Large Model
2026-03-06
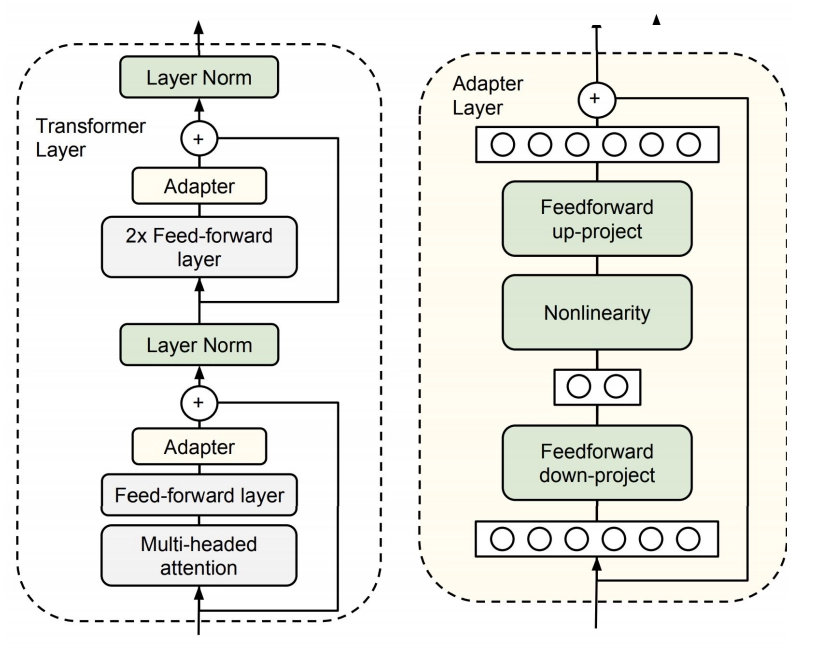
Adapter tuning Adapter Tuning试图在Transformer Layer的Self-Attetion+FFN之后插入一个先降维再升维的MLP(以及一层残差和LayerNormalization)来学习模型微调的知识。 在预训练模型每一层(或某些层)中添加Adapter模块(如上图左侧结构所示),微调时冻结预训练模型主体,由Adapter模块学习特定下游任务的知识。每个Adapter模块由两个前馈子层组成,第一个前馈子层将Transformer块的输出作为输入,将原始输入维度 \(d\) 投影到 \(m\) ,通过控制 \(m\) 的大小来限制Adapter模块的参数量,通常情况下 \(m\ll d\) 。在输出阶段,通过第二个前馈子层还原输入维度,将 \(m\) 重新投影到 \(d\)...