堆和优先队列的关系 这是一个非常经典且核心的计算机科学概念问题。一言以蔽之: 优先队列(Priority Queue)是逻辑接口(ADT),而堆(Heap)是实现这个接口最高效的物理数据结构。 它们的关系可以类比为 “接口(Interface)” 与 “实现类(Implementation)” 的关系,或者 “汽车(功能)”与 “发动机(核心组件)” 的关系。 优先队列 (Priority Queue) —— 逻辑层 (ADT) 定义 :它是一种 抽象数据类型 (Abstract Data Type, ADT) 。它定义了数据的 行为 ,而不是数据的存储方式。 规则 :普通的队列是“先进先出”(FIFO),而优先队列是 “优先级最高的先出” 。 核心操作 : insert(item, priority) : 插入一个带优先级的元素。 deleteMax() 或 deleteMin() : 取出并删除优先级最高(或最低)的元素。 peek() : 查看优先级最高的元素。 堆 (Heap) —— 物理层 (Data Structure) 定义 :它是一种具体的 数据结构 。通常指 二叉堆...
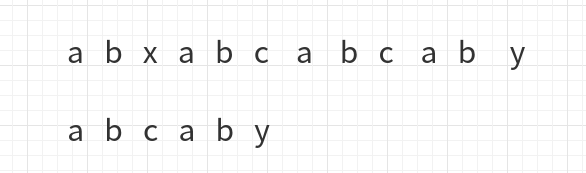
kmp算法用于字符串的模式匹配,也就是找到模式字符串在目标字符串的第一次出现的位置比如 abababc 那么 bab 在其位置1处, bc 在其位置5处,我们首先想到的最简单的办法就是蛮力的一个字符一个字符的匹配,但那样的时间复杂度会是 \(O(m*n)\) 。kmp算法保证了时间复杂度为 \(O(m+n)\) 。 基本原理 举个例子: 发现 x 与 c 不同后,进行移动 a 与 x 不同,再次移动 此时比较到了 c 与 y , 于是下一步移动成了下面这样 这一次的移动与前两次的移动不同,之前每次比较到上面长字符串的字符位置后,直接把模式字符串的首字符与它对齐,这次并没有,原因是这次移动之前, y 与 c 对齐,但是 y 前边的 ab 是与自己的前缀 ab 一样,于是 ab 并不用再比较,直接从第三个位置开始比较,如图: 所以说 kmp算法对于这种情况就直接使用当前比较字符之前的最长相同的前后缀,然后将前缀与上面的长字符串对齐,继续比较后面的字符串 。 这里kmp算法中的一个重要点就来了,如何找到 模式字符串中每位字符之前的最长相同前后缀呢 这里继续用一个例子举例: 下面的数字记录...

160. 相交链表 题目 给你两个单链表的头节点 headA 和 headB ,请你找出并返回两个单链表相交的起始节点。如果两个链表不存在相交节点,返回 null 。 图示两个链表在节点 c1 开始相交 : 题目数据 保证 整个链式结构中不存在环。 注意 ,函数返回结果后,链表必须 保持其原始结构 。 自定义评测: 评测系统 的输入如下(你设计的程序 不适用 此输入): intersectVal - 相交的起始节点的值。如果不存在相交节点,这一值为 0 listA - 第一个链表 listB - 第二个链表 skipA - 在 listA 中(从头节点开始)跳到交叉节点的节点数 skipB - 在 listB 中(从头节点开始)跳到交叉节点的节点数 评测系统将根据这些输入创建链式数据结构,并将两个头节点 headA 和 headB 传递给你的程序。如果程序能够正确返回相交节点,那么你的解决方案将被 视作正确答案 。 示例 1: 输入:intersectVal = 8, listA = [4,1,8,4,5], listB = [5,6,1,8,4,5], skipA = 2,...
线性结构与技巧 基础容器 数组 (Array) 链表 (Linked List) 字符串 (String) KMP算法 核心技巧 双指针 滑动窗口 二分查找 栈与队列 栈 & 队列 (Stack & Queue) 单调队列 树与图论 树与堆 (Tree & Heap) 树的遍历 二叉树 堆(大顶堆&小顶堆) 优先队列 图 (Graph) 搜索(BFS/DFS) 最小生成树 核心算法思想 动态规划 (DP) 基础 DP 背包问题 排序 基础排序算法 排序算法 数据处理 哈希表 Math

236. 二叉树的最近公共祖先 给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。 百 度百科中最近公共祖先的定义为:“对于有根树 \(T\) 的两个节点 \(p\) 、 \(q\) ,最近公共祖先表示为一个节点 \(x\) ,满足 \(x\) 是 \(p\) 、 \(q \) 的祖先且 \(x\) 的深度尽可能大( 一个节点也可以是它自己的祖先 )。” 示例 1: 输入:root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 1
输出:3
解释:节点 5 和节点 1 的最近公共祖先是节点 3 。 示例 2: 输入:root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 4
输出:5
解释:节点 5 和节点 4 的最近公共祖先是节点 5 。因为根据定义最近公共祖先节点可以为节点本身。 示例 3: 输入:root = [1,2], p = 1, q = 2
输出:1 提示: 树中节点数目在范围 [2, 10 5 ] 内。 -10 9 <= Node.val <= 10 9 所有 Node.val...
二叉树结构 class TreeNode:
def __init__(self, x):
self.val = x
self.left = None
self.right = None 递归 时间复杂度: \(O(n)\) , \(n\) 为节点数,访问每个节点恰好一次。 空间复杂度:空间复杂度: \(O(h)\) , \(h\) 为树的高度。最坏情况下需要空间 \(O(n)\) ,平均情况为 \(O(logn)\) 递归1: 二叉树遍历最易理解和实现版本 class Solution:
def preorderTraversal(self, root: TreeNode) -> List[int]:
if not root:
return []
# 前序递归
return [root.val] + self.preorderTraversal(root.left) + self.preorderTraversal(root.right)
...

48. 旋转图像 题目 给定一个 \(n × n\) 的二维矩阵 matrix 表示一个图像。请你将图像顺时针旋转 90 度。 你必须在 原地 旋转图像,这意味着你需要直接修改输入的二维矩阵。 请不要 使用另一个矩阵来旋转图像。 示例 1: 输入:matrix = [[1,2,3],[4,5,6],[7,8,9]]
输出:[[7,4,1],[8,5,2],[9,6,3]] 示例 2: 输入:matrix = [[5,1,9,11],[2,4,8,10],[13,3,6,7],[15,14,12,16]]
输出:[[15,13,2,5],[14,3,4,1],[12,6,8,9],[16,7,10,11]] 提示: n == matrix.length == matrix[i].length 1 <= n <= 20 -1000 <= matrix[i][j] <= 1000 题解 这是一个经典的矩阵操作问题。要在原地(In-place)将图像顺时针旋转 90 度,我们可以利用矩阵的几何性质。 最直观且易于实现的方法是将...
Generative Model
2026-04-15

背景 本文主要是 《NICE: Non-linear Independent Components Estimation》 一文的介绍和实现。这篇文章也是glow这个模型的基础文章之一,可以说它就是glow的奠基石。 艰难的分布 众所周知,目前主流的生成模型包括VAE和GAN,但事实上除了这两个之外,还有基于flow的模型(flow可以直接翻译为“流”,它的概念我们后面再介绍)。事实上flow的历史和VAE、GAN它们一样悠久,但是flow却鲜为人知。在我看来,大概原因是flow找不到像GAN一样的诸如“造假者-鉴别者”的直观解释吧,因为flow整体偏数学化,加上早期效果没有特别好但计算量又特别大,所以很难让人提起兴趣来。不过现在看来,OpenAI的这个好得让人惊叹的、基于flow的glow模型,估计会让更多的人投入到flow模型的改进中。 glow模型生成的高清人脸 生成模型的本质,就是希望用一个我们知道的概率模型来拟合所给的数据样本, 也就是说,我们得写出一个带参数 \(𝜃\) 的分布 \(q_{\boldsymbol{\theta}}(\boldsymbol{x})\)...
Generative Model
2026-04-15
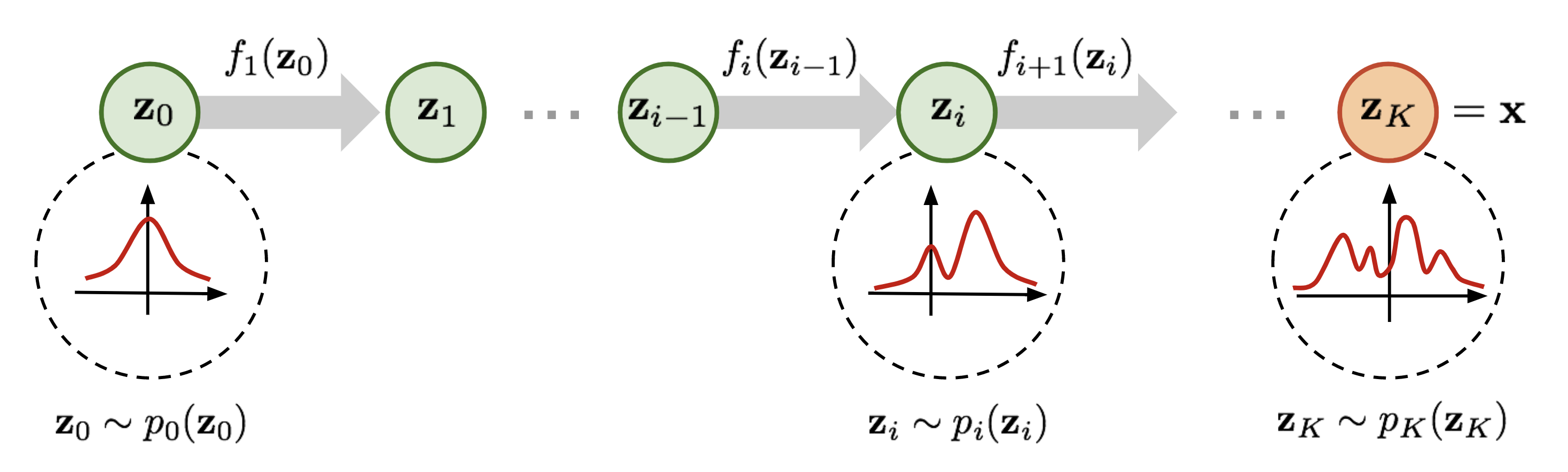
Normalizing flow(标准化流)是一类对概率分布进行建模的工具,它能完成简单的概率分布(例如高斯分布)和任意复杂分布之间的相互转换,经常被用于 data generation、density estimation、inpainting 等任务中,例如 Stability AI 提出的 Stable Diffusion 3 中用到的 rectified flow 就是 normalizing flow 的变体之一。 为了便于理解,在正式开始介绍之前先简要说明一下 normalizing flow 的做法。如上图所示, 为了将一个高斯分布 \(z_0\) 转换为一个复杂的分布 \(z_K\) ,normalizing flow 会对初始的分布 \(z_0\) 进行多次可逆的变换,将其逐渐转换为 \(z_K\) 。由于每一次变换都是可逆的,从 \(z_K\) 出发也能得到高斯分布 \(z_0\) 。这样,我们就实现了复杂分布与高斯分布之间的互相转换,从而能从简单的高斯分布建立任意复杂分布。 对 diffusion models 比较熟悉的读者可能已经发现了,这个过程和...
Generative Model
2026-04-15

1-Rectified Flow 可以认为是 flow matching的ot最优传输形式 Rectified Flow目的是将多对多无约束映射 转变成 一对一有约束映射。 ode会保证路径是“因果”的,也就是避免相交的情况 2-Rectified Flow或者叫Reflow 核心的实际上是加噪过程的样本交点数目降低,交点处模型无法精确学习向量场,交点数少了,模型在每个点预测都更准了,加噪过程是直线,所以能更少步数走到起点(但整体采样过程不是直线) 原本随机采样的DDPM模型中,也隐含了一个确定性的采样过程DDIM,它的连续极限也是一个ODE 。 细想上述过程, 可以发现不管是“DDPM→DDIM”还是“SDE→ODE”,都是从随机采样模型过渡到确定性模型,而如果我们一开始的目标就是ODE,那么该过程未免显得有点“迂回”了 。在本文中,笔者尝试给出ODE扩散模型的直接推导,并揭示了它与雅可比行列式、热传导方程等内容的联系。 Rectified Flow 理论推导 微分方程...
NLP
2026-04-15

取代RNN——Transformer 在介绍Transformer前我们来回顾一下RNN的结构 对RNN有一定了解的话,一定会知道,RNN有两个很明显的问题 效率问题:需要逐个词进行处理,后一个词要等到前一个词的隐状态输出以后才能开始处理 如果传递距离过长还会有梯度消失、梯度爆炸和遗忘问题 为了缓解传递间的梯度和遗忘问题,设计了各种各样的RNN cell,最著名的两个就是LSTM和GRU了 LSTM (Long Short Term Memory) GRU (Gated Recurrent Unit) 但是,引用网上一个博主的比喻,这么做就像是在给马车换车轮,为什么不直接换成汽车呢? 于是就有了 Transformer 。Transformer 是Google Brain 2017的提出的一篇工作,它针对RNN的弱点进行重新设计,解决了RNN效率问题和传递中的缺陷等,在很多问题上都超过了RNN的表现。Transfromer的基本结构如下图所示,...

简介 生成对抗网络 ( Generative Adversarial Network, GAN ) 是由 Goodfellow 于 2014 年提出的一种对抗网络。这个网络框架包含两个部分,一个生成模型 (generative model) 和一个判别模型 (discriminative model)。其中,生成模型可以理解为一个伪造者,试图通过构造假的数据骗过判别模型的甄别;判别模型可以理解为一个警察,尽可能甄别数据是来自于真实样本还是伪造者构造的假数据。两个模型都通过不断的学习提高自己的能力,即生成模型希望生成更真的假数据骗过判别模型,而判别模型希望能学习如何更准确的识别生成模型的假数据。 网络框架 GAN 由两部分构成,一个 生成器 ( Generator ) 和一个 判别器 ( Discriminator )。对于生成器,我们需要学习关于数据 \(x\) 的一个分布 \(p_g\) ,首先定义一个输入数据的先验分布 \(p_z(z)\) ,其次定义一个映射 \(G \left(\boldsymbol{z}; \theta_g\right): \boldsymbol{z}...