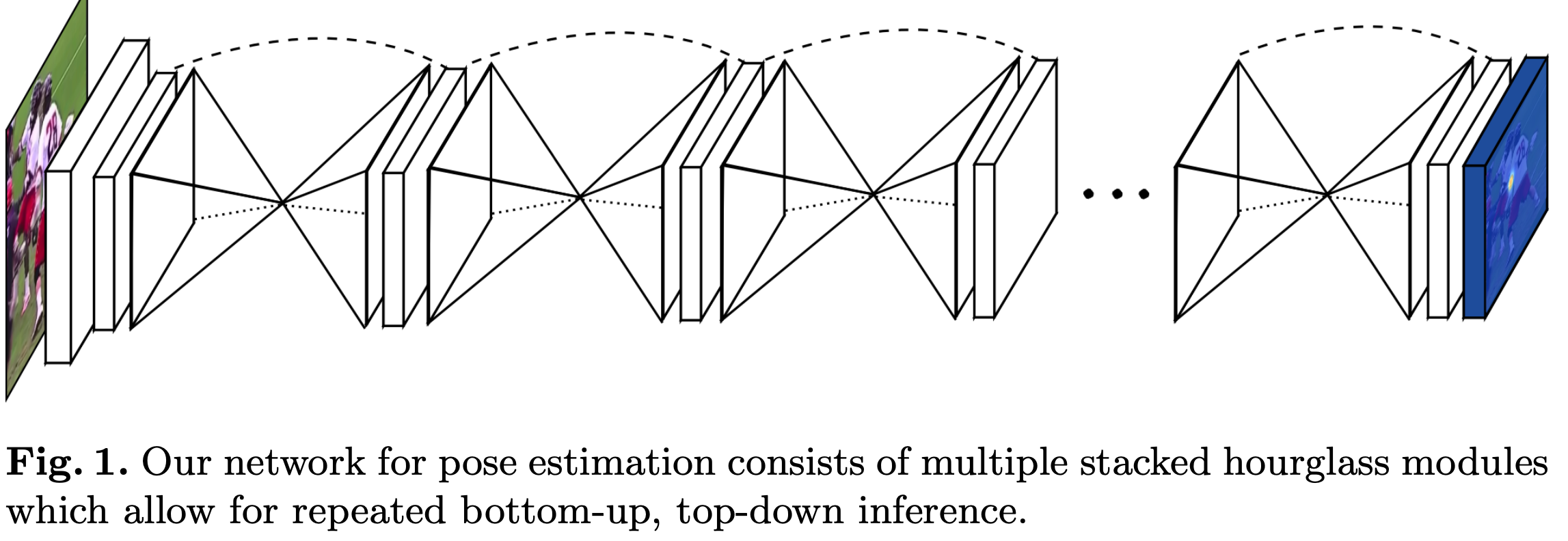
论文介绍了一种新的网络结构用于人体姿态检测,作者在论文中展现了不断重复bottomup、topdown过程以及运用intermediate supervison(中间监督)对于网络性能的提升,下面来介绍Stacked Hourglass Networks. 简介 理解人类的姿态对于一些高级的任务比如行为识别来说特别重要,而且也是一些人机交互任务的基础。作者提出了一种新的网络结构Stacked Hourglass Networks来对人体的姿态进行识别,这个网络结构能够捕获并整合图像所有尺度的信息。之所以称这种网络为Stacked Hourglass Networks,主要是它长得很像堆叠起来的沙漏,如下图所示: 这种堆叠在一起的Hourglass模块结构是对称的,bottomup过程将图片从...
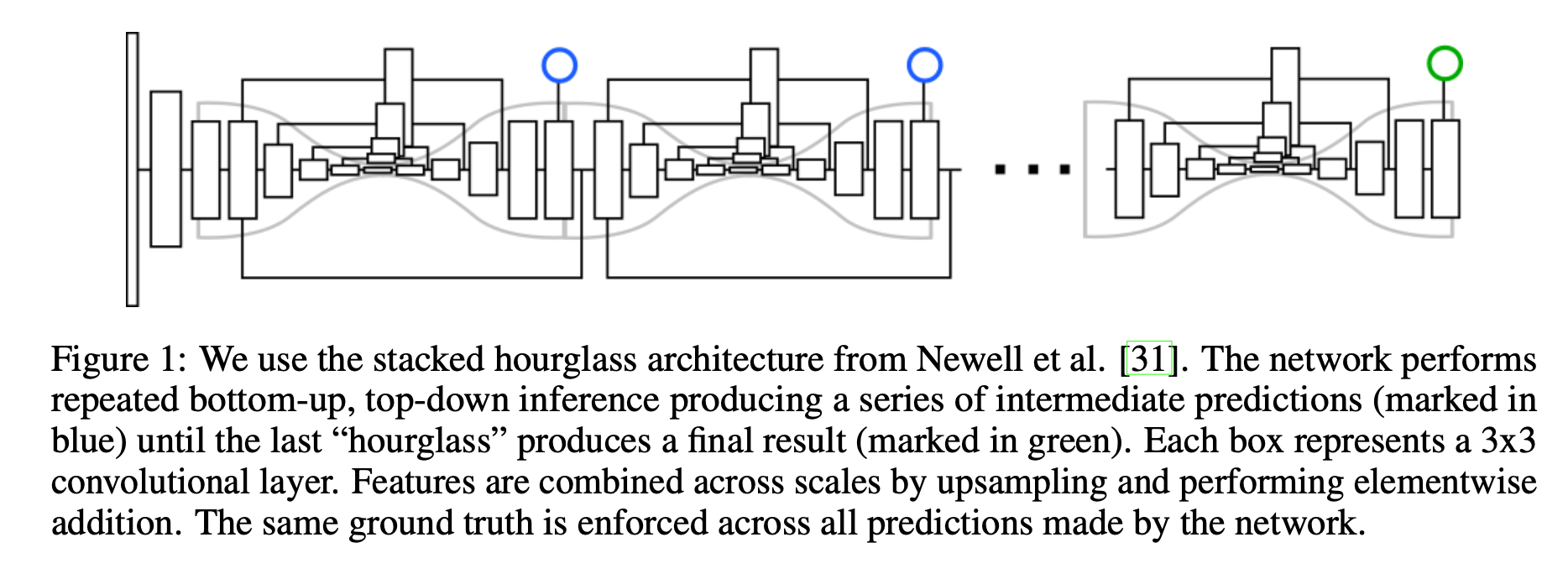
简介 作者认为许多计算机视觉的任务可以看作是检测和分组问题检测一些小的单元,然后将它们组合成更大的单元,例如,多人目标检测可以通过检测人的关节点然后再将它们进行分组(属于同一个人的关节点为一组)解决;实例分割问题可以看作是检测一些相关的像素然后将它们组合成一个目标实例。 Associative Embedding是一种表示关节检测和分组任务的输出的新方法,其基本思想是为每次检测引入一个实数,用作识别对象所属组的“tag”,换句话说,标签将每个检测与同一组中的其他检测相关联。作者使用一个损失函数使得如果相应的检测属于ground truth中的相同组则促使这一对标签具有相似的值。需要注意的是,这里标签具体的值并不重要,重要的是不同标签之间的差异。 这篇其实是源自Stacked Hourglas...
3D Model
2026-01-11

整体流程: [代码] 0. 数据预处理 这个步骤主要是crop四路数据,及生成后续步骤所需要的yaml文件。 1. 四路相机与双路相机标定 内参标定 [代码] 这里主要的函数就是: pts = cv2.findChessboardCorners(img, (board_width, board_height))[1] cv2.cornerSubPix(gray, pts, (12, 12), (1, 1), (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_COUNT, 30, 0.1)) det, intr, dist, _, _ = cv2.calibrateCamera(obj_pts, img_pts, self.imgSize, None, No...
Reinforcement Learning
2026-01-11

引言与背景 蒙特卡洛方法是强化学习中的重要算法类别,它标志着从基于模型到无模型算法的转变。这类算法不依赖环境模型,而是通过与环境的直接交互获取经验数据来学习最优策略。 蒙特卡洛方法在强化学习算法谱系中处于"无模型"方法的起始位置,是从基于模型的方法(如值迭代和策略迭代)向无模型方法过渡的第一步。 无模型强化学习的核心理念可以简述为:如果没有模型,我们必须有数据;如果没有数据,我们必须有模型;如果两者都没有,我们就无法找到最优策略。在强化学习中,"数据"通常指智能体与环境交互的经验。 均值估计问题 在介绍蒙特卡洛强化学习算法之前,我们首先需要理解均值估计问题,这是理解从数据而非模型中学习的基础。 考虑一个可以取有限实数集合 X 中值的随机变量 X ,我们的任务是计算 X 的均值或期望值: E[...
Large Model
2026-01-11

UITARS 简介 UITARS(User Interface Task Automation and Reasoning System)是由字节跳动(ByteDance)研发的原生 GUI 智能体模型: 输入方式:仅使用屏幕截图作为视觉输入 交互方式:执行类人操作(键盘输入、鼠标点击、拖拽等) 模型特性:端到端的原生智能体模型,无需复杂的中间件或框架 传统 GUI 智能体的开发往往依赖于文本信息,例如 HTML 结构和可访问性树。虽然这些方法取得了一些进展,但它们也存在一些局限性: 平台不一致性:不同平台的 GUI 结构差异很大,导致智能体难以跨平台通用。 信息冗余:文本信息往往过于冗长,增加了模型的处理负担。 访问限制:获取系统底层的文本信息通常需要较高的权限,限制了应用的范围。 模块化...
Generative Model
2026-01-11

给定一个包含 n 维数据 x 的数据集 D , 简单起见,假设数据 [Math] . 由于真正对联合分布建模的时候, x,y 都是随机变量,故而只需讨论 p(X)=p(x_1,...,x_n) 即可,毕竟只需要令 x_n=y 即可。 给定一个具体的任务,如MNIST中的手写数字二值图分类,从Generative的角度进行Represent,并在Inference中Learning. 下面先介绍: 描述如何对这个MINST任务建模 p(X,Y) (Representation) 对MNIST任务建模 对于一张pixel为 [Math] 大小的图片,令 x_1 表示第一个pixel的随机变量, [Math] ,需明确: 任务目标:学习一个模型分布 [Math] ,使采样时 [Math] , x ...

论文地址: 🔖 https://arxiv.org/pdf/2107.11291 代码地址: 前言 一般来说,我们可以把姿态估计任务分成两个流派:Heatmapbased和Regressionbased。 其主要区别在于监督信息的不同,Heatmapbased方法监督模型学习的是高斯概率分布图,即把GroundTruth中每个点渲染成一张高斯热图,最后网络输出为K张特征图对应K个关键点,然后通过argmax或softargmax来获取最大值点作为估计结果。这种方法由于需要渲染高斯热图,且由于热图中的最值点直接对应了结果,不可避免地需要维持一个相对高分辨率的热图(常见的是64x64,再小的话误差下界过大会造成严重的精度损失),因此也就自然而然导致了很大的计算量和内存开销。 Regression...
Reinforcement Learning
2026-01-11

引言与背景 价值函数方法是强化学习中的核心技术,它解决了传统表格方法在处理大型状态或动作空间时的效率问题。本文探讨了从表格表示向函数表示的转变,这是强化学习算法发展的重要里程碑。 在强化学习的发展路径中,价值函数方法位于从基于模型到无模型、从表格表示到函数表示的演进过程中。它结合了时序差分学习的思想,并通过函数近似技术来处理复杂环境。 价值表示:从表格到函数 表格与函数表示的对比 传统的表格方法将状态值存储在一个表格中: 而函数近似方法则使用参数化函数来表示这些值,例如: [公式] 其中 [Math] 称作是状态 s 的特征向量, w 是参数向量。 两种不同的表现形式的区别主要体现在以下几个方面: 值的检索方式 值的更新方式 函数复杂度与近似能力 函数的复杂度决定了其近似的能力: 一阶线性函...
3D Model
2026-01-11
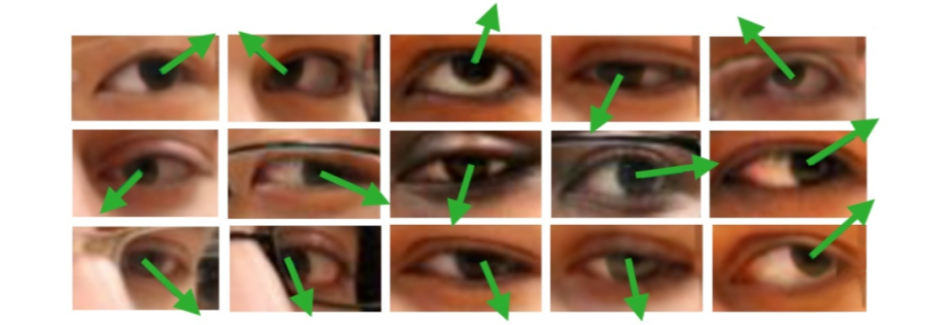
概述 问题定义 广义的 Gaze Estimation 泛指与眼球、眼动、视线等相关的研究,因此有不少做 saliency 和 egocentric 的论文也以 gaze 为关键词。而本文介绍的 Gaze Estimation 主要以眼睛图像或人脸图像为处理对象,估算人的视线方向或注视点位置, 如下图所示。 gaze角度的表示一般使用一个3d向量作为表示,也可以转换为pitch 和yaw角度,具体可参考 Model Gaze模型一般使用回归模型,所以这里基本只介绍一些在gaze model中使用的小技巧 Rle Loss 实际问题