
Tokenizer 背景与基础 目前的机器学习模型都是数学模型,其对应的输入要求必须是数字形式(number)的,而我们处理的真实场景往往会包含许多非数字形式的输入(有时候即使原始输入是数字形式,我们也需要转换),最典型的就是 NLP 中的文字(string),为了让文字能够作为输入参与到模型的计算中去,我们就需要构建一个映射关系(mapping):将对应的文字映射到一个数字形式上去,而其对应的数字就是 token。而对应的这个映射关系,就是我们的 tokenizer:他可以将文字映射到其对应的数字上去(encode),也可以将数字映射回对应的文字上(decode)。 诸如GPT-3/4以及LlaMA/LlaMA2大语言模型都采用了token的作为模型的输入输出,其输入是文本,然后将文本转为token(正整数),然后从一串token(对应于文本)预测下一个token。 进入OpenAI官网提供的tokenizer可以看到GPT-3tokenizer采用的方法。这里以Hello World为例说明。...
Deep Learning
2026-03-02

通过卷积和池化等技术可以将图像进行降维,因此,一些研究人员也想办法恢复原分辨率大小的图像,特别是在语义分割领域应用很成熟。 Upsampling(上采样)[没有学习过程] 在FCN、U-net等网络结构中,涉及到了上采样。上采样概念: 上采样指的是任何可以让图像变成更高分辨率的技术 。最简单的方式是 重采样和插值 :将输入图片进行rescale到一个想要的尺寸,而且计算每个点的像素点,使用如双线性插值等插值方法对其余点进行插值来完成上采样过程。 在PyTorch中,上采样的层被封装在 torch.nn 中的 Vision Layers 里面,一共有4种: PixelShuffle Upsample UpsamplingNearest2d UpsamplingBilinear2d PixelShuffle 当stride = (1/r) < 1时,可以让卷积后的feature map变大——即分辨率变大,这个新的操作叫做sub-pixel convolution,具体原理可以看 “PixelShuffle:Real-Time Single Image and Video...
Deep Learning
2026-02-28
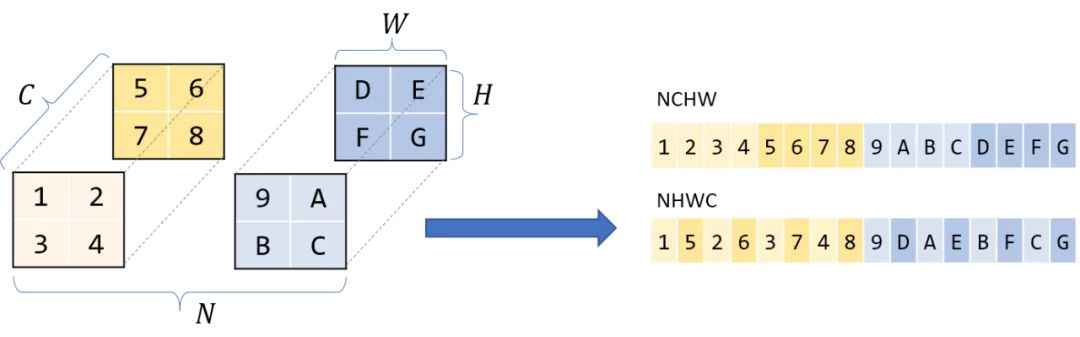
现代深度学习库对大多数操作都具有生产级的、高度优化的实现,这并不奇怪。但这些库究竟是什么魔法?他们如何能够将性能提高100倍?究竟怎样才能“优化”或加速神经网络的运行呢?在讨论高性能/高效DNNs时,我经常会问(也经常被问到)这些问题。 在这篇文章中,我将尝试带你了解在DNN库中卷积层是如何实现的。它不仅是在模型中最常见的和最重的操作,我还发现卷积高性能实现的技巧特别具有代表性——一点点算法的小聪明,非常多的仔细的调优和低层架构的开发。 我在这里介绍的很多内容都来自Goto等人的开创性论文:Anatomy of a high-performance matrix multiplication,该论文为OpenBLAS等线性代数库中使用的算法奠定了基础。 最原始的卷积实现 “过早的优化是万恶之源”——Donald Knuth 在进行优化之前,我们先了解一下基线和瓶颈。这是一个朴素的numpy/for循环卷积: '''
Convolve `input` with `kernel` to generate `output`
input.shape =...
129. 滑动窗口最大值 题目 给你一个整数数组 nums ,有一个大小为 k 的滑动窗口从数组的最左侧移动到数组的最右侧。你只可以看到在滑动窗口内的 k 个数字。滑动窗口每次只向右移动一位。 返回 滑动窗口中的最大值 。 示例 1: 输入:nums = [1,3,-1,-3,5,3,6,7], k = 3
输出:[3,3,5,5,6,7]
解释:
滑动窗口的位置 最大值
--------------- -----
[1 3 -1] -3 5 3 6 7 3
1 [3 -1 -3] 5 3 6 7 3
1 3 [-1 -3 5] 3 6 7 5
1 3 -1 [-3 5 3] 6 7 5
1 3 -1 -3 [5 3 6] 7 6
1 3 -1 -3 5 [3 6 7] 7 示例 2: 输入:nums = [1], k = 1
输出:[1] 提示: 1 <= nums.length...