二叉树结构 [代码] 递归 时间复杂度:O(n),n为节点数,访问每个节点恰好一次。 空间复杂度:空间复杂度:O(h),h为树的高度。最坏情况下需要空间O(n),平均情况为O(logn) 递归1: 二叉树遍历最易理解和实现版本 [代码] 递归2: 通用模板 可以适应不同的题目,添加参数、增加返回条件、修改进入递归条件、自定义返回值 [代码] 迭代 时间复杂度:O(n),n为节点数,访问每个节点恰好一次。 空间复杂度:O(h),h为树的高度。取决于树的结构,最坏情况存储整棵树,即O(n) 迭代1: 前序遍历最常用模板(后序同样可以用) [代码] 迭代2: 前、中、后序遍历通用模板(只需一个栈的空间) [代码] 迭代3:标记法迭代(需要双倍的空间来存储访问状态) 前、中、后、层序通用模板,只需改...
Computer Vision
2026-01-11
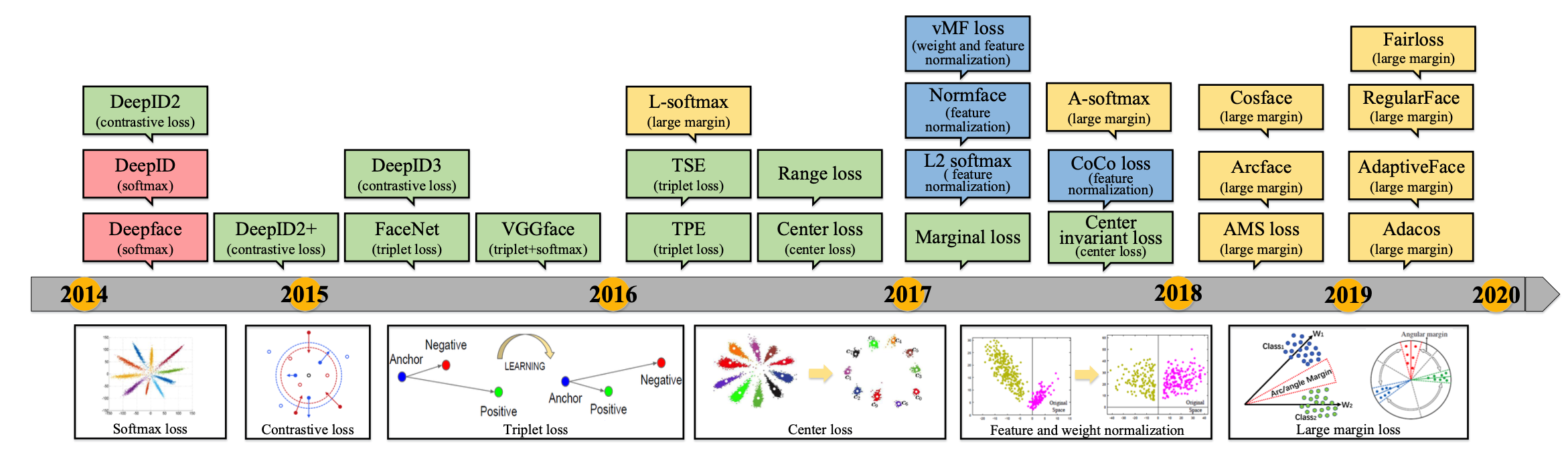
超多分类的Softmax 2014年CVPR两篇超多分类的人脸识别论文:DeepFace和DeepID DeepFace Taigman Y, Yang M, Ranzato M A, et al. Deepface: Closing the gap to humanlevel performance in face verification [C]// CVPR, 2014. 4.4M训练集,训练6层CNN + 4096特征映射 + 4030类Softmax,综合如3D Aligement, model ensembel等技术,在LFW上达到97.35%。 DeepID Sun Y, Wang X, Tang X. Deep learning face representation fro...
Computer Vision
2026-01-11
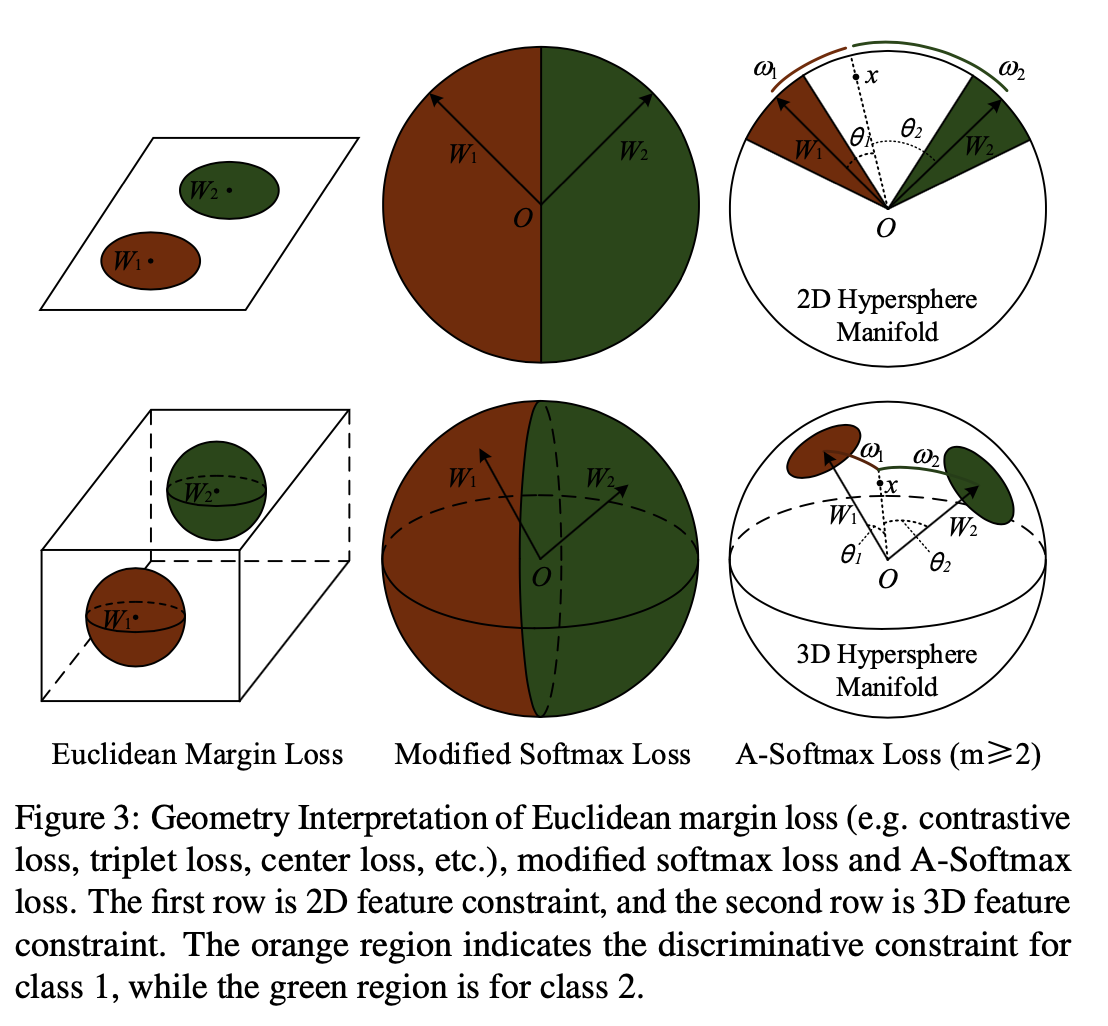
推导 回顾一下二分类下的Softmax后验概率,即: [公式] 显然决策的分界在当 𝑝_1=𝑝_2 时,所以决策界面是 (𝑊_1−𝑊_2)𝑥+𝑏_1−𝑏_2=0 。我们可以将 𝑊^𝑇_𝑖𝑥+𝑏_𝑖 写成 ‖W_i^T‖⋅‖x‖cos(θ_i)+b_i ,其中 θ_i 是 W_i 与 x 的夹角,如对 W_i 归一化且设偏置 b_i 为零( ‖W_i‖=1 , b_i=0 ),那么当 p_1=p_2 时,我们有 cos(θ_1)−cos(θ_2)=0 。从这里可以看到,如里一个输入的数据特征 x_i 属于 𝑦_𝑖 类,那么 θ_{y_i} 应该比其它所有类的角度都要小,也就是说在向量空间中 W_{y_i} 要更靠近 x_i 。 我们用的是Softmax Loss,对于输入 x_i ,So...
背包问题
Algorithm
2026-01-11

题目 给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。 百度百科中最近公共祖先的定义为:“对于有根树 T 的两个节点 p、q,最近公共祖先表示为一个节点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。” 示例 1: 输入:root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 1 输出:3 解释:节点 5 和节点 1 的最近公共祖先是节点 3 。 示例 2: 输入:root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 4 输出:5 解释:节点 5 和节点 4 的最近公共祖先是节点 5 。因为根据定义最近公共祖先节点可以为节点本身。 示例 3: 输入:root...
Algorithm
2026-01-11
题目 Given two sorted integer arrays nums1 and nums2, merge nums2 into nums1 as one sorted array. Note: The number of elements initialized in nums1 and nums2 are m and n respectively. You may assume that nums1 has enough space (size that is equal to m + n) to hold additional elements from nums2. Example: [代码] Constraints: 10^9 <= nums1[i], nums2[i] <...
Large Model
2026-01-11

梯度检查点(Gradient Checkpointing) 大模型的参数量巨大,即使将batch_size设置为1并使用梯度累积的方式更新,也仍然会OOM。原因是通常在计算梯度时,我们需要将所有前向传播时的激活值保存下来,这消耗大量显存。 还有另外一种延迟计算的思路,丢掉前向传播时的激活值,在计算梯度时需要哪部分的激活值就重新计算哪部分的激活值,这样做倒是解决了显存不足的问题,但加大了计算量同时也拖慢了训练。 梯度检查点(Gradient Checkpointing)在上述两种方式之间取了一个平衡,这种方法采用了一种策略选择了计算图上的一部分激活值保存下来,其余部分丢弃,这样被丢弃的那一部分激活值需要在计算梯度时重新计算。 下面这个动图展示了一种简单策略:前向传播过程中计算节点的激活值并保存...
DFS
NLP
2026-01-11

取代RNN——Transformer 在介绍Transformer前我们来回顾一下RNN的结构 对RNN有一定了解的话,一定会知道,RNN有两个很明显的问题 效率问题:需要逐个词进行处理,后一个词要等到前一个词的隐状态输出以后才能开始处理 如果传递距离过长还会有梯度消失、梯度爆炸和遗忘问题 为了缓解传递间的梯度和遗忘问题,设计了各种各样的RNN cell,最著名的两个就是LSTM和GRU了 LSTM (Long Short Term Memory) GRU (Gated Recurrent Unit) 但是,引用网上一个博主的比喻,这么做就像是在给马车换车轮,为什么不直接换成汽车呢? 于是就有了Transformer。Transformer 是Google Brain 2017的提出的一篇工...
计算几何(Computational Geometry),是一系列使用计算机解决几何问题的算法。与解析几何相比,计算几何更适合计算机运算,精度较高,运算速度较快,并且易于编写。 浮点误差 程序设计中,考虑到浮点数 double 有精度误差,在比较时,通常允许一定的误差,即对于两个数 a 、 b ,如果 [Math] ,则认为 a=b 。一般根据题目要求, d (代码中命名为 EPS)取一个较小值,如 10^{8} 。 [代码] 向量 向量(vector)是一个有大小和方向的量,在几何中,它被表示为带箭头的线段。向量可以用起点和终点的坐标来表示 —— 从点 A到点B 的向量表示为 [Math] 。 向量的书写,两个大写字母上加一个箭头(表示方向) [Math] 向量没有位置,即向量可以在平面内...
Computer Vision
2026-01-11
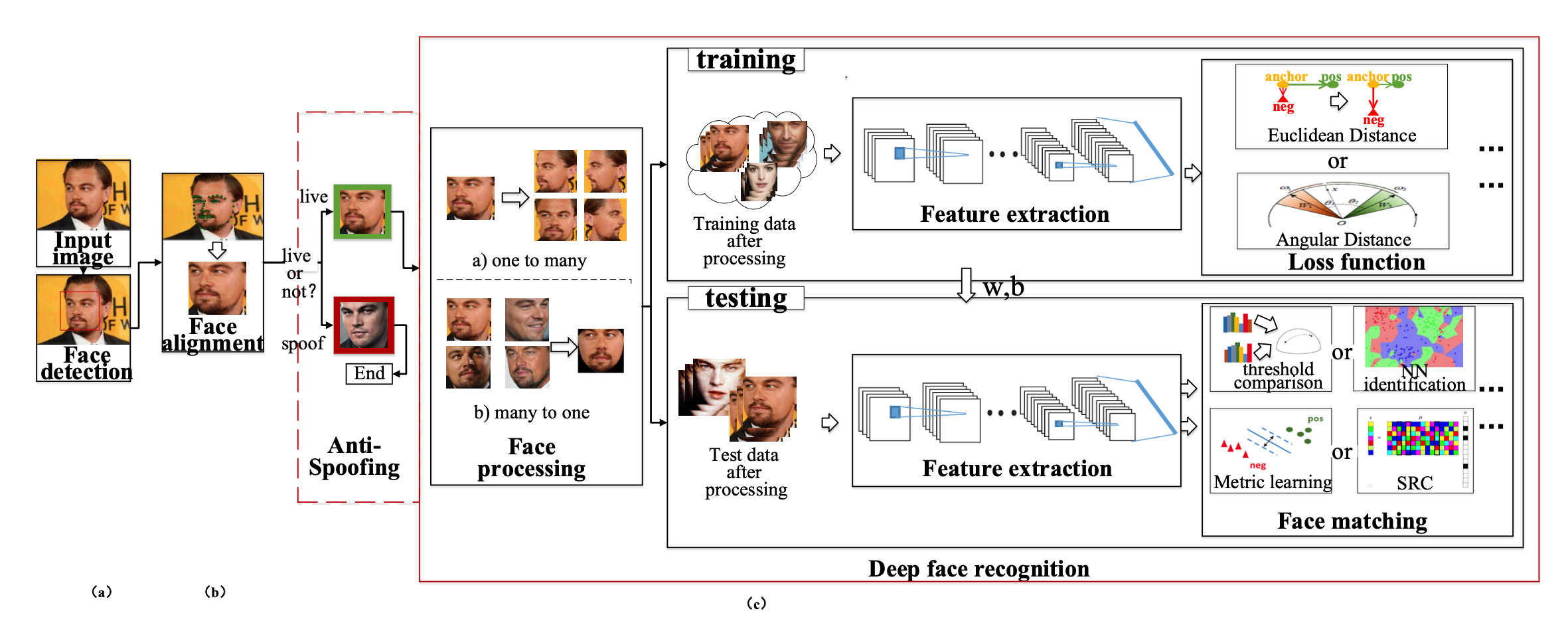
简介 一个完整的人脸识别系统包含以下几个模块 Face Detection: 人脸检测 Face Alignment:基于人脸关键点坐标对齐到正则坐标系下坐标 Face Recognition:基于对齐人脸进行识别 人脸识别的算法流程 人脸的识别流程:面部姿态处理(处理姿态,亮度,表情,遮挡),特征提取,人脸比对。 面部处理 face processing 这部分主要对姿态(主要)、亮度、表情、遮挡进行处理,可提升FR模型性能 主要包含两种处理方式: 1. "Onetomany Augmentation": 从单个图像生成不同姿态的图像,使模型学习到姿态不变性的表示 1. "Manytoone Normalization": 从多个不同姿态的图像中恢复人脸图像的标准视图 特征提取 Backb...