Large Model
2026-04-03

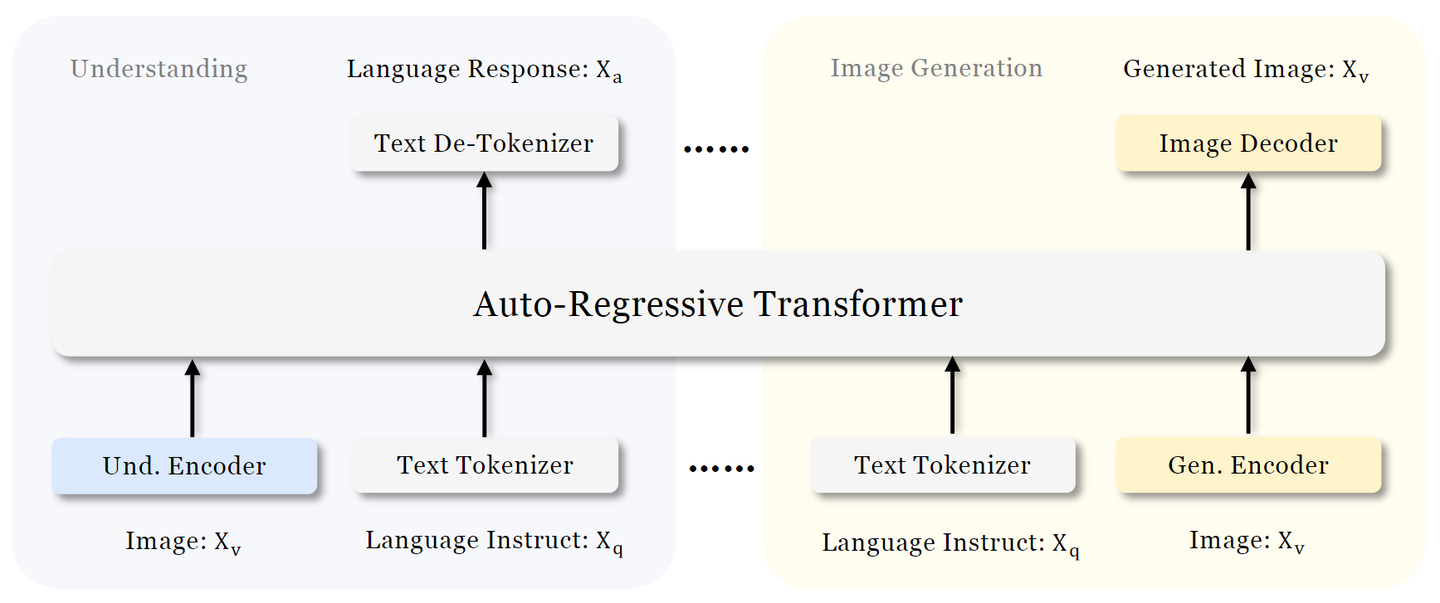
Chameleon 论文: https://arxiv.org/pdf/2405.09818 Chameleon 是一个既能做图像理解,又可以做图像或者文本生成任务的,从头训练的 Transformer 模型。完整记录了为实现 mixed-modal 模型的架构设计,稳定训练方法,对齐的配方。并在一系列全面的任务上进行评估:有纯文本任务,也有图像文本任务 (视觉问答、图像字幕),也有图像生成任务,还有混合模态的生产任务。 如下图所示,Chameleon 将所有模态数据 (图像、文本和代码) 都表示为离散 token,并使用统一的 Transformer 架构。训练数据是交错混合模态数据 ∼10T token,以端到端的方式从头开始训练。文本 token 用绿色表示,图像 token 用蓝色表示 研究背景 Chameleon 开创了一种新的模型范式,生成理解统一架构。 多模态基础模型的一般特点是单独去建模不同的模块,一般而言通过 modal-specific 的编码器或者解码器。这带来了一个问题就是可能会限制模型 跨模态整合信息 的能力,以及 生成可以包含任意图像和文本序列的多模态文档...