
💡 GRPO相比PPO主要优势: 1. 训练更稳定 引入 KL 散度惩罚项,有效控制策略更新的幅度,避免策略崩溃,提高训练的稳定性 GRPO用组内相对优势替代value model,消除了value估计误差 通过组内归一化,自动消除reward scale和bias的影响 实验中发现GRPO的advantage方差比PPO小30%左右,训练崩溃率更低 2. 工程更简单 只需要1-2个模型(policy + reference),而PPO需要4个 显存占用减少50%以上,训练速度提升2-3倍 超参数更少,更容易调优 3. 相对奖励机制 通过对同一输入生成的多个输出进行比较,GRPO 能够更稳定地估计优势函数,减少了训练过程中的方差 背景 GRPO是 DeepSeek-Math model中提出的对PPO方法的改进策略: 强化学习(RL)在提升模型数学推理能力方面被证明是有效的 传统PPO算法需要较大训练资源 GRPO作为PPO的变体被提出,可以更高效地优化模型 PPO Vs GRPO PPO回顾 PPO的目标函数为: \[\begin{aligned}J_{PPO}(\theta) =...
NLP
2026-03-26

这篇文章主要去“复盘”一下主流的长度外推结果,并试图从中发现免训练长度外推的关键之处。 问题定义 顾名思义,免训练长度外推,就是不需要用长序列数据进行额外的训练,只用短序列语料对模型进行训练,就可以得到一个能够处理和预测长序列的模型,即“Train Short, Test Long”。那么如何判断一个模型能否用于长序列呢?最基本的指标就是模型的长序列Loss或者PPL不会爆炸,更加符合实践的评测则是输入足够长的Context,让模型去预测答案,然后跟真实答案做对比,算BLEU、ROUGE等, LongBench 就是就属于这类榜单。 但要注意的是,长度外推应当不以牺牲远程依赖为代价——否则考虑长度外推就没有意义了,倒不如直接截断文本——这意味着通过显式地截断远程依赖的方案都需要谨慎选择,比如ALIBI,还有带显式Decay的 线性RNN ,这些方案当序列长度足够大时都表现为局部注意力,即便有可能实现长度外推,也会有远程依赖不足的风险,需要根据自己的场景斟酌使用。 如何判断在长度外推的同时有没有损失远程依赖呢?比较严谨的是像 ReRoPE...
Large Model
2026-03-18
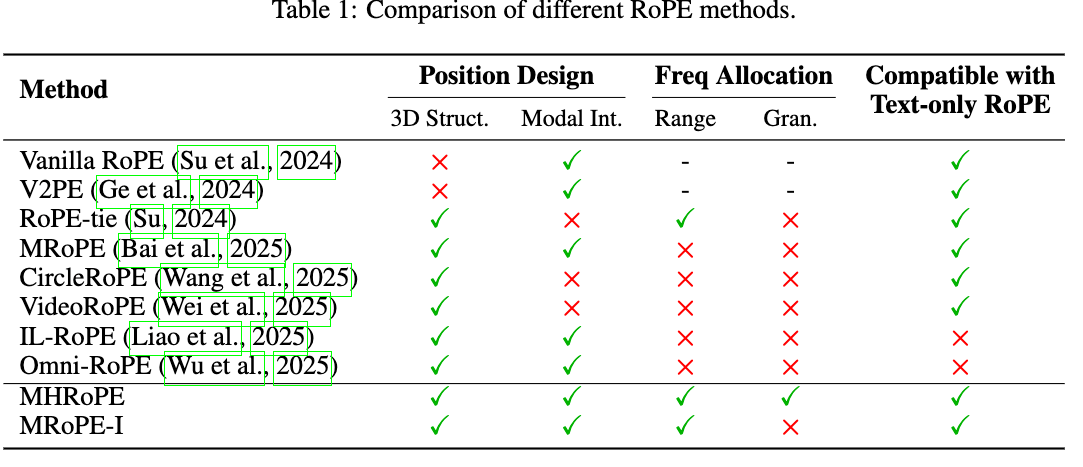
简介 论文: 《REVISITING MULTIMODAL POSITIONAL ENCODING IN VISION–LANGUAGE MODELS》 通过对多模态旋转位置嵌入(RoPE)的两个核心组件——位置设计和频率分配进行综合分析。通过实验,确定了三个关键指南:位置一致性、频率全利用和保留文本先验。基于这些见解,提出了多头RoPE(MHRoPE)和MRoPE-Interleave(MRoPE-I),这两种简单且即插即用的变体不需要任何架构更改。 为了构建更稳健的多模态位置编码,作者在MRoPE的基础上,系统地探索了三个未充分研究的方案: 位置设计——如何为文本和视觉标记分配无歧义、分离良好的坐标; 频率分配——如何将旋转频率分配到每个位置轴的嵌入维度; 与纯文本RoPE的兼容性——确保设计默认为标准RoPE,以便进行有效的迁移学习。 Vanilla RoPE RoPE与加性位置嵌入不同,RoPE对query和key向量应用旋转变换,从而将相对位置依赖直接纳入自注意力机制。给定位置 \(m\) 的查询向量 \(q\) 和位置 \(n\) 的键向量 \(k\) ,注意力分数...
NLP
2026-03-16
不同于RNN、CNN等模型,对于Transformer模型来说,位置编码的加入是必不可少的,因为纯粹的Attention模块是无法捕捉输入顺序的,即无法区分不同位置的Token。为此我们大体有两个选择: 想办法将位置信息融入到输入中,这构成了绝对位置编码的一般做法; 想办法微调一下Attention结构,使得它有能力分辨不同位置的Token,这构成了相对位置编码的一般做法。 虽然说起来主要就是绝对位置编码和相对位置编码两大类,但每一类其实又能衍生出各种各样的变种,为此研究人员可算是煞费苦心、绞尽脑汁了,此外还有一些不按套路出牌的位置编码。本文就让我们来欣赏一下研究人员为了更好地表达位置信息所构建出来的“八仙过海,各显神通”般的编码方案。 绝对位置编码 形式上来看,绝对位置编码是相对简单的一种方案,但即便如此,也不妨碍各路研究人员的奇思妙想,也有不少的变种。一般来说,绝对位置编码会加到输入中:在输入的第 𝑘 个向量 \(𝑥_𝑘\) 中加入位置向量 \(𝑝_𝑘\) 变为 \(\boldsymbol{x}_k + \boldsymbol{p}_k\) ,其中 \(...
Large Model
2026-03-10

k1.5—CoT强化训练 概述 Kimi k1.5采用了一种简化而有效的强化学习框架,其核心在于长上下文扩展和改进的策略优化方法,而不依赖于更复杂的技术如蒙特卡洛树搜索、价值函数和过程奖励模型。 问题设定 给定训练数据集 \(D = \{(x_i, y^*_i)\}_{i=1}^n\) ,其中包含问题 \(x_i\) 和对应的真实答案 \(y^*_i\) ,目标是训练一个策略模型 \(\pi_\theta\) 来准确解决测试问题。在复杂推理场景中,思维链(CoT)方法提出使用一系列中间步骤 \(z = (z_1, z_2, ..., z_m)\) 来连接问题 \(x\) 和答案 \(y\) ,每个 \(z_i\) 是解决问题的重要中间步骤。 当解决问题 \(x\) 时,思维 \(z_t \sim \pi_\theta(\cdot|x, z_1, ..., z_{t-1})\) 被自回归采样,最终答案 \(y \sim \pi_\theta(\cdot|x, z_1, ..., z_m)\) 。 强化学习目标 基于真实答案 \(y^*\) ,分配一个值 \(r(x, y, y^*)...
Deep Learning
2026-03-02

通过卷积和池化等技术可以将图像进行降维,因此,一些研究人员也想办法恢复原分辨率大小的图像,特别是在语义分割领域应用很成熟。 Upsampling(上采样)[没有学习过程] 在FCN、U-net等网络结构中,涉及到了上采样。上采样概念: 上采样指的是任何可以让图像变成更高分辨率的技术 。最简单的方式是 重采样和插值 :将输入图片进行rescale到一个想要的尺寸,而且计算每个点的像素点,使用如双线性插值等插值方法对其余点进行插值来完成上采样过程。 在PyTorch中,上采样的层被封装在 torch.nn 中的 Vision Layers 里面,一共有4种: PixelShuffle Upsample UpsamplingNearest2d UpsamplingBilinear2d PixelShuffle 当stride = (1/r) < 1时,可以让卷积后的feature map变大——即分辨率变大,这个新的操作叫做sub-pixel convolution,具体原理可以看 “PixelShuffle:Real-Time Single Image and Video...
Deep Learning
2026-02-28
现代深度学习库对大多数操作都具有生产级的、高度优化的实现,这并不奇怪。但这些库究竟是什么魔法?他们如何能够将性能提高100倍?究竟怎样才能“优化”或加速神经网络的运行呢?在讨论高性能/高效DNNs时,我经常会问(也经常被问到)这些问题。 在这篇文章中,我将尝试带你了解在DNN库中卷积层是如何实现的。它不仅是在模型中最常见的和最重的操作,我还发现卷积高性能实现的技巧特别具有代表性——一点点算法的小聪明,非常多的仔细的调优和低层架构的开发。 我在这里介绍的很多内容都来自Goto等人的开创性论文:Anatomy of a high-performance matrix multiplication,该论文为OpenBLAS等线性代数库中使用的算法奠定了基础。 最原始的卷积实现 “过早的优化是万恶之源”——Donald Knuth 在进行优化之前,我们先了解一下基线和瓶颈。这是一个朴素的numpy/for循环卷积: '''
Convolve `input` with `kernel` to generate `output`
input.shape =...
NLP
2026-01-24

旋转式位置编码(ROPE) 原始的Sinusoidal位置编码总的感觉是一种“想要成为相对位置编码的绝对位置编码”。一般来说,绝对位置编码具有实现简单、计算速度快等优点,而相对位置编码则直接地体现了相对位置信号,跟我们的直观理解吻合,实际性能往往也更好。由此可见,如果可以通过绝对位置编码的方式实现相对位置编码,那么就是“集各家之所长”、“鱼与熊掌兼得”了。Sinusoidal位置编码隐约做到了这一点,但并不够好。 本文将会介绍我们自研的Rotary Transformer(RoFormer)模型,它的主要改动是应用了笔者构思的“旋转式位置编码(Rotary Position Embedding,RoPE)”,这是一种配合Attention机制能达到“绝对位置编码的方式实现相对位置编码”的设计。而也正因为这种设计,它还是目前唯一一种可用于线性Attention的相对位置编码。 RoFormer:https://github.com/ZhuiyiTechnology/roformer 基本思路 这里简要介绍过RoPE: Transformer位置编码...
Reinforcement Learning
2026-01-11

引言 DDPG同样使用了ActorCritic的结构,Deterministic的确定性策略是和随机策略相对而言的,对于某一些动作集合来说,它可能是连续值,或者非常高维的离散值,这样动作的空间维度极大。如果我们使用随机策略,即像DQN一样研究它所有的可能动作的概率,并计算各个可能的动作的价值的话,那需要的样本量是非常大才可行的。于是有人就想出使用确定性策略来简化这个问题。 作为随机策略,在相同的策略,在同一个状态 s 处,采用的动作 [Math] 是基于一个概率分布的,即是不确定的。而确定性策略则决定简单点,虽然在同一个状态处,采用的动作概率不同,但是最大概率只有一个,如果我们只取最大概率的动作,去掉这个概率分布,那么就简单多了。即作为确定性策略,相同的策略,在同一个状态处,动作是唯一确定的...
Reinforcement Learning
2026-01-11

概述与理论背景 ActorCritic方法是强化学习中的一类重要算法,它巧妙地结合了基于策略(policybased)和基于价值(valuebased)的方法。在这种结构中,"Actor"指策略更新步骤,负责根据策略执行动作;而"Critic"指价值更新步骤,负责评估Actor的表现。从另一个角度看,ActorCritic方法本质上仍是策略梯度算法,可以通过扩展策略梯度算法获得。 ActorCritic方法在强化学习中的位置非常重要,它既保留了策略梯度方法直接优化策略的优势,又利用了值函数方法的效率。这种结合使得ActorCritic方法成为解决复杂强化学习问题的强大工具。 最简单的ActorCritic算法(QAC) QAC算法通过扩展策略梯度方法得到。策略梯度方法的核心思想是通过最大化标...

💡 引言 Trust Region Policy Optimization (TRPO) 是2015年的ICML会议上提出的一种强大的基于策略的强化学习算法。TRPO 解决了传统策略梯度方法中的一些关键问题,特别是训练不稳定和步长选择困难的问题。与传统策略梯度算法相比,TRPO 具有更高的稳健性和样本效率,能够在复杂环境中取得更好的性能。 优化基础 在深入了解 TRPO 之前,我们需要先简单回顾一些优化方法的基础知识。 梯度上升法 梯度上升法是一种迭代优化算法,用于寻找函数的局部最大值。 目标:找到使目标函数 [Math] 最大化的参数 [Math] : [公式] 梯度上升迭代过程: 1. 在当前参数 [Math] 处计算梯度: [Math] 1. 更新参数: 梯度上升法的主要问题是学习率的...

引言与背景 策略梯度方法是强化学习中的一种重要方法,它标志着从基于价值的方法向基于策略的方法的重要转变。之前我们主要讨论了基于价值的方法(valuebased),而策略梯度方法则直接优化策略函数(policybased),这是一个重要的进步。 当策略用函数表示时,策略梯度方法的核心思想是通过优化某些标量指标来获得最优策略。与传统的表格表示策略不同,策略梯度方法使用参数化函数 [Math] 来表示策略,其中 [Math] 是参数向量。这种表示方法也可以写成其他形式,如 [Math] 、 [Math] 或 [Math] 。 策略梯度方法具有多种优势: 更高效地处理大型状态/动作空间 具有更强的泛化能力 样本使用效率更高 策略表示:从表格到函数 当策略的表示从表格转变为函数时,存在以下几个关键区别...