Machine Learning
2026-04-15
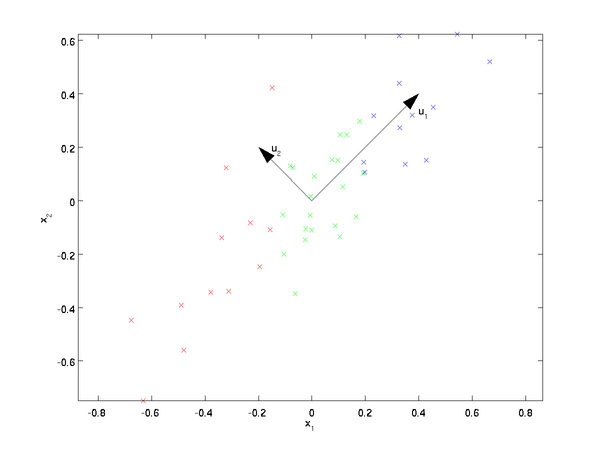
PCA PCA的思想 PCA顾名思义,就是找出数据里最主要的方面,用数据里最主要的方面来代替原始数据。具体的,假如我们的数据集是 \(n\) 维的,共有 \(m\) 个数据 \((𝑥(1),𝑥(2),...,𝑥(𝑚))\) 。我们希望将这 \(m\) 个数据的维度从 \(n\) 维降到 \(n'\) 维,希望这 \(m\) 个 \(n'\) 维的数据集尽可能的代表原始数据集。我们知道数据从 \(n\) 维降到 \(n'\) 维肯定会有损失,但是我们希望损失尽可能的小。那么如何让这 \(n'\) 维的数据尽可能表示原来的数据呢? 我们先看看最简单的情况,也就是 \(n=2\) , \(n'=1\) ,也就是将数据从二维降维到一维。数据如下图。我们希望找到某一个维度方向,它可以代表这两个维度的数据。图中列了两个向量方向, \(u_1\) 和 \(𝑢_2\) ,那么哪个向量可以更好的代表原始数据集呢?从直观上也可以看出, \(𝑢_1\) 比 \(𝑢_2\) 好。 为什么 \(𝑢_1\) 比 \(𝑢_2\)...







