
PrefixTuning Paper: 2021.1 Optimizing Continuous Prompts for GenerationGithub:https://github.com/XiangLi1999/PrefixTuningPrompt: Continus Prefix PromptTask & Model:BART(Summarization), GPT2(Table2Text) 最早提出Prompt微调的论文之一,其实是可控文本生成领域的延伸,因此只针对摘要和Table2Text这两个生成任务进行了评估。 PrefixTuning可以理解是CTRL模型的连续化升级版,为了生成不同领域和话题的文本,CTRL是在预训练阶段在输入文本前加入了control code,例如好评...
Large Model
2026-01-11

背景 随着预训练语言模型进入LLM时代,其参数量愈发庞大。全量微调模型所有参数所需的显存早已水涨船高。 例如: 全参微调Qwen1.57BChat预估要2张80GB的A800,160GB显存 全参微调Qwen1.572BChat预估要20张80GB的A800,至少1600GB显存。 而且,通常不同的下游任务还需要LLM的全量参数,对于算法服务部署来说简直是个灾难 当然,一种折衷做法就是全量微调后把增量参数进行SVD分解保存,推理时再合并参数 为了寻求一个不更新全部参数的廉价微调方案,之前一些预训练语言模型的高效微调(Parameter Efficient finetuning, PEFT)工作,要么插入一些参数或学习外部模块来适应新的下游任务。 Adapter tuning Adapter ...
Python
2026-01-11
Python程序中存储的所有数据都是对象,每一个对象有一个身份,一个类型和一个值。 看变量的实际作用,执行a = 8 这行代码时,就会创建一个值为8的int对象。 变量名是对这个"一个值为8的int对象"的引用。(也可以简称a绑定到8这个对象) 1、可以通过id()来取得对象的身份 这个内置函数,它的参数是a这个变量名,这个函数返回的值 是这个变量a引用的那个"一个值为8的int对象"的内存地址。 [代码] 2、可以通过type()来取得a引用对象的数据类型 [代码] 3、对象的值 当变量出现在表达式中,它会被它引用的对象的值替代。 总结:类型是属于对象,而不是变量。变量只是对对象的一个引用。 对象有可变对象和不可变对象之分。 Python函数传递参数到底是传值还是引用? 传值、引用这个是c...
Search&Rec
2026-01-11
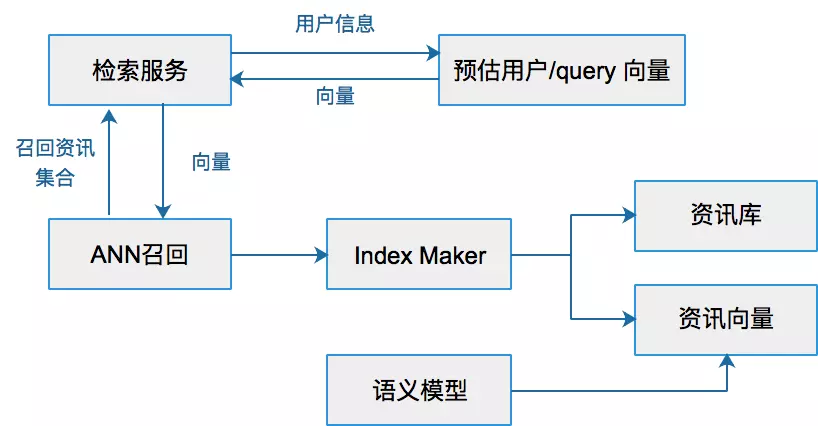
1. 概述 新闻推荐系统从海量新闻中推荐出你感兴趣的新闻,百度从海量的搜索结果中找到最优的结果,短视频推荐出你每天都停不下来的视频流,这些里面都包含ANN方法。当然,在现在的检索系统中,往往是多分支并行触发的效果,虽然DNN 大行其道,但是 ANN 一直不可或缺。 通用理解上,ANN(Approximate Nearest Neighbor)是在向量空间中搜索向量最近邻的优化问题。目前业界常用nmslib、Annoy算法作为实现。在实际的工程应用中,ANN是作为一种向量检索技术应用,用于解决长尾Query召回问题。将一个资讯的ANN 召回系统抽象出来大概是下面的样子。 Ann(approximate nearest neighbor)是指一系列用于解决最近邻查找问题的近似算法。最近邻查找问题...
Search&Rec
2026-01-11
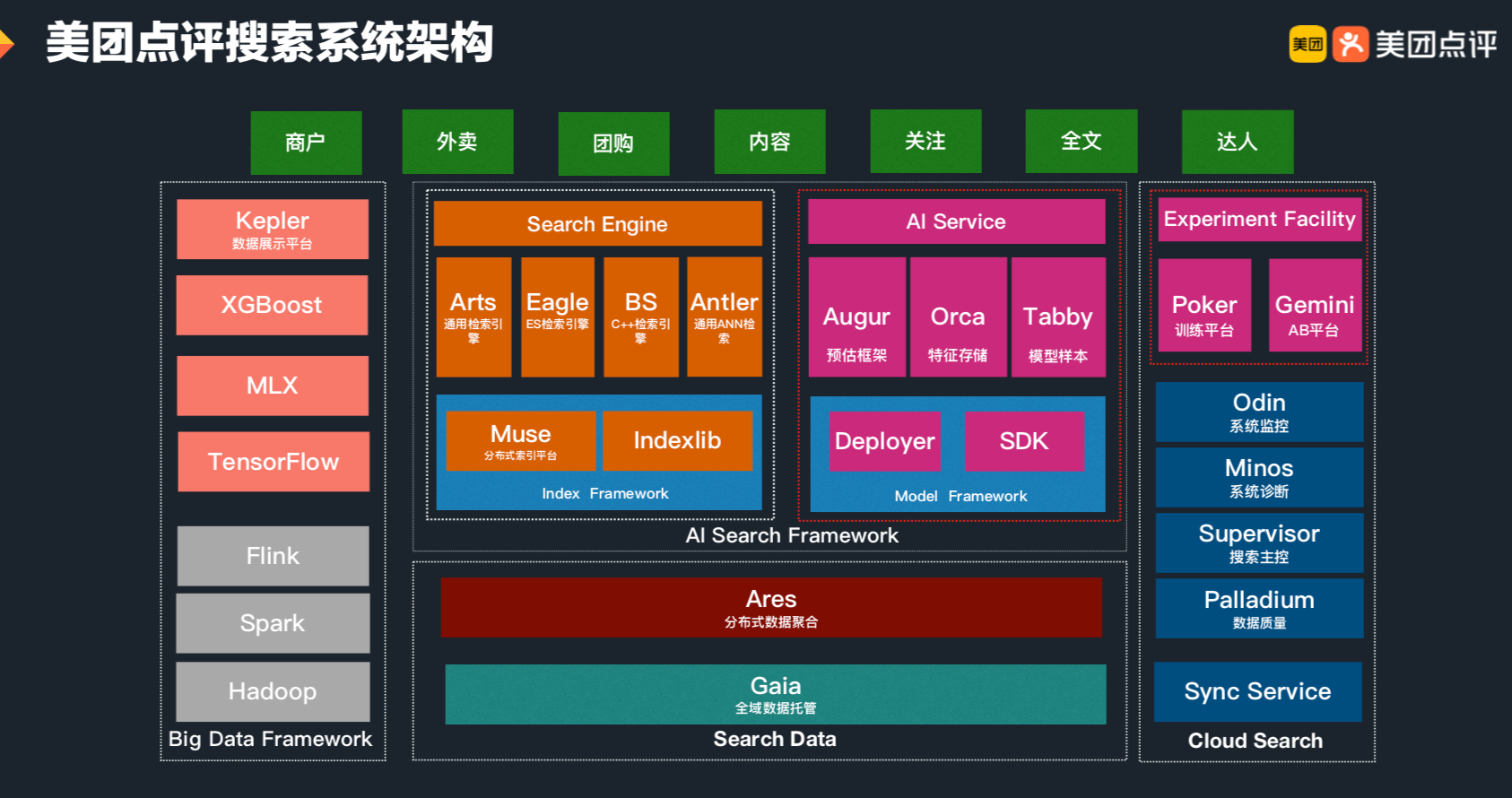
当前,美团搜索整体架构主要由搜索数据平台、在线检索框架及云搜平台、在线AI服务及实验平台三大体系构成。在AI服务及实验平台中,模型训练平台Poker和在线预估框架Augur是搜索AI化的核心组件,解决了模型从离线训练到在线服务的一系列系统问题,极大地提升了整个搜索策略迭代效率、在线模型预估的性能以及排序稳定性,并助力商户、外卖、内容等核心搜索场景业务指标的飞速提升。 首先,美团App内的一次完整的搜索行为主要涉的技术模块。如下图所示,从点击输入框到最终的结果展示,从热门推荐,到动态补全、最终的商户列表展示、推荐理由的展示等,每一个模块都要经过若干层的模型处理或者规则干预,才会将最适合用户(指标)的结果展示在大家的眼前。 为了保证良好的用户体验,技术团队对模型预估能力的要求变得越来越高,同时模...
Search&Rec
2026-01-11
1.倒排索引召回 1)召回模型有三种: 1.基于行为的召回:根据用户的购买行为推荐相关/相似的商品;(长期行为和实时行为) 2.基于用户偏好的召回:用户画像和多屏互通(移动端到PC端); 3.基于地域的召回; 4.基于搜索词的召回(倒排索引); 2)倒排索引 倒排是指由属性值来确定记录的位置。 倒排索引由单词词典和倒排文件组成, 单词词典是由文档集合中出现过的所有单词构成的字符串集合,单词词典内每条索引项记载单词本身的一些信息以及指向“倒排列表”的指针。 倒排文件记录所有单词的倒排列表顺序。 好处是在找含有该词的文件时,不需要扫描所有文件,而只需要在单词词典中找到该词,然后找到该词对应的倒排列表即可。 Lucene倒排步骤: 1.取得关键词; 2.建立倒排索引;lucene将上面三列分别作为...
Search&Rec
2026-01-11

一句话总结 正排索引:一个未经处理的数据库中,一般是以文档ID作为索引,以文档内容作为记录。 倒排索引:Inverted index,指的是将单词或记录作为索引,将文档ID作为记录,这样便可以方便地通过单词或记录查找到其所在的文档。 倒排索引创建索引的流程 形成文档列表 首先对原始文档数据进行编号(DocID),形成列表,就是一个文档列表。 创建倒排索引列表 对文档中数据进行分词,得到词条。对词条进行编号,以词条创建索引。保存包含这些词条的文档的编号信息。 搜索的过程 当用户输入任意的词条时,首先对用户输入的数据进行分词,得到用户要搜索的所有词条,然后拿着这些词条去倒排索引列表中进行匹配。找到这些词条就能找到包含这些词条的所有文档的编号。 然后根据这些编号去文档列表中找到文档 正排和倒排 正...
Large Model
2026-01-11

引言与背景 FlashAttention的关键创新在于使用类似于在线Softmax的思想来对自注意力计算进行分块(tiling),从而能够融合整个多头注意力层的计算,而无需访问GPU全局内存来存储中间的logits和注意力分数 在深度学习中,Transformer模型的自注意力机制是计算密集型操作。传统实现需要在GPU全局内存中存储大量中间结果,这导致: 内存瓶颈:中间矩阵占用大量显存 I/O开销:频繁的全局内存访问降低效率 扩展性限制:难以处理超长序列 FlashAttention通过算法创新解决了这些问题。 SelfAtention 自注意力机制的计算可以总结为(为简化说明,忽略头数和批次维度,也省略注意力掩码和缩放因子 [Math] ): [公式] 其中: Q, K, V, O 都是形...
Large Model
2026-01-11

背景 随着预训练语言模型进入LLM时代,其参数量愈发庞大。全量微调模型所有参数所需的显存早已水涨船高。 例如: 全参微调Qwen1.57BChat预估要2张80GB的A800,160GB显存 全参微调Qwen1.572BChat预估要20张80GB的A800,至少1600GB显存。 而且,通常不同的下游任务还需要LLM的全量参数,对于算法服务部署来说简直是个灾难 当然,一种折衷做法就是全量微调后把增量参数进行SVD分解保存,推理时再合并参数 为了寻求一个不更新全部参数的廉价微调方案,之前一些预训练语言模型的高效微调(Parameter Efficient finetuning, PEFT)工作,要么插入一些参数或学习外部模块来适应新的下游任务。 LoRA LoRA(LowRank Adapt...
Large Model
2026-01-11

通常我们训练神经网络模型的时候默认使用的数据类型为单精度FP32。近年来,为了加快训练时间、减少网络训练时候所占用的内存,并且保存训练出来的模型精度持平的条件下,业界提出越来越多的混合精度训练的方法。这里的混合精度训练是指在训练的过程中,同时使用单精度(FP32)和半精度(FP16)。 浮点数据类型 浮点数据类型主要分为双精度(FP64)、单精度(FP32)、半精度(FP16)。在神经网络模型的训练过程中,一般默认采用单精度(FP32)浮点数据类型,来表示网络模型权重和其他参数。在了解混合精度训练之前,这里简单了解浮点数据类型。 根据IEEE二进制浮点数算术标准(IEEE 754)的定义,浮点数据类型分为双精度(FP64)、单精度(FP32)、半精度(FP16)三种,其中每一种都有三个不同的...
Large Model
2026-01-11

概述 Medusa 是自投机领域较早的一篇工作,对后续工作启发很大,其主要思想是 multidecoding head + tree attention + typical acceptance(threshold)。Medusa 没有使用独立的草稿模型,而是在原始模型的基础上增加多个解码头(MEDUSA heads),并行预测多个后续 token。 正常的LLM只有一个用于预测 t 时刻token的head。Medusa 在 LLM 的最后一个 Transformer层之后保留原始的 LM Head,然后额外增加多个(假设是 k 个) 可训练的Medusa Head(解码头),分别负责预测 ...
Large Model
2026-01-11

概述 MTP(Multitoken Prediction)的总体思路是:让模型使用n个独立的输出头来预测接下来的n个token,这n个独立的输出头共享同一个模型主干。这样通过解码阶段的优化,将1token的生成,转变成multitoken的生成,从而提升训练和推理的性能。 在DeepSeek之前也有几个MTP方案,其侧重点各自不同。 侧重推理时解码加速。比如论文“MEDUSA: Simple LLM Inference Acceleration Framework with Multiple Decoding Heads”、论文“EAGLE: Speculative Sampling Requires Rethinking Feature Uncertainty”等。这些方案通过一次生成多个...