Machine Learning
2026-03-18
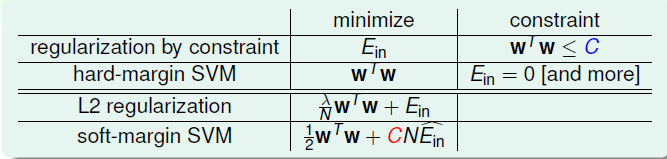
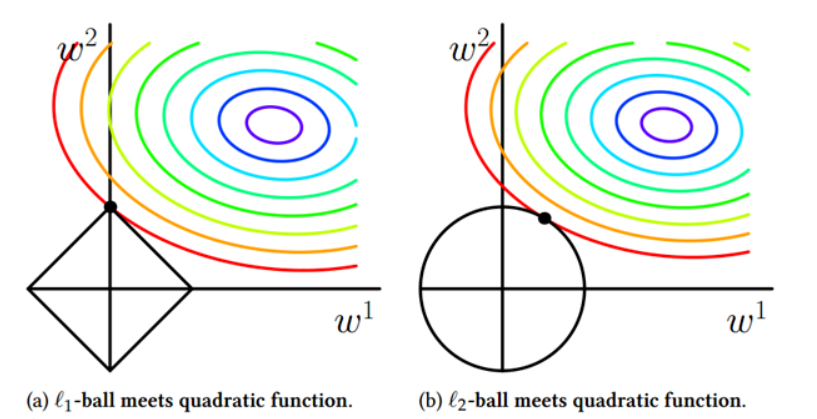
介绍如何将Kernel Trick引入到Logistic Regression,以及LR与SVM的结合 SVM与正则化 首先回顾Soft-Margin SVM的原始问题: \[\begin{aligned}\min\limits_{b,\mathbf{w}, \xi} \quad &\frac{1}{2} \mathbf{w}^T\mathbf{w} + C \cdot \sum\limits_{n=1}^{N}\xi_n \\ s.t. \quad & y_n(\mathbf{w}^T\mathbf{z}^n+b) \geq 1-\xi_n, for \ all\ n \end{aligned}\] 其中 \(ξ_n\) 是训练数据违反边界的多少,没有违反的话, \(ξ_n=0\) ,反之 \(ξ_n>0\) ,换句话说,目标函数的第二项就可以表示模型的损失。现在换一种方式来写,将二者结合起来: \(ξ_n=max(1−y_n(w^Tz^n+b),0)\) ,这一个等式就代表了上面的约束条件,这样上述问题,就与下面的无约束问题等价 \[\begin{aligned} &...