76. 最小覆盖子串 题目 给定两个字符串 s 和 t ,长度分别是 m 和 n ,返回 s 中的 最短窗口 子串 ,使得该子串包含 t 中的每一个字符( 包括重复字符 )。如果没有这样的子串,返回空字符串 "" 。 测试用例保证答案唯一。 示例 1: 输入:s = "ADOBECODEBANC", t = "ABC"
输出:"BANC"
解释:最小覆盖子串 "BANC" 包含来自字符串 t 的 'A'、'B' 和 'C'。 示例 2: 输入:s = "a", t = "a"
输出:"a"
解释:整个字符串 s 是最小覆盖子串。 示例 3: 输入: s = "a", t = "aa"
输出: ""
解释: t 中两个字符 'a' 均应包含在 s 的子串中,
因此没有符合条件的子字符串,返回空字符串。 提示: m == s.length n == t.length 1 <= m, n <= 10 5 s 和 t 由英文字母组成 题解 这是一个经典的 滑动窗口 (Sliding Window) 问题 我们需要维护一个动态的窗口 [left, right] : 右移扩大 :不断移动...
Deep Learning
2026-01-11
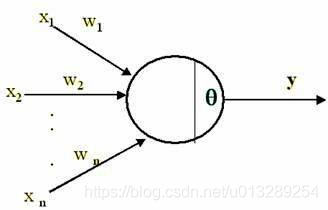
1.深度学习偏置的作用? 我们在学深度学习的时候,最早接触到的神经网络应该属于感知器(感知器本身就是一个很简单的神经网络,也许有人认为它不属于神经网络,当然认为它和神经网络长得像也行) 要想激活这个感知器,使得 y=1 ,就必须使 x_1w_1 + x_2w_2 +....+x_nw_n T ( T 为一个阈值),而 T 越大,想激活这个感知器的难度越大,人工选择一个阈值并不是一个好的方法,因为样本那么多,我不可能手动选择一个阈值,使得模型整体表现最佳,那么我们可以使得T变成可学习的,这样一来, T 会自动学习到一个数,使得模型的整体表现最佳。当把T移动到左边,它就成了偏置, x_1w_1 + x_2w_2 +....+x_nw_n T 0 xw +b 0 ,总之,偏置的大小控制着激活这个感...
Deep Learning
2026-01-11
如何计算RF 公式一:这个算法从top往下层层迭代直到追溯回input image,从而计算出RF。 [公式] 其中,RF是感受野。RF和RF有点像,N代表 neighbour,指的是第n层的 a feature在n1层的RF,记住N_RF只是一个中间变量,不要和RF混淆。 stride是步长,ksize是卷积核大小。
Computer Vision
2026-01-11
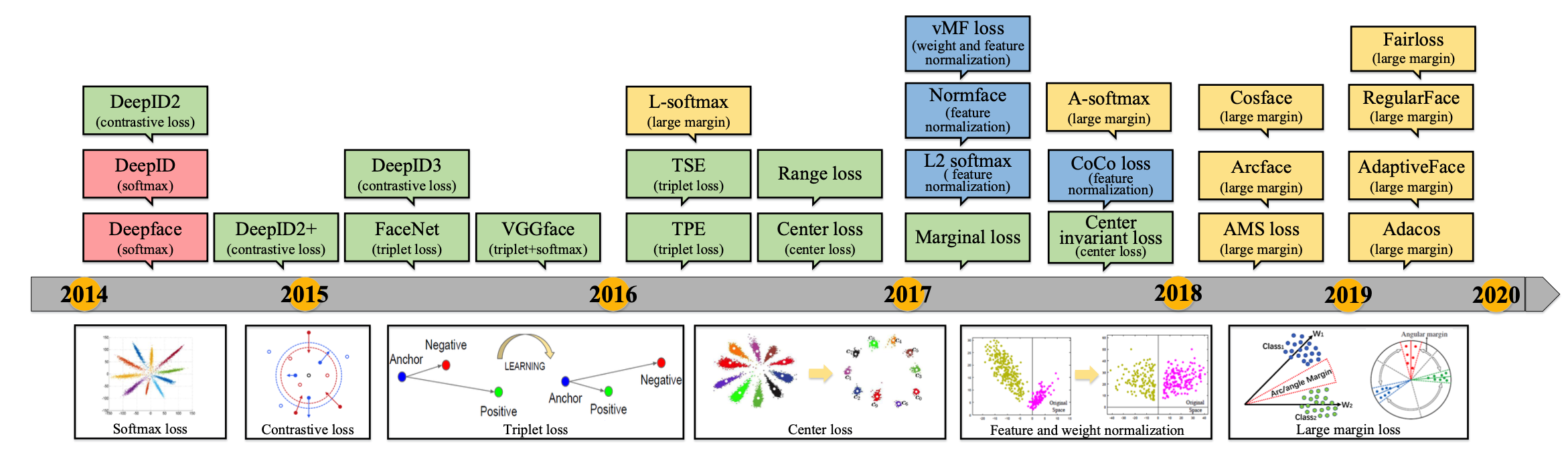
超多分类的Softmax 2014年CVPR两篇超多分类的人脸识别论文:DeepFace和DeepID DeepFace Taigman Y, Yang M, Ranzato M A, et al. Deepface: Closing the gap to humanlevel performance in face verification [C]// CVPR, 2014. 4.4M训练集,训练6层CNN + 4096特征映射 + 4030类Softmax,综合如3D Aligement, model ensembel等技术,在LFW上达到97.35%。 DeepID Sun Y, Wang X, Tang X. Deep learning face representation fro...
Computer Vision
2026-01-11
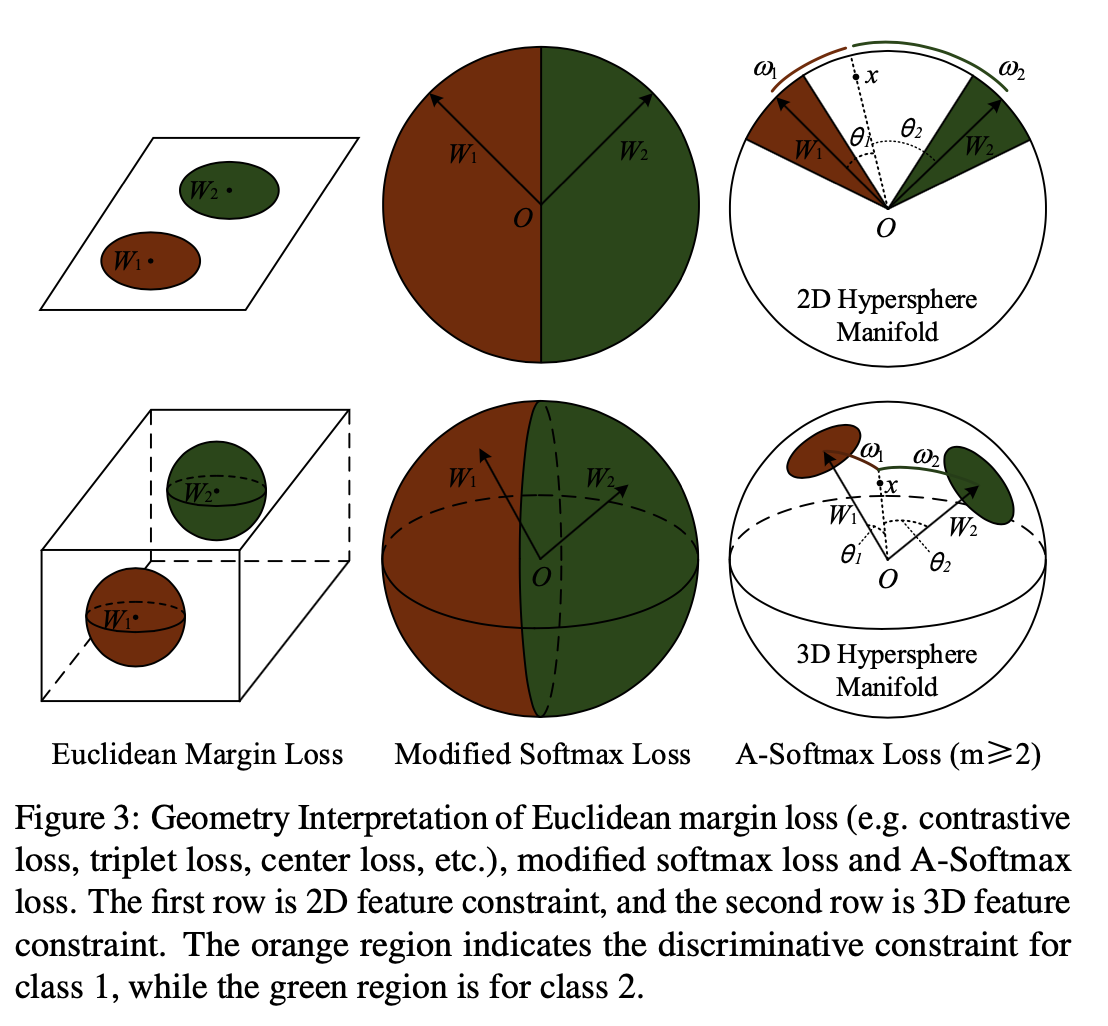
推导 回顾一下二分类下的Softmax后验概率,即: [公式] 显然决策的分界在当 𝑝_1=𝑝_2 时,所以决策界面是 (𝑊_1−𝑊_2)𝑥+𝑏_1−𝑏_2=0 。我们可以将 𝑊^𝑇_𝑖𝑥+𝑏_𝑖 写成 ‖W_i^T‖⋅‖x‖cos(θ_i)+b_i ,其中 θ_i 是 W_i 与 x 的夹角,如对 W_i 归一化且设偏置 b_i 为零( ‖W_i‖=1 , b_i=0 ),那么当 p_1=p_2 时,我们有 cos(θ_1)−cos(θ_2)=0 。从这里可以看到,如里一个输入的数据特征 x_i 属于 𝑦_𝑖 类,那么 θ_{y_i} 应该比其它所有类的角度都要小,也就是说在向量空间中 W_{y_i} 要更靠近 x_i 。 我们用的是Softmax Loss,对于输入 x_i ,So...
Large Model
2026-01-11

引言与背景 FlashAttention的关键创新在于使用类似于在线Softmax的思想来对自注意力计算进行分块(tiling),从而能够融合整个多头注意力层的计算,而无需访问GPU全局内存来存储中间的logits和注意力分数 在深度学习中,Transformer模型的自注意力机制是计算密集型操作。传统实现需要在GPU全局内存中存储大量中间结果,这导致: 内存瓶颈:中间矩阵占用大量显存 I/O开销:频繁的全局内存访问降低效率 扩展性限制:难以处理超长序列 FlashAttention通过算法创新解决了这些问题。 SelfAtention 自注意力机制的计算可以总结为(为简化说明,忽略头数和批次维度,也省略注意力掩码和缩放因子 [Math] ): [公式] 其中: Q, K, V, O 都是形...
Deep Learning
2026-01-11

通过卷积和池化等技术可以将图像进行降维,因此,一些研究人员也想办法恢复原分辨率大小的图像,特别是在语义分割领域应用很成熟。 1、Upsampling(上采样)[没有学习过程] 在FCN、Unet等网络结构中,涉及到了上采样。上采样概念:上采样指的是任何可以让图像变成更高分辨率的技术。最简单的方式是重采样和插值:将输入图片进行rescale到一个想要的尺寸,而且计算每个点的像素点,使用如双线性插值等插值方法对其余点进行插值来完成上采样过程。 在PyTorch中,上采样的层被封装在torch.nn中的Vision Layers里面,一共有4种: PixelShuffle Upsample UpsamplingNearest2d UpsamplingBilinear2d 0)PixelShuffl...
Computer Vision
2026-01-11
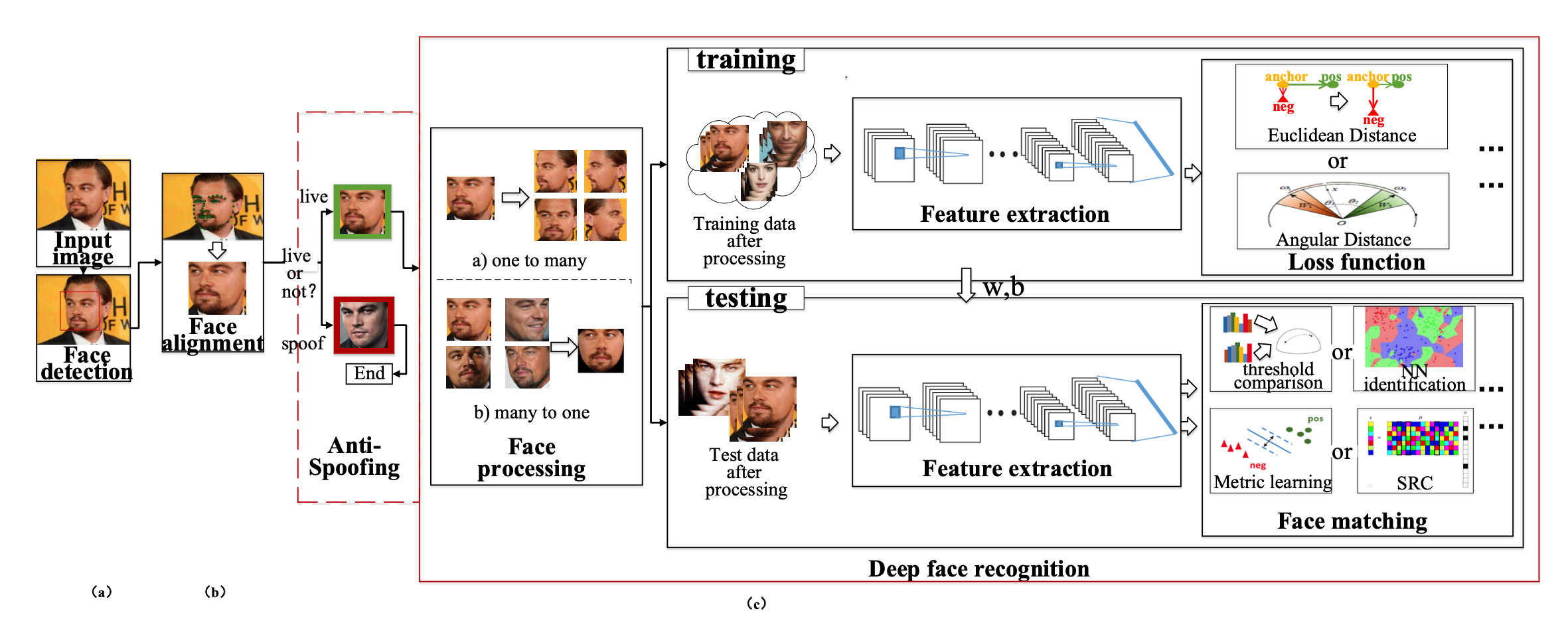
简介 一个完整的人脸识别系统包含以下几个模块 Face Detection: 人脸检测 Face Alignment:基于人脸关键点坐标对齐到正则坐标系下坐标 Face Recognition:基于对齐人脸进行识别 人脸识别的算法流程 人脸的识别流程:面部姿态处理(处理姿态,亮度,表情,遮挡),特征提取,人脸比对。 面部处理 face processing 这部分主要对姿态(主要)、亮度、表情、遮挡进行处理,可提升FR模型性能 主要包含两种处理方式: 1. "Onetomany Augmentation": 从单个图像生成不同姿态的图像,使模型学习到姿态不变性的表示 1. "Manytoone Normalization": 从多个不同姿态的图像中恢复人脸图像的标准视图 特征提取 Backb...
Large Model
2026-01-11

通常我们训练神经网络模型的时候默认使用的数据类型为单精度FP32。近年来,为了加快训练时间、减少网络训练时候所占用的内存,并且保存训练出来的模型精度持平的条件下,业界提出越来越多的混合精度训练的方法。这里的混合精度训练是指在训练的过程中,同时使用单精度(FP32)和半精度(FP16)。 浮点数据类型 浮点数据类型主要分为双精度(FP64)、单精度(FP32)、半精度(FP16)。在神经网络模型的训练过程中,一般默认采用单精度(FP32)浮点数据类型,来表示网络模型权重和其他参数。在了解混合精度训练之前,这里简单了解浮点数据类型。 根据IEEE二进制浮点数算术标准(IEEE 754)的定义,浮点数据类型分为双精度(FP64)、单精度(FP32)、半精度(FP16)三种,其中每一种都有三个不同的...
Large Model
2026-01-11

概述 Medusa 是自投机领域较早的一篇工作,对后续工作启发很大,其主要思想是 multidecoding head + tree attention + typical acceptance(threshold)。Medusa 没有使用独立的草稿模型,而是在原始模型的基础上增加多个解码头(MEDUSA heads),并行预测多个后续 token。 正常的LLM只有一个用于预测 t 时刻token的head。Medusa 在 LLM 的最后一个 Transformer层之后保留原始的 LM Head,然后额外增加多个(假设是 k 个) 可训练的Medusa Head(解码头),分别负责预测 ...
Large Model
2026-01-11

概述 MTP(Multitoken Prediction)的总体思路是:让模型使用n个独立的输出头来预测接下来的n个token,这n个独立的输出头共享同一个模型主干。这样通过解码阶段的优化,将1token的生成,转变成multitoken的生成,从而提升训练和推理的性能。 在DeepSeek之前也有几个MTP方案,其侧重点各自不同。 侧重推理时解码加速。比如论文“MEDUSA: Simple LLM Inference Acceleration Framework with Multiple Decoding Heads”、论文“EAGLE: Speculative Sampling Requires Rethinking Feature Uncertainty”等。这些方案通过一次生成多个...
Large Model
2026-01-11

概述 投机解码(Speculative Decoding)也叫预测解码/投机采样,它会利用小模型来预测大型模型的行为,从而提升模型在解码(decoding)阶段的解码效率问题,加速大型模型的执行。其核心思路如下图所示,首先以低成本的方式(以小模型为主,也有多头,检索,Early Exit 等方式)快速生成多个候选 Token(串行序列、树、多头树等),然后通过一次并行验证阶段快速验证多个 Token的正确性,只要平均每个 Step 验证的 Token 数 1,就可以一次性生成多个token,进而减少总的 Decoding 步数,实现加速的目的。 下图左侧是自回归解码模型,右侧是投机解码机制。 从本质上来说,投机解码希望在推理阶段在不大幅度改变模型的情况下,通过更好利用冗余算力来并行"投机"地...