Reinforcement Learning
2026-03-27
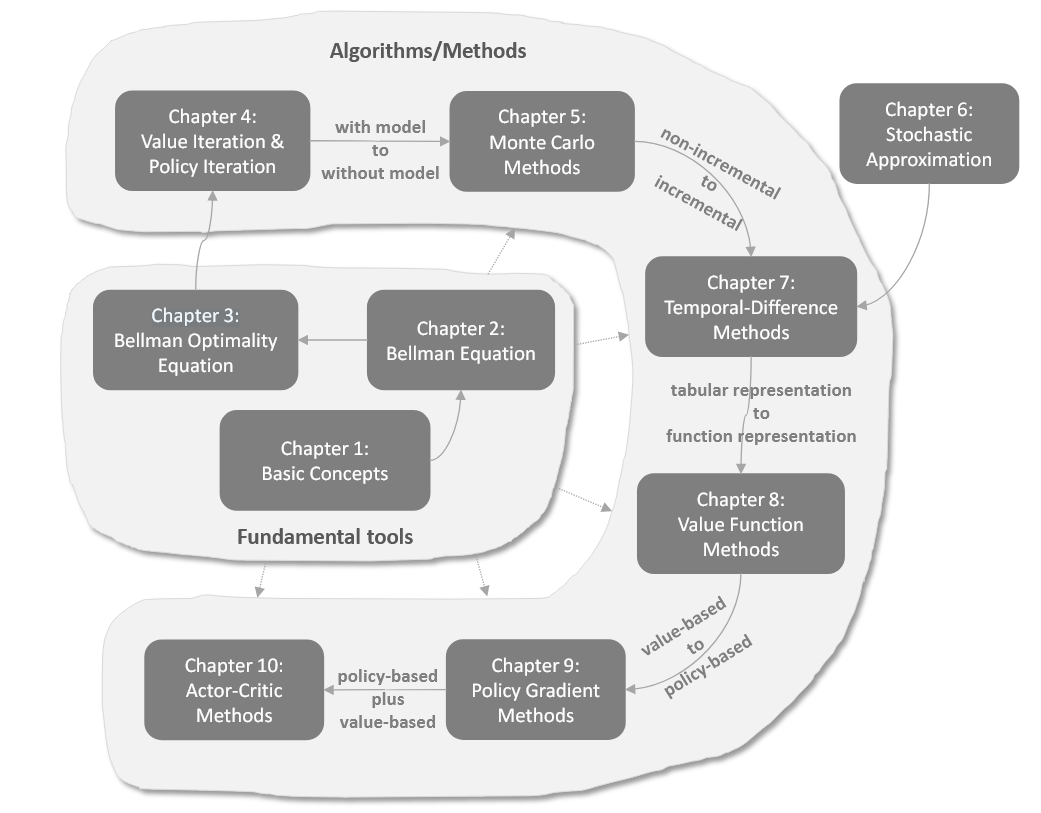
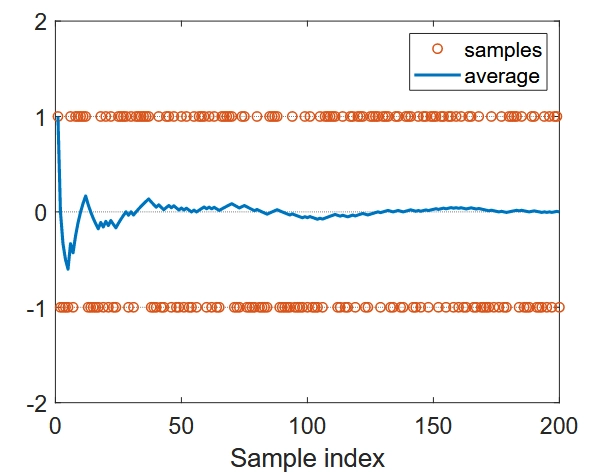
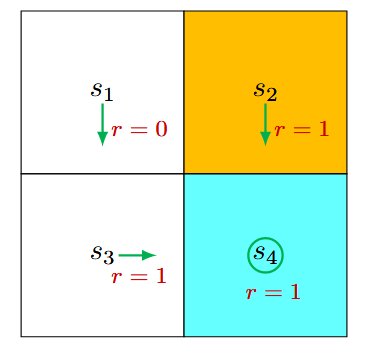
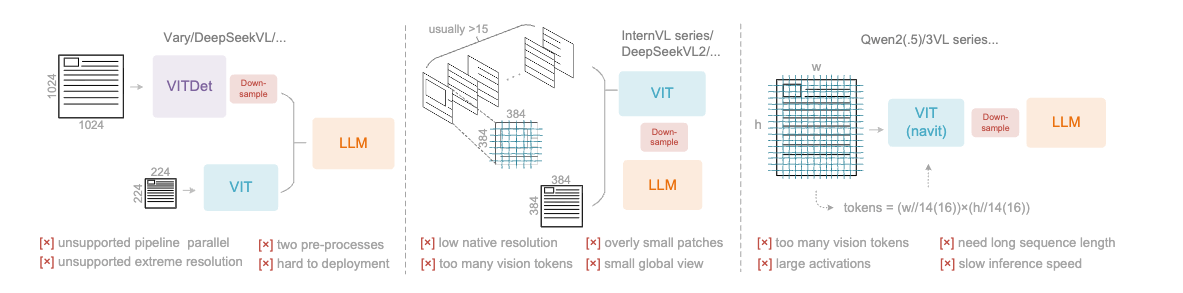
强化学习基础 RL基础概念 贝尔曼方程(Bellman Equation) 贝尔曼最优方程(Bellman Optimality Equation) 价值迭代和策略迭代 强化学习Model-Free之蒙特卡洛 改进算法 LLM中的RL DPO(Direct Preference Optimization)