
Tokenizer 背景与基础 目前的机器学习模型都是数学模型,其对应的输入要求必须是数字形式(number)的,而我们处理的真实场景往往会包含许多非数字形式的输入(有时候即使原始输入是数字形式,我们也需要转换),最典型的就是 NLP 中的文字(string),为了让文字能够作为输入参与到模型的计算中去,我们就需要构建一个映射关系(mapping):将对应的文字映射到一个数字形式上去,而其对应的数字就是 token。而对应的这个映射关系,就是我们的 tokenizer:他可以将文字映射到其对应的数字上去(encode),也可以将数字映射回对应的文字上(decode)。 诸如GPT-3/4以及LlaMA/LlaMA2大语言模型都采用了token的作为模型的输入输出,其输入是文本,然后将文本转为token(正整数),然后从一串token(对应于文本)预测下一个token。 进入OpenAI官网提供的tokenizer可以看到GPT-3tokenizer采用的方法。这里以Hello World为例说明。...
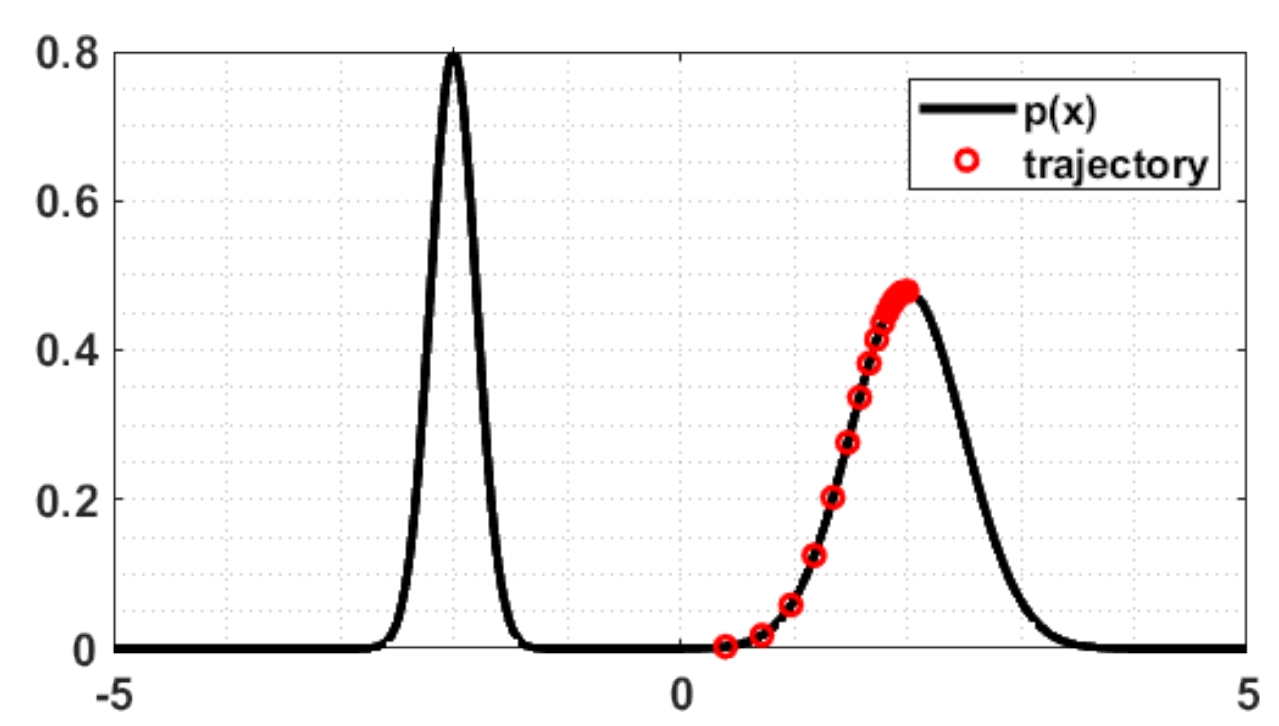
朗之万动力学(Langevin Dynamics)是扩散模型和score matching方法中的采样过程,是文本生成图像中的一个重要步骤。想要洞悉文生图的基本原理,朗之万动力学是绕不开的话题。 朗之万动力学原理简介 本文的主要内容是基于以下教程: Tutorial on Diffusion Models for Imaging and Vision 此教程写的非常好,非常推荐大家学习。教程的语言风格也很亲切,时不时地蹦出诸如“这是地球人能想出来的公式?”这样的话,为你枯燥的学习过程增添些许趣味。 朗之万动力学(Langevin Dynamics)是扩散模型和score matching方法中的采样过程,是文本生成图像中的一个重要步骤。想要洞悉文生图的基本原理,朗之万动力学是绕不开的话题。 给定一个已知的概率分布 \(p(x)\) ,我们的目标是采样出概率密度更大的那些样本。解决这个问题有多种方法,比如生成伪随机均匀分布,然后用概率分布变换的方法;或者用马尔可夫链蒙特卡洛方法(MCMC)。而朗之万动力学给出的方法是这样: 随机选取空间中一个点(这是很简单的,采用高斯生成与 \(x\)...

Hough Voting 本文的标题是Deep Hough Voting,先来说一下Hough Voting。 用Hough变换检测直线大家想必都听过:对于一条直线,可以使用 \((r,θ)\) 两个参数进行描述,那么对于图像中的一点,过这个点的直线有很多条,可以生成一系列的 \((r,θ)\) ,在参数平面内就是一条曲线,也就是说,一个点对应着参数平面内的一个曲线。那如果有很多个点,则会在参数平面内生成很多曲线。那么,如果这些点是能构成一条直线的,那么这条直线的参数 \((r,θ)\) 就在每条曲线中都存在,所以看起来就像是多条曲线相交在 \((r,θ)\) 。可以用多条曲线投票的方式来看,其他点都是很少的票数,而 \((r,θ)\) 则票数很多,所以直线的参数就是 \((r,θ)\) 。 所以Hough变换的思想就是在于,在参数空间内进行投票,投票得数高的就是要得到的值。 文中提到的Hough Voting如下: A traditional Hough voting 2D detector comprises an offline and an online step....
3D Model
2026-02-12

三维深度学习简介 多视角(multi-view):通过多视角二维图片组合为三维物体,此方法将传统CNN应用于多张二维视角的图片,特征被view pooling procedure聚合起来形成三维物体; 体素(volumetric):通过将物体表现为空间中的体素进行类似于二维的三维卷积(例如,卷积核大小为5x5x5),是规律化的并且易于类比二维的,但同时因为多了一个维度出来,时间和空间复杂度都非常高,目前已经不是主流的方法了; 点云(point clouds):直接将三维点云抛入网络进行训练,数据量小。主要任务有分类、分割以及大场景下语义分割; 非欧式(manifold,graph):在流形或图的结构上进行卷积,三维点云可以表现为mesh结构,可以通过点对之间临接关系表现为图的结构。 点云的特性 无序性...

概括 这篇文章将卷积比较自然地拓展到点云的情形,思路很赞! 文章的主要创新点:“weight function”和“density function”,并能实现translation-invariance和permutation-invariance,可以实现层级化特征提取,而且能自然推广到其deconvolution的情形实现分割,在二维CIFAR-10图像分类任务中精度堪比CNN(表明能够充分近似卷积网络),达到了SOTA的性能。 缺点:每个kernel都需要由“kernel function”生成,而“kernel function”实质上是一个CNN网络,计算量比较大。 思想 察觉到:二维卷积中pixel的相对centroid位置与kernel vector的生成方式有关。 以二维卷积为例说明一下如何将卷积拓展到点云。这里只考虑使用一个kernel在一个location的一次卷积操作。 对于二维图像,我们可以将图像的pixels看作是一个点,那么图像就是整齐排列的点阵。每个point都有维度为 \(C_{in}\)...
129. 滑动窗口最大值 题目 给你一个整数数组 nums ,有一个大小为 k 的滑动窗口从数组的最左侧移动到数组的最右侧。你只可以看到在滑动窗口内的 k 个数字。滑动窗口每次只向右移动一位。 返回 滑动窗口中的最大值 。 示例 1: 输入:nums = [1,3,-1,-3,5,3,6,7], k = 3
输出:[3,3,5,5,6,7]
解释:
滑动窗口的位置 最大值
--------------- -----
[1 3 -1] -3 5 3 6 7 3
1 [3 -1 -3] 5 3 6 7 3
1 3 [-1 -3 5] 3 6 7 5
1 3 -1 [-3 5 3] 6 7 5
1 3 -1 -3 [5 3 6] 7 6
1 3 -1 -3 5 [3 6 7] 7 示例 2: 输入:nums = [1], k = 1
输出:[1] 提示: 1 <= nums.length...