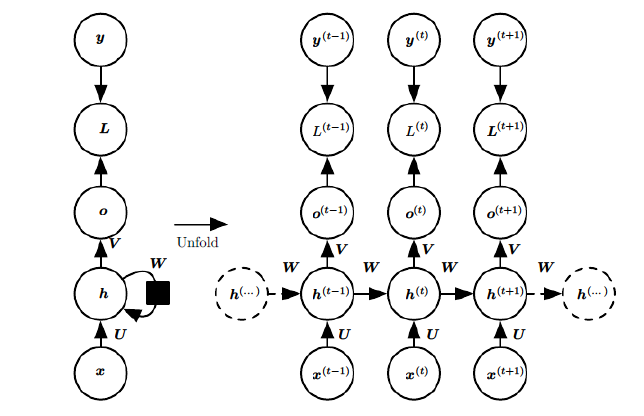
RNN 概述 在前面讲到的DNN和CNN中,训练样本的输入和输出是比较的确定的。但是有一类问题DNN和CNN不好解决,就是训练样本输入是连续的序列,且序列的长短不一,比如基于时间的序列:一段段连续的语音,一段段连续的手写文字。这些序列比较长,且长度不一,比较难直接的拆分成一个个独立的样本来通过DNN/CNN进行训练。 而对于这类问题,RNN则比较的擅长。那么RNN是怎么做到的呢?RNN假设我们的样本是基于序列的。比如是从序列索引1到序列索引 τ 。对于这其中的任意序列索引号 t ,它对应的输入是对应的样本序列中的 x(t) 。而模型在序列索引号 t 位置的隐藏状态 h(t) ,则由 x(t) 和在 t−1 位置的隐藏状态 h(t−1) 共同决定。在任意序列索引号 t ,我们也有对应的模型预测...
Large Model
2026-01-11

梯度检查点(Gradient Checkpointing) 大模型的参数量巨大,即使将batch_size设置为1并使用梯度累积的方式更新,也仍然会OOM。原因是通常在计算梯度时,我们需要将所有前向传播时的激活值保存下来,这消耗大量显存。 还有另外一种延迟计算的思路,丢掉前向传播时的激活值,在计算梯度时需要哪部分的激活值就重新计算哪部分的激活值,这样做倒是解决了显存不足的问题,但加大了计算量同时也拖慢了训练。 梯度检查点(Gradient Checkpointing)在上述两种方式之间取了一个平衡,这种方法采用了一种策略选择了计算图上的一部分激活值保存下来,其余部分丢弃,这样被丢弃的那一部分激活值需要在计算梯度时重新计算。 下面这个动图展示了一种简单策略:前向传播过程中计算节点的激活值并保存...
Large Model
2026-01-11
简介 基于lmmsengine中的训练时对数据packing操作以及use_rmpad消除了所有padding计算的逻辑 Packing 总体逻辑基于packing_length 将不同的数据填充到一个sequence中,具体来说 在Datsset中, 如下代码所示,将不同的数据append到buffer列表中 [代码] 在 Collator 组合成batch的形式传入到模型的输入, 这里还是将数据padding [代码] rmpad 项目中,是以 monkey patch的形式(也就是打热补丁) 替换rmpad操作的,如下代码所示,主要就是替换模型中的forward操作 [代码] Qwen3VLModel.forward 显式调用了 _unpad_input。它计算了非 padding 元...
NLP
2026-01-11

取代RNN——Transformer 在介绍Transformer前我们来回顾一下RNN的结构 对RNN有一定了解的话,一定会知道,RNN有两个很明显的问题 效率问题:需要逐个词进行处理,后一个词要等到前一个词的隐状态输出以后才能开始处理 如果传递距离过长还会有梯度消失、梯度爆炸和遗忘问题 为了缓解传递间的梯度和遗忘问题,设计了各种各样的RNN cell,最著名的两个就是LSTM和GRU了 LSTM (Long Short Term Memory) GRU (Gated Recurrent Unit) 但是,引用网上一个博主的比喻,这么做就像是在给马车换车轮,为什么不直接换成汽车呢? 于是就有了Transformer。Transformer 是Google Brain 2017的提出的一篇工...
Large Model
2026-01-11

引言与背景 FlashAttention的关键创新在于使用类似于在线Softmax的思想来对自注意力计算进行分块(tiling),从而能够融合整个多头注意力层的计算,而无需访问GPU全局内存来存储中间的logits和注意力分数 在深度学习中,Transformer模型的自注意力机制是计算密集型操作。传统实现需要在GPU全局内存中存储大量中间结果,这导致: 内存瓶颈:中间矩阵占用大量显存 I/O开销:频繁的全局内存访问降低效率 扩展性限制:难以处理超长序列 FlashAttention通过算法创新解决了这些问题。 SelfAtention 自注意力机制的计算可以总结为(为简化说明,忽略头数和批次维度,也省略注意力掩码和缩放因子 [Math] ): [公式] 其中: Q, K, V, O 都是形...
Large Model
2026-01-11

模型概述 KimiVL 是一个高效的开源混合专家视觉语言模型(VLM),它提供先进的多模态推理、长上下文理解和强大的代理能力,同时在语言解码器中仅激活 2.8B 参数(KimiVLA3B)。该模型在多种挑战性任务中表现出色,包括一般用途的视觉语言理解、多轮代理任务、大学水平的图像和视频理解、OCR、数学推理和多图像理解等. 模型架构 KimiVL 的架构由三个主要部分组成: MoE语言模型 Moonlight MoE language model with only 2.8B activated (16B total) parameters 视觉模型 400M nativeresolution MoonViT vision encoder. MLP Projector MoonViT: 原生...
Large Model
2026-01-11

UITARS 简介 UITARS(User Interface Task Automation and Reasoning System)是由字节跳动(ByteDance)研发的原生 GUI 智能体模型: 输入方式:仅使用屏幕截图作为视觉输入 交互方式:执行类人操作(键盘输入、鼠标点击、拖拽等) 模型特性:端到端的原生智能体模型,无需复杂的中间件或框架 传统 GUI 智能体的开发往往依赖于文本信息,例如 HTML 结构和可访问性树。虽然这些方法取得了一些进展,但它们也存在一些局限性: 平台不一致性:不同平台的 GUI 结构差异很大,导致智能体难以跨平台通用。 信息冗余:文本信息往往过于冗长,增加了模型的处理负担。 访问限制:获取系统底层的文本信息通常需要较高的权限,限制了应用的范围。 模块化...
Generative Model
2026-01-11

给定一个包含 n 维数据 x 的数据集 D , 简单起见,假设数据 [Math] . 由于真正对联合分布建模的时候, x,y 都是随机变量,故而只需讨论 p(X)=p(x_1,...,x_n) 即可,毕竟只需要令 x_n=y 即可。 给定一个具体的任务,如MNIST中的手写数字二值图分类,从Generative的角度进行Represent,并在Inference中Learning. 下面先介绍: 描述如何对这个MINST任务建模 p(X,Y) (Representation) 对MNIST任务建模 对于一张pixel为 [Math] 大小的图片,令 x_1 表示第一个pixel的随机变量, [Math] ,需明确: 任务目标:学习一个模型分布 [Math] ,使采样时 [Math] , x ...
Large Model
2026-01-11

背景:大模型 vs. GPU Memory 大模型最大的特点是模型参数多,训练时需要很大的GPU显存。举个例子,帮助大家的理解:对于一个常见的7B规模参数的大模型(如LLaMA-2 7B),基于16-bit混合精度训练时,在仅考虑模型参数、梯度、优化器情况下,显存占用就有112GB,显然目前A100、H100这样主流的显卡单张是放不下的,更别提国内中小厂喜欢用的A6000/5000、甚至消费级显卡。 上面的例子中,参数占GPU 显存近 14GB(每个参数2字节)。再考虑到训练时 梯度的存储占14GB(每个参数对应一个梯度,也是2字节)、优化器Optimizer假设是用目前主流的AdamW则是8...
NLP
2026-01-11

概述 SSM的概念由来已久,但这里我们特指深度学习中的SSM,一般认为其开篇之作是2021年的 S4,不算太老,而SSM最新最火的变体大概是Mamba。当然,当我们谈到SSM时,也可能泛指一切线性RNN模型,这样RWKV、RetNet还有此前LRU都可以归入此类。不少SSM变体致力于成为Transformer的竞争者,尽管笔者并不认为有完全替代的可能性,但SSM本身优雅的数学性质也值得学习一番。 尽管我们说SSM起源于S4,但在S4之前,SSM有一篇非常强大的奠基之作《HiPPO: Recurrent Memory with Optimal Polynomial Projections》(简称HiPPO),所以本文从HiPPO开始说起。 另外值得一提的是,SSM代表作HiPPO、S4、Mam...
Large Model
2026-01-11

Chameleon:生成理解统一模型的开山之作 🔖 https://arxiv.org/pdf/2405.09818 Chameleon 是一个既能做图像理解,又可以做图像或者文本生成任务的,从头训练的 Transformer 模型。完整记录了为实现 mixedmodal 模型的架构设计,稳定训练方法,对齐的配方。并在一系列全面的任务上进行评估:有纯文本任务,也有图像文本任务 (视觉问答、图像字幕),也有图像生成任务,还有混合模态的生产任务。 如下图所示,Chameleon 将所有模态数据 (图像、文本和代码) 都表示为离散 token,并使用统一的 Transformer 架构。训练数据是交错混合模态数据 ∼10T token,以端到端的方式从头开始训练。文本 token 用绿色表示,图像...