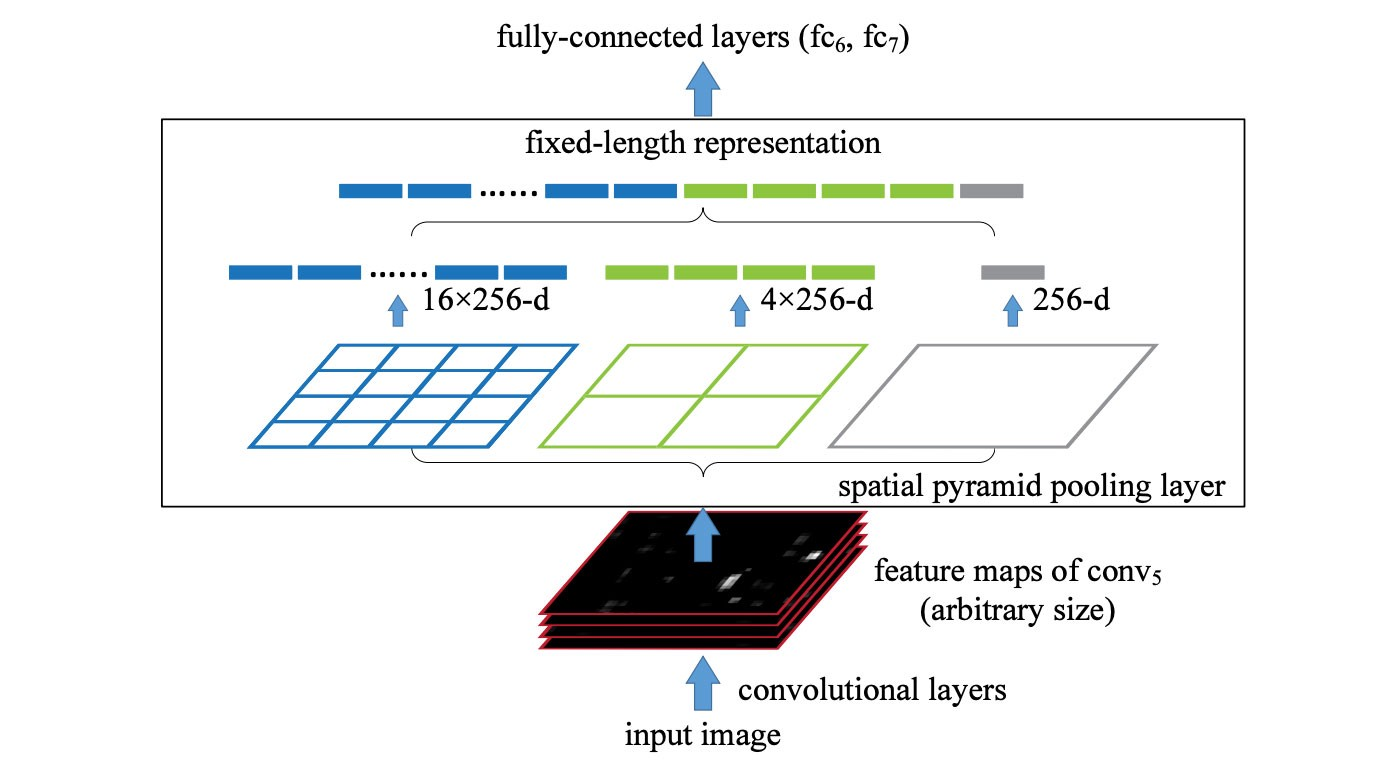
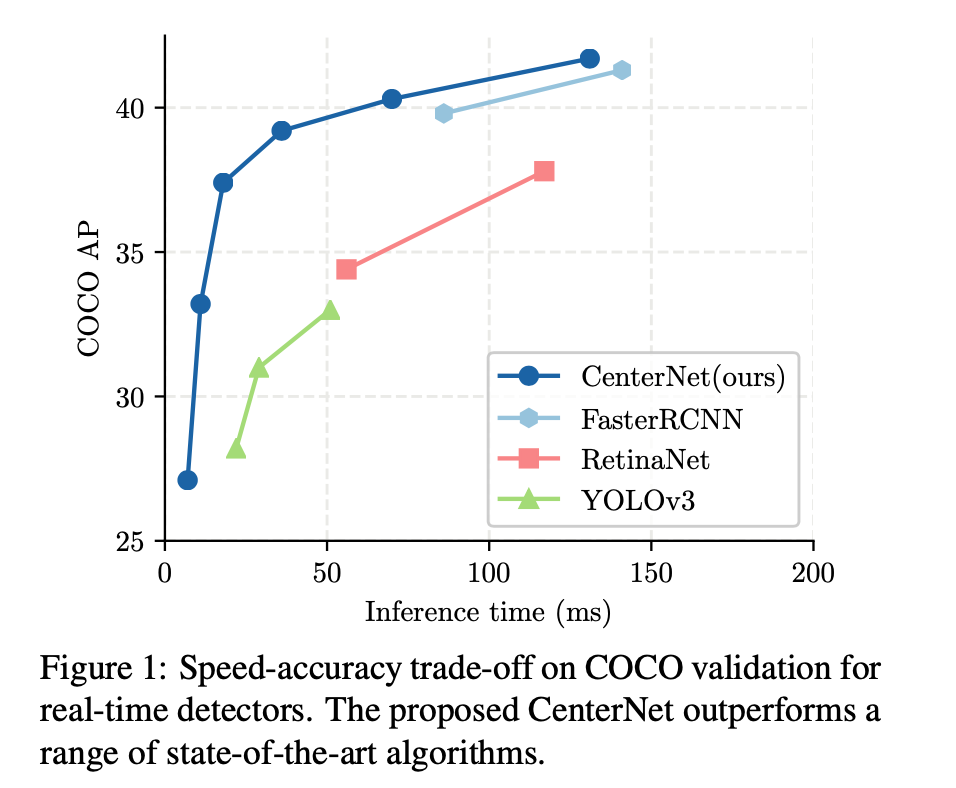
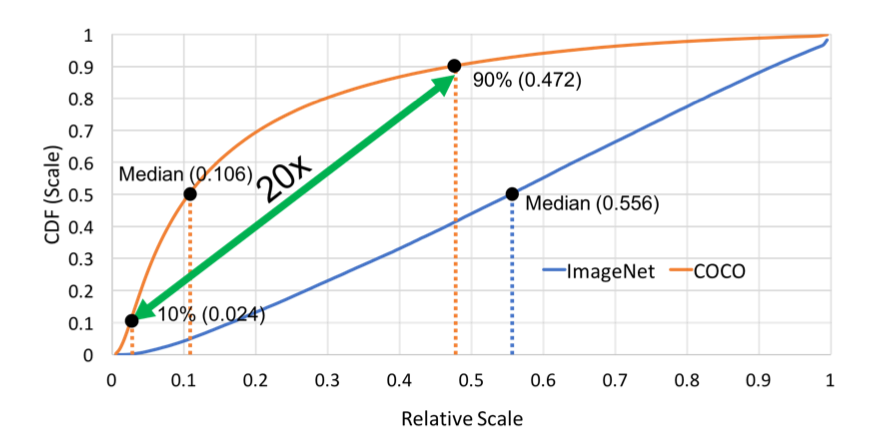
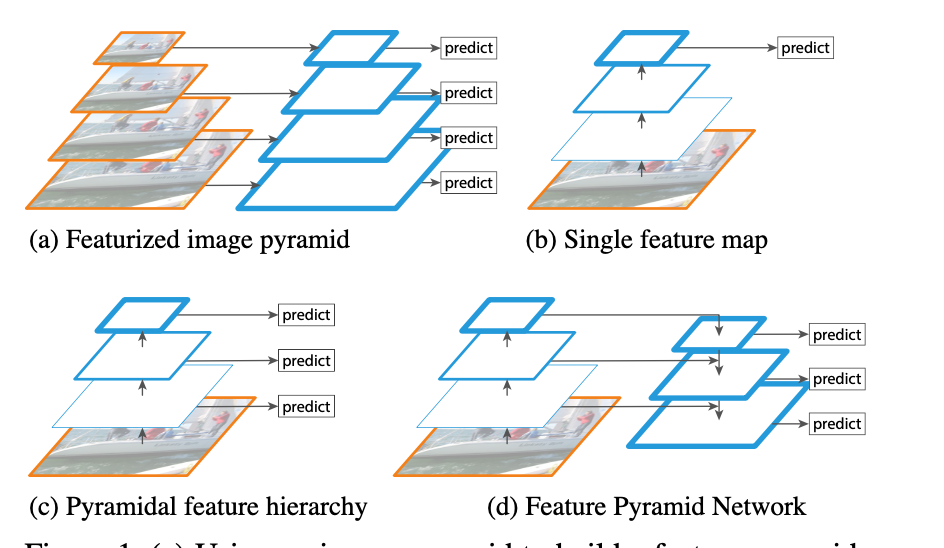
3D Model
2026-01-11

Classification,Detection Classification:给定预先裁剪好的视频片段,预测其所属的行为类别 Detection:视频是未经过裁剪的,需要先进行人的检测where和行为定位(分析行为的始末时间)when,再进行行为的分类what。 通常所说的行为识别更偏向于对时域预先分割好的序列进行行为动作的分类,即 Trimmed Video Action Classification。 TwoStream Twostream convolutional networks 简介 TwoStream CNN网络顾名思义分为两个部分, 1. 空间流处理RGB图像,得到形状信息; 1. 时间流/光流处理光流图像,得到运动信息。 两个流最后经过softmax后,做分类分数的融合,...