数组&链表&字符串 双指针 滑动窗口 哈希表 哈希表 栈&队列 单调队列 树与堆 图 数学 Math
Large Model
2026-01-20
这是一篇尝试改变LLM「范式」的文章:当前主流的LLM架构都是「自回归」的,通俗地理解就是必须「从左到右依次生成」。这篇文章挑战了这一范式,探索扩散模型在 LLMs 上的可行性,通过 随机掩码 - 预测 的逆向思维,让模型学会「全局思考」。 论文: [2502.09992] Large Language Diffusion Models 背景 主流大语言模型架构:自回归模型 (Autoregressive LLMs) 过去几年, 自回归模型(Autoregressive Models, ARMs)一直是大语言模型(LLM)的主流架构。典型的自回归语言模型以Transformer解码器为基础,按照从左到右 的顺序依次预测下一个词元(token)。 形式化地,自回归模型将一个长度为 \(N\) 的文本序列 \(X=(x_1, x_2, ..., x_N)\) 的概率分解为各位置的条件概率连乘积: \[P_{\theta}(x_1, x_2, \dots, x_N) = \prod_{i=1}^{N} P_{\theta}(x_i \mid x_1, x_2, \dots,...
Large Model
2026-01-20

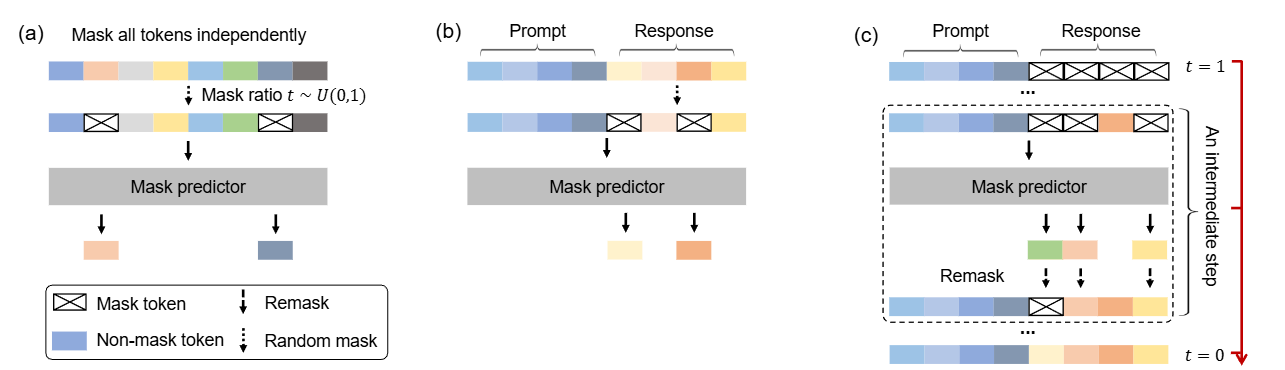
引言 Diffusion模型近年来在图像生成这一连续域任务中取得了显著成果,展现出强大的生成能力。然而,在文本生成这一离散域任务中整体效果仍不尽如人意,未能在该领域引起广泛关注。 去年,一篇研究离散扩散模型在文本生成的文章《Discrete Diffusion Modeling by Estimating the Ratios of the Data Distribution》获得ICML 2024的Best Paper,引发了学术界的广泛兴趣,也激发了新一轮的研究热潮。随后在2025年,越来越多高校和企业也开始积极探索基于Diffusion的文本生成方法。其中,近期备受关注的Block Diffusion也成功入选ICLR oral,进一步推动了该方向的发展。...
Large Model
2026-01-15

🔖 https://www.deepseek.com/ DeepSeek LLM 代码地址: https://github.com/deepseek-ai/DeepSeek-LLM 背景 量化巨头幻方探索AGI(通用人工智能)新组织“深度求索”在成立半年后,发布的第一代大模型,免费商用,完全开源。作为一家隐形的AI巨头,幻方拥有1万枚英伟达A100芯片,有手撸的HAI-LLM训练框架HAI-LLM:高效且轻量的大模型训练工具。 概述 DeepSeek LLMs,这是一系列在2万亿标记的英语和中文大型数据集上从头开始训练的开源模型 在本文中,深入解释了超参数选择、Scaling Laws以及做过的各种微调尝试。校准了先前工作中的Scaling Laws,并提出了新的最优模型/数据扩展-缩放分配策略。此外,还提出了一种方法,使用给定的计算预算来预测近似的batch-size和learning-rate。进一步得出结论,Scaling Laws与数据质量有关,这可能是不同工作中不同扩展行为的原因。在Scaling Laws的指导下,使用最佳超参数进行预训练,并进行全面评估。...
Large Model
2026-01-15

简介 后训练(post-training)已成为完整训练流程中的重要组成部分。相比于预训练,后训练需要的计算资源相对较少,但能够: 提高推理任务的准确性 使模型与社会价值观保持一致 适应用户偏好 OpenAI 的 o1 系列模型首次引入了通过增加思维链(Chain-of-Thought)推理过程长度来实现推理时间,扩展这种方法在数学、编程和科学推理等各种推理任务上取得了显著改进 研究界已探索多种方法来提高模型的推理能力:比如 基于过程的奖励模型 (Process-based Reward Models) 强化学习 (Reinforcement Learning), 代表工作:InstructGPT, 以及 搜索算法( 蒙特卡洛树搜索(Monte Carlo Tree Search)、束搜索(Beam Search))。然而,这些方法尚未达到与 OpenAI o1 系列模型相当的通用推理性能。 DeepSeek-R1-Zero 本文首先探索使用纯强化学习(RL)来提高语言模型的推理能力,重点关注: 探索 LLM 在没有任何监督数据的情况下,通过纯 RL 过程的自我进化来发展推理能力...
Large Model
2026-01-15

简介 24年12月,研究团队开发了 DeepSeek-V3,这是一个基于 MoE 架构的大模型,总参数量达到 671B,其中每个 token 会激活 37B 个参数。 基于提升性能和降低成本的双重目标,在架构设计方面,DeepSeek-V3 采用了 MLA 来确保推理效率,并使用 DeepSeekMoE 来实现经济高效的训练。这两种架构在 DeepSeek-V2 中已经得到验证,证实了它们能够在保持模型性能的同时实现高效的训练和推理。 除了延续这些基础架构外,研究团队还引入了两项创新策略来进一步提升模型性能。 首先,DeepSeek-V3 首创了 无辅助损失的负载均衡 策略(auxiliary-loss-free strategy for load balancing),有效降低了负载均衡对模型性能的负面影响。另外,DeepSeek-V3 采用了 多 token 预测训练目标, 这种方法在评估基准测试中展现出了显著的性能提升。 为了提高训练效率,该研究采用了 FP8 混合精度训练技术...

简介 生成树(spanning tree) 在图论中,无向图 G=(V,E) 的生成树(spanning tree)是具有G的全部顶点,但边数最少的联通子图。假设G中一共有n个顶点,一颗生成树满足下列条件: (1)n个顶点; (2)n1条边; (3)n个顶点联通; (4)一个图的生成树可能有多个。最小生成树(minimum spanning tree, MST)/最小生成森林:联通加权无向图中边缘权重加和最小的生成树。给定无向图 G=(V,E) , (u,v) 代表顶点 u 与顶点 v 的边, w(u,v) 代表此边的权重,若存在生成树T使得: [公式] 最小,则 T 为 G 的最小生成树。对于非连通无向图来说,它的每一连通分量同样有最小生成树,它们的并被称为最小生成森林。最小生成树除了继承...
Algorithm
2026-01-11
给一个无向图,判断其是否为一棵树。如果是树的话,所有的节点必须是连接的,也就是说必须是连通图,而且不能有环,所以就变成了验证是否是连通图和是否含有环。 [代码]
Algorithm
2026-01-11
题目 中位数是有序列表中间的数。如果列表长度是偶数,中位数则是中间两个数的平均值。 例如, [2,3,4] 的中位数是 3 [2,3] 的中位数是 (2 + 3) / 2 = 2.5 设计一个支持以下两种操作的数据结构: void addNum(int num) 从数据流中添加一个整数到数据结构中。 double findMedian() 返回目前所有元素的中位数。 示例: addNum(1) addNum(2) findMedian() 1.5 addNum(3) findMedian() 2 题解 维护两个堆:大顶堆和小顶堆。并且需满足如下条件: 小顶堆的所有元素都大于等于大顶堆的所有元素。 大顶堆中的元素数量大于等于小顶堆中的元素数量。 大顶堆对应排序后的列表的左半部分;小顶堆对应排序...
Algorithm
2026-01-11
[代码] 自己实现小顶堆 [代码] 变态的需求来了:给出N长的序列,求出BtmK小的元素,即使用大顶堆。 概括一种最简单的: 将push(e)改为push(e)、pop(e)改为pop(e)。 也就是说,在存入堆、从堆中取出的时候,都用相反数,而其他逻辑与TopK完全相同,看代码: [代码] 自己实现大顶堆 [代码]
二叉树结构 [代码] 递归 时间复杂度:O(n),n为节点数,访问每个节点恰好一次。 空间复杂度:空间复杂度:O(h),h为树的高度。最坏情况下需要空间O(n),平均情况为O(logn) 递归1: 二叉树遍历最易理解和实现版本 [代码] 递归2: 通用模板 可以适应不同的题目,添加参数、增加返回条件、修改进入递归条件、自定义返回值 [代码] 迭代 时间复杂度:O(n),n为节点数,访问每个节点恰好一次。 空间复杂度:O(h),h为树的高度。取决于树的结构,最坏情况存储整棵树,即O(n) 迭代1: 前序遍历最常用模板(后序同样可以用) [代码] 迭代2: 前、中、后序遍历通用模板(只需一个栈的空间) [代码] 迭代3:标记法迭代(需要双倍的空间来存储访问状态) 前、中、后、层序通用模板,只需改...
3D Model
2026-01-11

三维深度学习简介 多视角(multiview):通过多视角二维图片组合为三维物体,此方法将传统CNN应用于多张二维视角的图片,特征被view pooling procedure聚合起来形成三维物体; 体素(volumetric):通过将物体表现为空间中的体素进行类似于二维的三维卷积(例如,卷积核大小为5x5x5),是规律化的并且易于类比二维的,但同时因为多了一个维度出来,时间和空间复杂度都非常高,目前已经不是主流的方法了; 点云(point clouds):直接将三维点云抛入网络进行训练,数据量小。主要任务有分类、分割以及大场景下语义分割; 非欧式(manifold,graph):在流形或图的结构上进行卷积,三维点云可以表现为mesh结构,可以通过点对之间临接关系表现为图的结构。 点云的特性...