
💡 GRPO相比PPO主要优势: 1. 训练更稳定 引入 KL 散度惩罚项,有效控制策略更新的幅度,避免策略崩溃,提高训练的稳定性 GRPO用组内相对优势替代value model,消除了value估计误差 通过组内归一化,自动消除reward scale和bias的影响 实验中发现GRPO的advantage方差比PPO小30%左右,训练崩溃率更低 2. 工程更简单 只需要1-2个模型(policy + reference),而PPO需要4个 显存占用减少50%以上,训练速度提升2-3倍 超参数更少,更容易调优 3. 相对奖励机制 通过对同一输入生成的多个输出进行比较,GRPO 能够更稳定地估计优势函数,减少了训练过程中的方差 背景 GRPO是 DeepSeek-Math model中提出的对PPO方法的改进策略: 强化学习(RL)在提升模型数学推理能力方面被证明是有效的 传统PPO算法需要较大训练资源 GRPO作为PPO的变体被提出,可以更高效地优化模型 PPO Vs GRPO PPO回顾 PPO的目标函数为: \[\begin{aligned}J_{PPO}(\theta) =...
Machine Learning
2026-03-18

集成学习主要分为以下几类:Bagging,Boosting以及Stacking。 传统机器学习算法 (例如:决策树,人工神经网络,支持向量机,朴素贝叶斯等) 的目标都是寻找一个最优分类器尽可能的将训练数据分开。集成学习 (Ensemble Learning) 算法的基本思想就是将多个分类器组合,从而实现一个预测效果更好的集成分类器。集成算法可以说从一方面验证了中国的一句老话:三个臭皮匠,赛过诸葛亮。 Thomas G. Dietterich 指出了集成算法在统计,计算和表示上的有效原因: 统计上的原因 一个学习算法可以理解为在一个假设空间 H 中选找到一个最好的假设。但是,当训练样本的数据量小到不够用来精确的学习到目标假设时,学习算法可以找到很多满足训练样本的分类器。所以,学习算法选择任何一个分类器都会面临一定错误分类的风险,因此将多个假设集成起来可以降低选择错误分类器的风险。 计算上的原因 很多学习算法在进行最优化搜索时很有可能陷入局部最优的错误中,因此对于学习算法而言很难得到一个全局最优的假设。事实上人工神经网络和决策树已经被证实为是一 个NP...
Machine Learning
2026-03-18

从GBDT到XGBoost 作为GBDT的高效实现,XGBoost是一个上限特别高的算法,因此在算法竞赛中比较受欢迎。简单来说,对比原算法GBDT,XGBoost主要从下面三个方面做了优化: 一是算法本身的优化:在算法的弱学习器模型选择上,对比GBDT只支持决策树,还可以选择很多其他的弱学习器。在算法的损失函数上,除了本身的损失,还加上了正则化部分。在算法的优化方式上,GBDT的损失函数只对误差部分做负梯度(一阶泰勒)展开,而XGBoost损失函数对误差部分做二阶泰勒展开,更加准确。算法本身的优化是我们后面讨论的重点。 二是算法运行效率的优化:对每个弱学习器,比如决策树建立的过程做并行选择,找到合适的子树分裂特征和特征值。在并行选择之前,先对所有的特征的值进行排序分组,方便前面说的并行选择。对分组的特征,选择合适的分组大小,使用CPU缓存进行读取加速。将各个分组保存到多个硬盘以提高IO速度。 三是算法健壮性的优化:对于缺失值的特征,通过枚举所有缺失值在当前节点是进入左子树还是右子树来决定缺失值的处理方式。算法本身加入了L1和L2正则化项,可以防止过拟合,泛化能力更强。...
Machine Learning
2026-03-18
GBDT (Gradient Boosting Decision Tree) 是另一种基于 Boosting 思想的集成算法,除此之外 GBDT 还有很多其他的叫法,例如:GBM (Gradient Boosting Machine),GBRT (Gradient Boosting Regression Tree),MART (Multiple Additive Regression Tree) 等等。GBDT 算法由 3 个主要概念构成:Gradient Boosting (GB),Regression Decision Tree (DT 或 RT) 和 Shrinkage。 Decision Tree:CART回归树 首先,GBDT使用的决策树是CART回归树,无论是处理回归问题还是二分类以及多分类,GBDT使用的决策树通通都是都是CART回归树。为什么不用CART分类树呢?因为GBDT每次迭代要拟合的是 梯度值...
Machine Learning
2026-03-18
分类问题 Adaboost 是 Boosting 算法中有代表性的一个。原始的 Adaboost 算法用于解决二分类问题,因此对于一个训练集 \[T = \{\left(x_1, y_1\right), \left(x_2, y_2\right), ..., \left(x_n, y_n\right)\}\] 其中 \(x_i \in \mathcal{X} \subseteq \mathbb{R}^n, y_i \in \mathcal{Y} = \{-1, +1\}\) ,,首先初始化训练集的权重 \[\begin{aligned}
D_1 =& \left(w_{11}, w_{12}, ..., w_{1n}\right) \\
w_{1i} =& \dfrac{1}{n}, i = 1, 2, ..., n
\end{aligned}\] 根据每一轮训练集的权重 \(D_m\) ,对训练集数据进行抽样得到 \(T_m\) ,再根据 \(T_m\) 训练得到每一轮的基学习器 \(h_m\) 。通过计算可以得出基学习器 \(h_m\) 的误差为 \(e_m\) \[e_m =...
Large Model
2026-03-10

k1.5—CoT强化训练 概述 Kimi k1.5采用了一种简化而有效的强化学习框架,其核心在于长上下文扩展和改进的策略优化方法,而不依赖于更复杂的技术如蒙特卡洛树搜索、价值函数和过程奖励模型。 问题设定 给定训练数据集 \(D = \{(x_i, y^*_i)\}_{i=1}^n\) ,其中包含问题 \(x_i\) 和对应的真实答案 \(y^*_i\) ,目标是训练一个策略模型 \(\pi_\theta\) 来准确解决测试问题。在复杂推理场景中,思维链(CoT)方法提出使用一系列中间步骤 \(z = (z_1, z_2, ..., z_m)\) 来连接问题 \(x\) 和答案 \(y\) ,每个 \(z_i\) 是解决问题的重要中间步骤。 当解决问题 \(x\) 时,思维 \(z_t \sim \pi_\theta(\cdot|x, z_1, ..., z_{t-1})\) 被自回归采样,最终答案 \(y \sim \pi_\theta(\cdot|x, z_1, ..., z_m)\) 。 强化学习目标 基于真实答案 \(y^*\) ,分配一个值 \(r(x, y, y^*)...
Deep Learning
2026-03-02

Random erasing data augmentation 论文名称:Random erasing data augmentation 论文地址: https://arxiv.org/pdf/1708.04896v2.pdf 随机擦除增强,非常容易理解。作者提出的目的主要是模拟遮挡,从而提高模型泛化能力,这种操作其实非常make sense,因为我把物体遮挡一部分后依然能够分类正确,那么肯定会迫使网络利用局部未遮挡的数据进行识别,加大了训练难度,一定程度会提高泛化能力。其也可以被视为add noise的一种,并且与随机裁剪、随机水平翻转具有一定的互补性,综合应用他们,可以取得更好的模型表现,尤其是对噪声和遮挡具有更好的鲁棒性。具体操作就是:随机选择一个区域,然后采用随机值进行覆盖,模拟遮挡场景。 在细节上,可以通过参数控制擦除的面积比例和宽高比,如果随机到指定数目还无法满足设置条件,则强制返回。 一些可视化效果如下: Cutout 论文名称:Improved Regularization of Convolutional Neural Networks with Cutout...
Deep Learning
2026-03-02
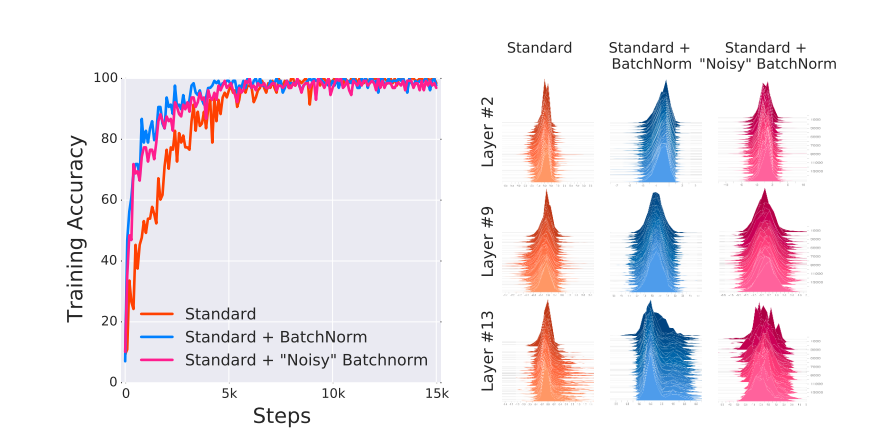
Batch Normalization 什么是批归一化(Batch Normalization) 以前在神经网络训练中,只是对输入层数据进行归一化处理,却没有在中间层进行归一化处理。要知道,虽然我们对输入数据进行了归一化处理,但是 输入数据经过 ** \(\sigma(WX+b)\) 这样的矩阵乘法以及非线性运算之后,其数据分布很可能被改变,而随着深度网络的多层运算之后,数据分布的变化将越来越大**。如果我们能在网络的中间也进行归一化处理,是否对网络的训练起到改进作用呢?答案是肯定的。 这种在神经网络中间层也进行归一化处理,使训练效果更好的方法,就是批归一化Batch Normalization(BN)。 其作用在整个mini-batch上,沿着 \(C\) 维度对 \(N,H,W\) 三个维度进行归一化。具体来说,就是把第1个样本的第1个通道,加上第2个样本第1个通道 ...... 加上第 \(N\) 个样本第1个通道,求平均,得到通道 1 的均值 (注意是除以 \(N×H×W\) 而不是单纯除以 \(N\) ,最后得到的是一个代表这个 batch...
Deep Learning
2026-03-02

通过卷积和池化等技术可以将图像进行降维,因此,一些研究人员也想办法恢复原分辨率大小的图像,特别是在语义分割领域应用很成熟。 Upsampling(上采样)[没有学习过程] 在FCN、U-net等网络结构中,涉及到了上采样。上采样概念: 上采样指的是任何可以让图像变成更高分辨率的技术 。最简单的方式是 重采样和插值 :将输入图片进行rescale到一个想要的尺寸,而且计算每个点的像素点,使用如双线性插值等插值方法对其余点进行插值来完成上采样过程。 在PyTorch中,上采样的层被封装在 torch.nn 中的 Vision Layers 里面,一共有4种: PixelShuffle Upsample UpsamplingNearest2d UpsamplingBilinear2d PixelShuffle 当stride = (1/r) < 1时,可以让卷积后的feature map变大——即分辨率变大,这个新的操作叫做sub-pixel convolution,具体原理可以看 “PixelShuffle:Real-Time Single Image and Video...
Deep Learning
2026-02-28
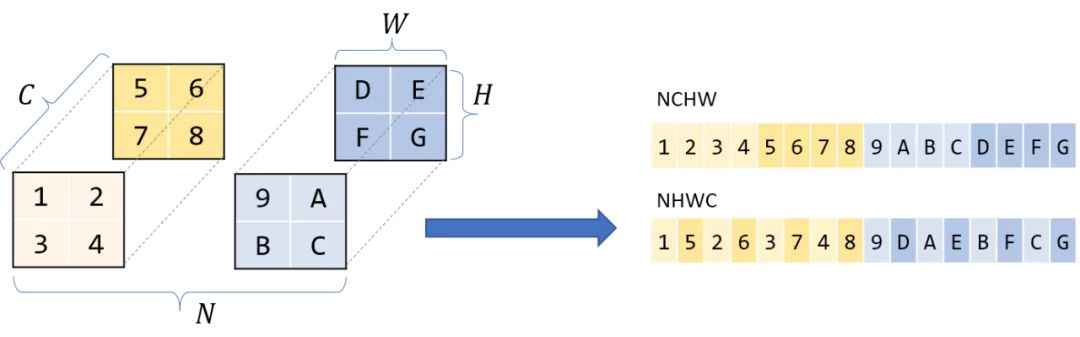
现代深度学习库对大多数操作都具有生产级的、高度优化的实现,这并不奇怪。但这些库究竟是什么魔法?他们如何能够将性能提高100倍?究竟怎样才能“优化”或加速神经网络的运行呢?在讨论高性能/高效DNNs时,我经常会问(也经常被问到)这些问题。 在这篇文章中,我将尝试带你了解在DNN库中卷积层是如何实现的。它不仅是在模型中最常见的和最重的操作,我还发现卷积高性能实现的技巧特别具有代表性——一点点算法的小聪明,非常多的仔细的调优和低层架构的开发。 我在这里介绍的很多内容都来自Goto等人的开创性论文:Anatomy of a high-performance matrix multiplication,该论文为OpenBLAS等线性代数库中使用的算法奠定了基础。 最原始的卷积实现 “过早的优化是万恶之源”——Donald Knuth 在进行优化之前,我们先了解一下基线和瓶颈。这是一个朴素的numpy/for循环卷积: '''
Convolve `input` with `kernel` to generate `output`
input.shape =...