
简介 生成树(spanning tree) 在图论中,无向图 G=(V,E) 的生成树(spanning tree)是具有G的全部顶点,但边数最少的联通子图。假设G中一共有n个顶点,一颗生成树满足下列条件: (1)n个顶点; (2)n1条边; (3)n个顶点联通; (4)一个图的生成树可能有多个。最小生成树(minimum spanning tree, MST)/最小生成森林:联通加权无向图中边缘权重加和最小的生成树。给定无向图 G=(V,E) , (u,v) 代表顶点 u 与顶点 v 的边, w(u,v) 代表此边的权重,若存在生成树T使得: [公式] 最小,则 T 为 G 的最小生成树。对于非连通无向图来说,它的每一连通分量同样有最小生成树,它们的并被称为最小生成森林。最小生成树除了继承...
Computer Vision
2026-01-11
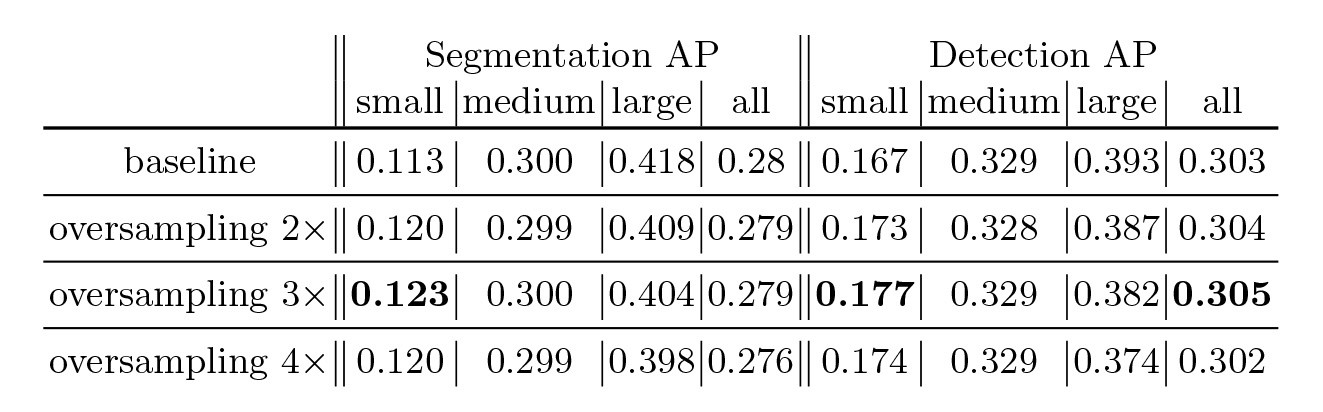
在深度学习目标检测中,特别是人脸检测中,由于分辨率低、图像模糊、信息少、噪声多,小目标和小人脸的检测一直是一个实用和常见的难点问题。然而,在过去几年的发展中,也出现了一些提高小目标检测性能的解决方案。本文将对这些方法进行分析、整理和总结。 图像金字塔和多尺度滑动窗口检测 一开始,在深学习方法成为流行之前,对于不同尺度的目标,通常是从原始图像开始,使用不同的分辨率构建图像金字塔,然后使用分类器对金字塔的每一层进行滑动窗口的目标检测。 在著名的人脸检测器MTCNN中,使用图像金字塔法检测不同分辨率的人脸目标。然而,这种方法通常是缓慢的,虽然构建图像金字塔可以使用卷积核分离加速或简单粗暴地缩放,但仍需要做多个特征提取,后来有人借其想法想出一个特征金字塔网络FPN,在不同层融合特征,只需要一次正向计...
Computer Vision
2026-01-11
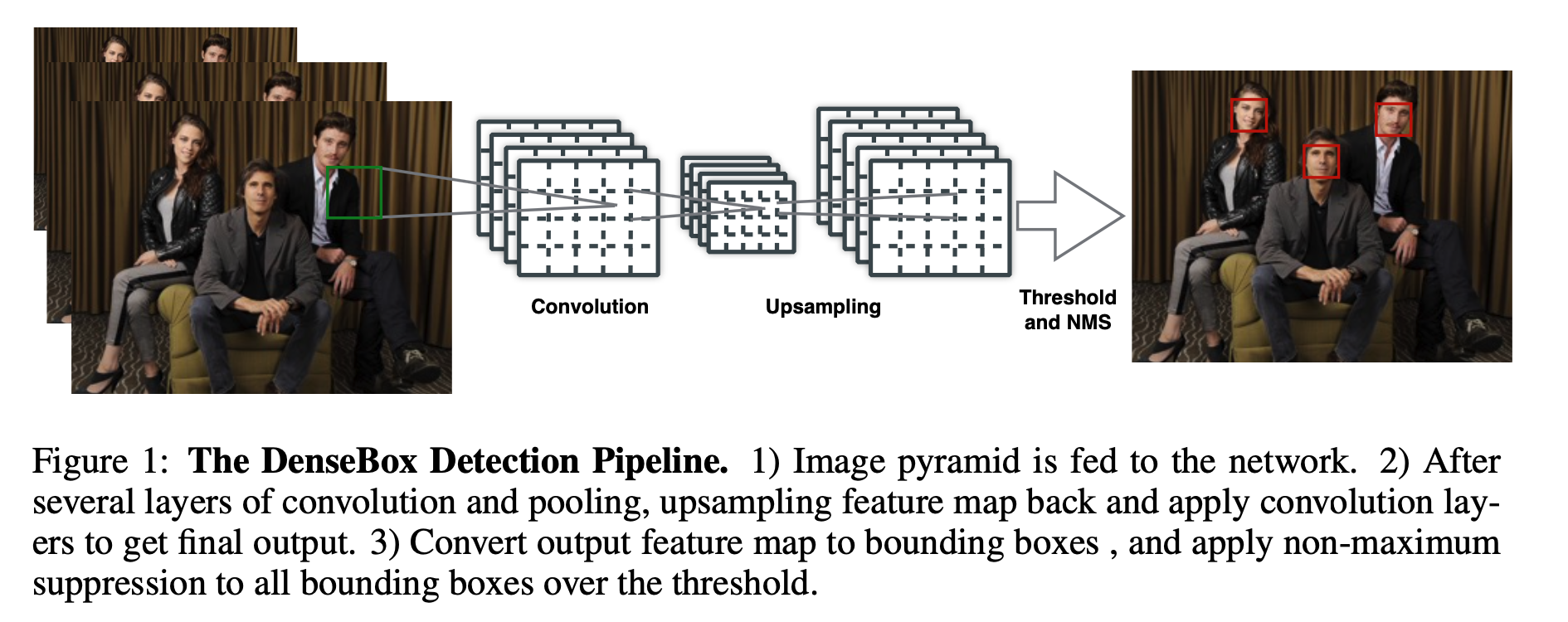
简介 "Anchorfree"(无锚点)是一种目标检测方法,与传统的使用锚框(anchor boxes)的方法(例如Faster RCNN)不同。在传统方法中,锚框是预先定义的、具有不同尺寸和长宽比的矩形区域,用于捕捉不同尺寸和形状的目标。而在"anchorfree"方法中,不再使用锚框,而是直接预测目标的位置和形状,通常使用网络输出的热图和偏移信息。 以下是对"anchorfree"方法的一些关键理解点: 无需预定义锚框: 在传统目标检测方法中,需要事先定义和生成一组锚框,这可能需要大量的人工工作。而在"anchorfree"方法中,不再需要锚框,模型可以自动学习目标的位置和形状。 直接位置和形状回归: "anchorfree"方法通过输出的热图来表示目标的存在概率,并使用偏移信息来定位目...
Computer Vision
2026-01-11
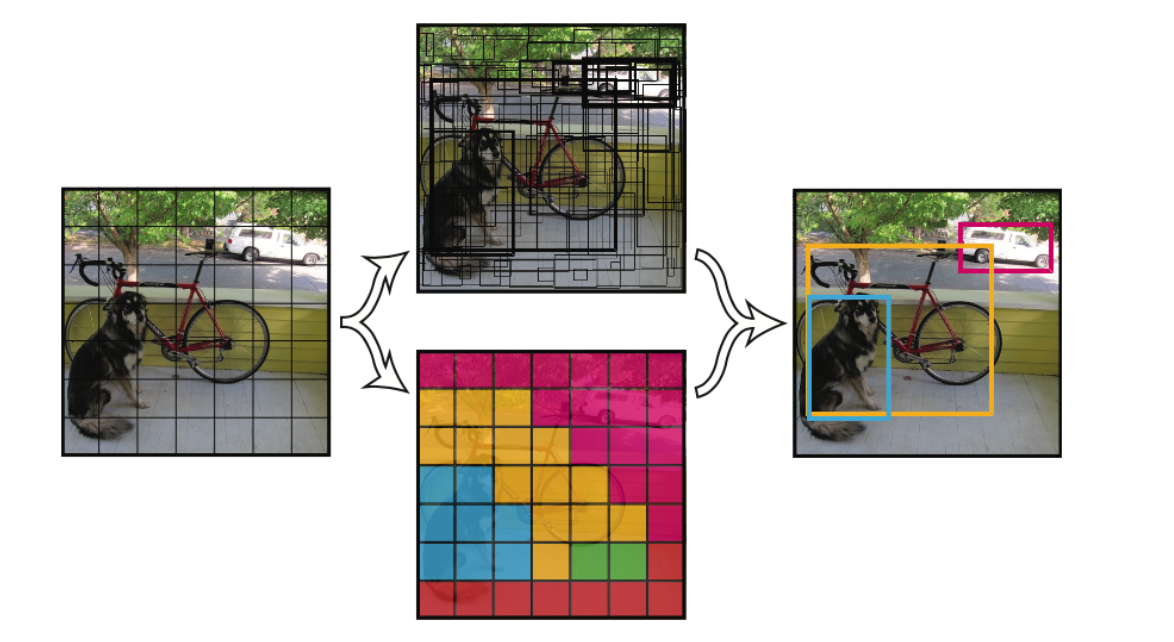
YOLO的核心思想就是利用整张图作为网络的输入,直接在输出层回归bounding box的位置和bounding box所属的类别。 faster RCNN中也直接用整张图作为输入,但是fasterRCNN整体还是采用了RCNN那种 proposal+classifier的思想,只不过是将提取proposal的步骤放在CNN中实现了,而YOLO则采用直接回归的思路。 YOLO v1 将一幅图像分成SxS个网格(grid cell),如果某个object的中心 落在这个网格中,则这个网格就负责预测这个object。 每个网格要预测B个bounding box,每个bounding box除了要回归自身的位置之外,还要附带预测一个confidence值。 这个confidence代表了所预测的b...
Algorithm
2026-01-11
给一个无向图,判断其是否为一棵树。如果是树的话,所有的节点必须是连接的,也就是说必须是连通图,而且不能有环,所以就变成了验证是否是连通图和是否含有环。 [代码]
Algorithm
2026-01-11
题目 中位数是有序列表中间的数。如果列表长度是偶数,中位数则是中间两个数的平均值。 例如, [2,3,4] 的中位数是 3 [2,3] 的中位数是 (2 + 3) / 2 = 2.5 设计一个支持以下两种操作的数据结构: void addNum(int num) 从数据流中添加一个整数到数据结构中。 double findMedian() 返回目前所有元素的中位数。 示例: addNum(1) addNum(2) findMedian() 1.5 addNum(3) findMedian() 2 题解 维护两个堆:大顶堆和小顶堆。并且需满足如下条件: 小顶堆的所有元素都大于等于大顶堆的所有元素。 大顶堆中的元素数量大于等于小顶堆中的元素数量。 大顶堆对应排序后的列表的左半部分;小顶堆对应排序...
Algorithm
2026-01-11
[代码] 自己实现小顶堆 [代码] 变态的需求来了:给出N长的序列,求出BtmK小的元素,即使用大顶堆。 概括一种最简单的: 将push(e)改为push(e)、pop(e)改为pop(e)。 也就是说,在存入堆、从堆中取出的时候,都用相反数,而其他逻辑与TopK完全相同,看代码: [代码] 自己实现大顶堆 [代码]
二叉树结构 [代码] 递归 时间复杂度:O(n),n为节点数,访问每个节点恰好一次。 空间复杂度:空间复杂度:O(h),h为树的高度。最坏情况下需要空间O(n),平均情况为O(logn) 递归1: 二叉树遍历最易理解和实现版本 [代码] 递归2: 通用模板 可以适应不同的题目,添加参数、增加返回条件、修改进入递归条件、自定义返回值 [代码] 迭代 时间复杂度:O(n),n为节点数,访问每个节点恰好一次。 空间复杂度:O(h),h为树的高度。取决于树的结构,最坏情况存储整棵树,即O(n) 迭代1: 前序遍历最常用模板(后序同样可以用) [代码] 迭代2: 前、中、后序遍历通用模板(只需一个栈的空间) [代码] 迭代3:标记法迭代(需要双倍的空间来存储访问状态) 前、中、后、层序通用模板,只需改...
背包问题
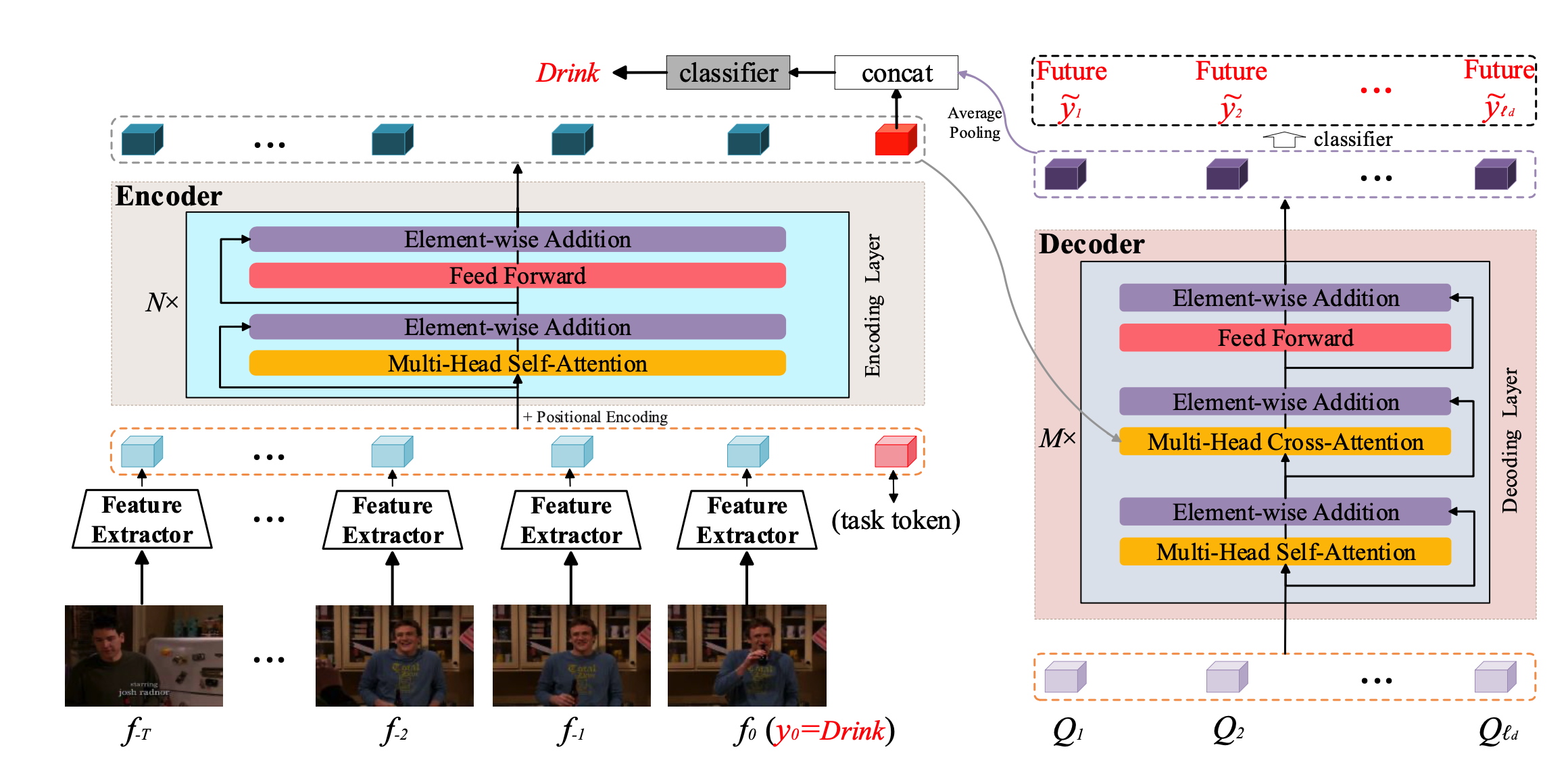
简介 之前的很多方法都是用RNN的结构去构建时序上的依赖关系,但是RNN的结构的缺点是不能并行操作,且存在梯度消失的现象。所以本文就是将之前的RNN的结构改为Transfomer的形式。延续了之前TRN的整个网络的框架,也是结合了对未来帧的预测与历史帧的表示相结合来对当前的动作进行预测。 方法 整个网络框架如上图所示, Encoder就是利用transfomer对longrange的历史和目前帧进行特征表示,其中要说明的一个点就是,这里的特征空间包含T个历史特征,当前窗口的特征以及一个task token,这个task token的作用可以从下图看出来 这幅图对比的是输入进classifier的特征与网络输入的特征的相似性,可以看出w/o task token 对应的是当前t=0时刻的特征,...
杂七杂八
2026-01-11
大数据本身是个很宽泛的概念,Hadoop生态圈(或者泛生态圈)基本上都是为了处理超过单机尺度的数据处理而诞生的。你可以把它比作一个厨房所以需要的各种工具。锅碗瓢盆,各有各的用处,互相之间又有重合。你可以用汤锅直接当碗吃饭喝汤,你可以用小刀或者刨子去皮。但是每个工具有自己的特性,虽然奇怪的组合也能工作,但是未必是最佳选择。 大数据,首先你要能存的下大数据 传统的文件系统是单机的,不能横跨不同的机器。HDFS(Hadoop Distributed FileSystem)的设计本质上是为了大量的数据能横跨成百上千台机器,但是你看到的是一个文件系统而不是很多文件系统。比如你说我要获取/hdfs/tmp/file1的数据,你引用的是一个文件路径,但是实际的数据存放在很多不同的机器上。你作为用户,不需要...