Reinforcement Learning
2026-03-27
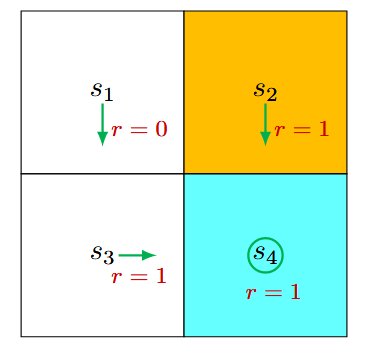
状态价值(State values) 定义 状态价值是强化学习中的核心概念,用于衡量Agent从某个状态出发、遵循特定策略后所能获得的期望回报。 数学表达为: \[
v_\pi(s) = \mathbb{E}[G_t | S_t = s]
\tag{1}\] 其中: \(v_\pi(s)\) :状态 \(s\) 的状态价值函数(state-value function) 或者简称为 状态价值(state value); \(\pi\) :智能体遵循的策略; \(G_t = R_{t+1} + \gamma R_{t+2} + \gamma^2 R_{t+3} + \dots\) :从当前时间步 \(t\) 开始的折扣回报; \(\gamma \in (0, 1)\) :折扣因子,用于平衡即时奖励和未来奖励。 状态价值的特点 依赖于状态 \(s\) :状态价值是条件期望,条件是智能体从状态 \(s\) 开始。 依赖于策略 \(\pi\) :不同策略会生成不同的轨迹,从而影响状态价值。 与时间步无关 :状态价值是一个固定值,与当前时间步 \(t\) 无关。 代表一个状态的价值。...









