Machine Learning
2026-01-11
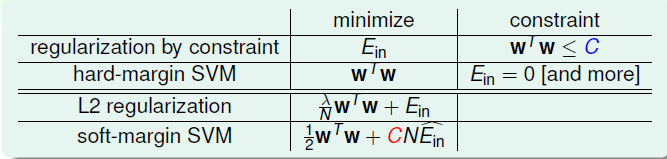
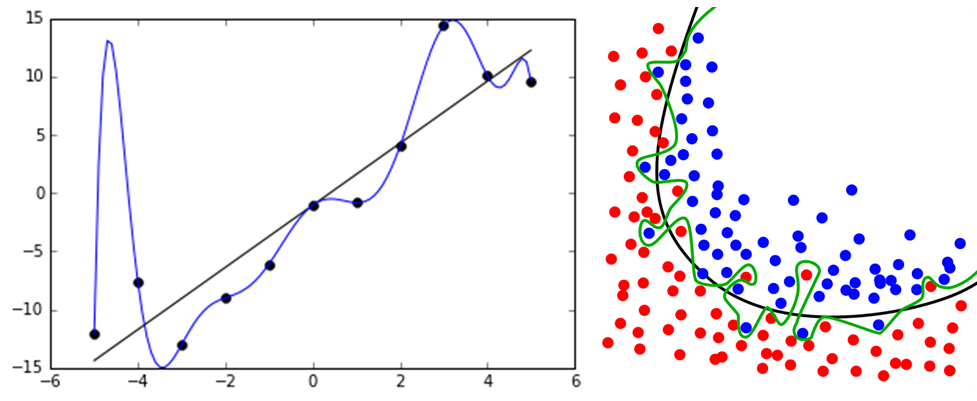
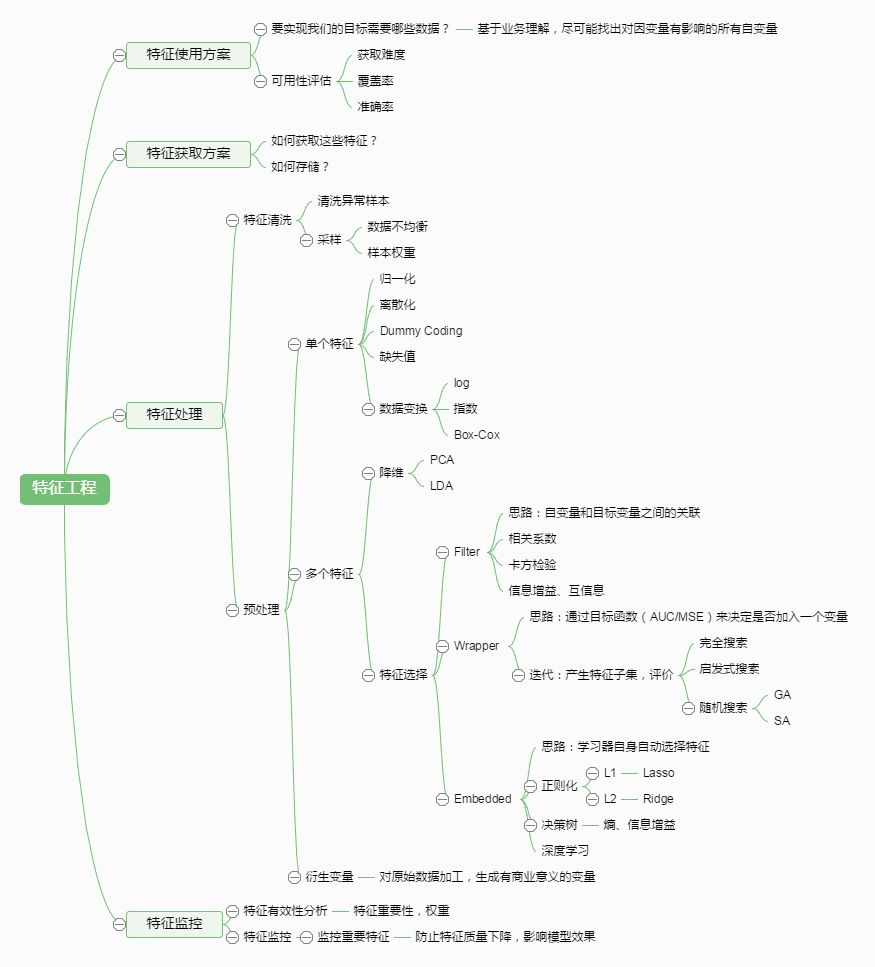
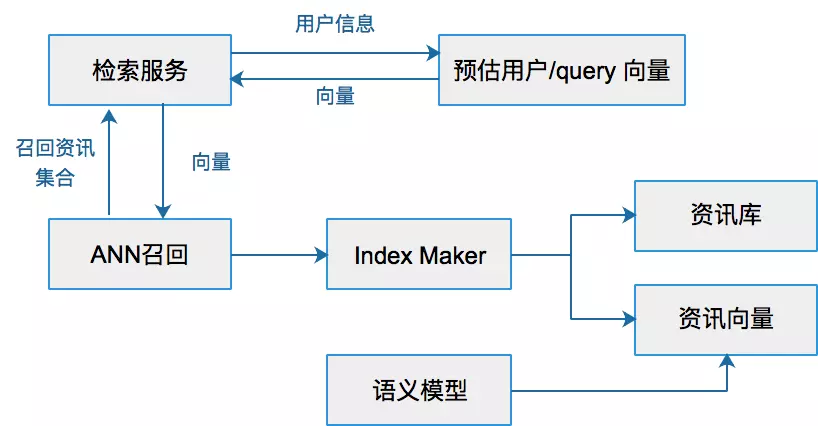
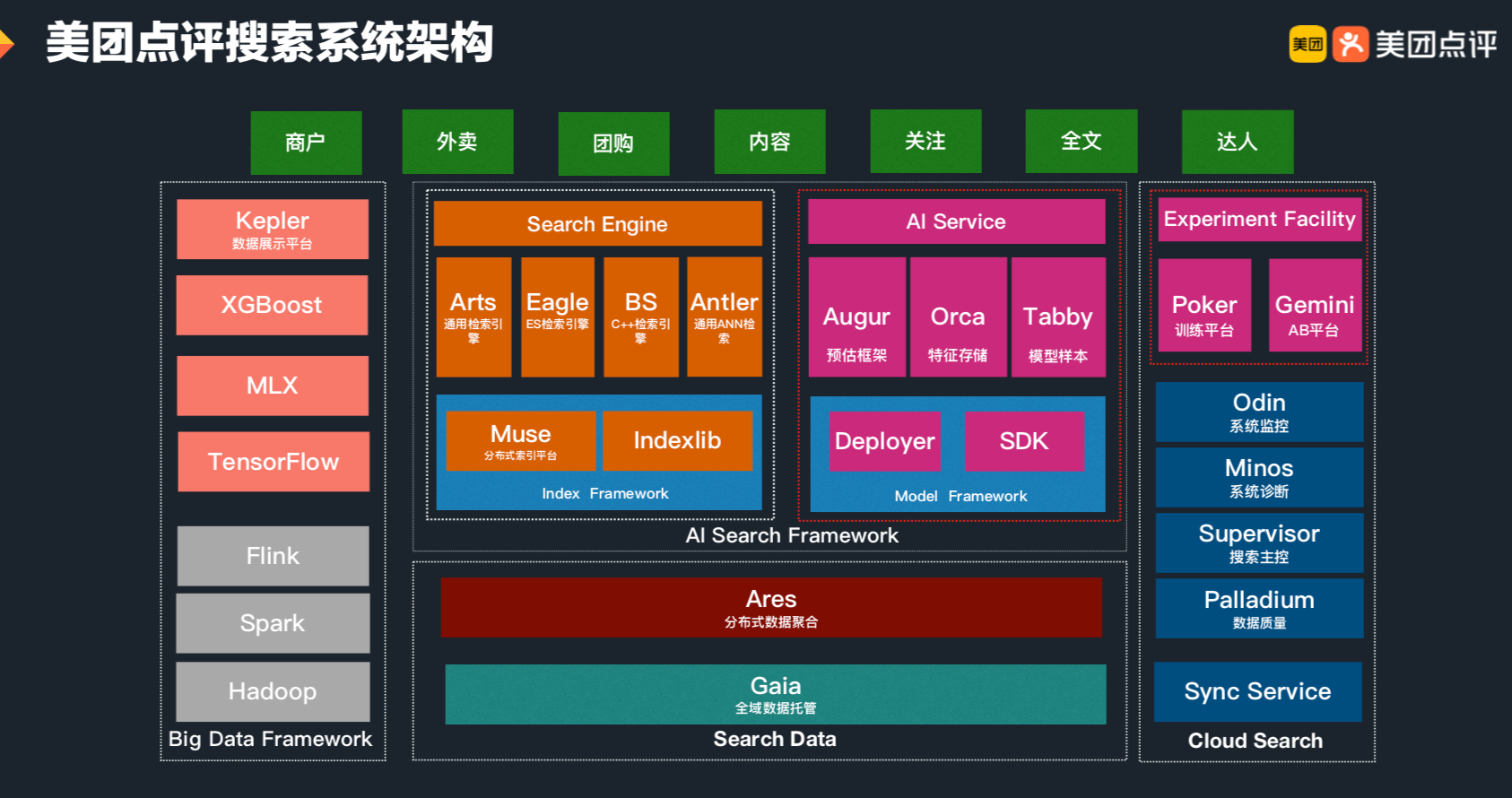
Kernel Logistic Regression 介绍如何将Kernel Trick引入到Logistic Regression,以及LR与SVM的结合 SVM与正则化 首先回顾SoftMargin SVM的原始问题: [公式] 其中 ξ_n 是训练数据违反边界的多少,没有违反的话, ξ_n=0 ,反之 ξ_n0 ,换句话说,目标函数的第二项就可以表示模型的损失。现在换一种方式来写,将二者结合起来: ξ_n=max(1−y_n(w^Tz^n+b),0) ,这一个等式就代表了上面的约束条件,这样上述问题,就与下面的无约束问题等价 [公式] 这种形式与之前的L2 正则项很类似: [公式] 在L2中,通过最小化 E_{in} 的同时控制 w 的大小,防止模型过度复杂。从正则化的角度来看的话,S...