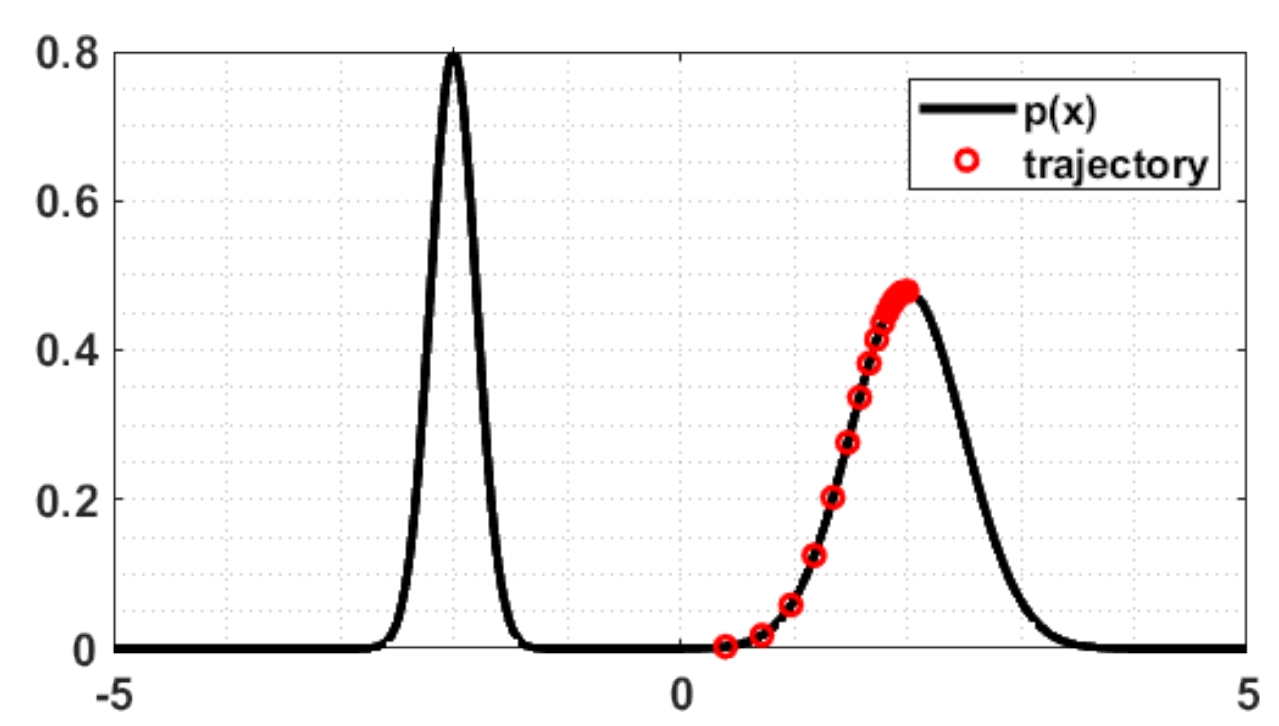
朗之万动力学(Langevin Dynamics)是扩散模型和score matching方法中的采样过程,是文本生成图像中的一个重要步骤。想要洞悉文生图的基本原理,朗之万动力学是绕不开的话题。 朗之万动力学原理简介 本文的主要内容是基于以下教程: Tutorial on Diffusion Models for Imaging and Vision 此教程写的非常好,非常推荐大家学习。教程的语言风格也很亲切,时不时地蹦出诸如“这是地球人能想出来的公式?”这样的话,为你枯燥的学习过程增添些许趣味。 朗之万动力学(Langevin Dynamics)是扩散模型和score matching方法中的采样过程,是文本生成图像中的一个重要步骤。想要洞悉文生图的基本原理,朗之万动力学是绕不开的话题。 给定一个已知的概率分布 \(p(x)\) ,我们的目标是采样出概率密度更大的那些样本。解决这个问题有多种方法,比如生成伪随机均匀分布,然后用概率分布变换的方法;或者用马尔可夫链蒙特卡洛方法(MCMC)。而朗之万动力学给出的方法是这样: 随机选取空间中一个点(这是很简单的,采用高斯生成与 \(x\)...
Machine Learning
2026-03-18

集成学习主要分为以下几类:Bagging,Boosting以及Stacking。 传统机器学习算法 (例如:决策树,人工神经网络,支持向量机,朴素贝叶斯等) 的目标都是寻找一个最优分类器尽可能的将训练数据分开。集成学习 (Ensemble Learning) 算法的基本思想就是将多个分类器组合,从而实现一个预测效果更好的集成分类器。集成算法可以说从一方面验证了中国的一句老话:三个臭皮匠,赛过诸葛亮。 Thomas G. Dietterich 指出了集成算法在统计,计算和表示上的有效原因: 统计上的原因 一个学习算法可以理解为在一个假设空间 H 中选找到一个最好的假设。但是,当训练样本的数据量小到不够用来精确的学习到目标假设时,学习算法可以找到很多满足训练样本的分类器。所以,学习算法选择任何一个分类器都会面临一定错误分类的风险,因此将多个假设集成起来可以降低选择错误分类器的风险。 计算上的原因 很多学习算法在进行最优化搜索时很有可能陷入局部最优的错误中,因此对于学习算法而言很难得到一个全局最优的假设。事实上人工神经网络和决策树已经被证实为是一 个NP...
Machine Learning
2026-03-18

从GBDT到XGBoost 作为GBDT的高效实现,XGBoost是一个上限特别高的算法,因此在算法竞赛中比较受欢迎。简单来说,对比原算法GBDT,XGBoost主要从下面三个方面做了优化: 一是算法本身的优化:在算法的弱学习器模型选择上,对比GBDT只支持决策树,还可以选择很多其他的弱学习器。在算法的损失函数上,除了本身的损失,还加上了正则化部分。在算法的优化方式上,GBDT的损失函数只对误差部分做负梯度(一阶泰勒)展开,而XGBoost损失函数对误差部分做二阶泰勒展开,更加准确。算法本身的优化是我们后面讨论的重点。 二是算法运行效率的优化:对每个弱学习器,比如决策树建立的过程做并行选择,找到合适的子树分裂特征和特征值。在并行选择之前,先对所有的特征的值进行排序分组,方便前面说的并行选择。对分组的特征,选择合适的分组大小,使用CPU缓存进行读取加速。将各个分组保存到多个硬盘以提高IO速度。 三是算法健壮性的优化:对于缺失值的特征,通过枚举所有缺失值在当前节点是进入左子树还是右子树来决定缺失值的处理方式。算法本身加入了L1和L2正则化项,可以防止过拟合,泛化能力更强。...
Machine Learning
2026-03-18
GBDT (Gradient Boosting Decision Tree) 是另一种基于 Boosting 思想的集成算法,除此之外 GBDT 还有很多其他的叫法,例如:GBM (Gradient Boosting Machine),GBRT (Gradient Boosting Regression Tree),MART (Multiple Additive Regression Tree) 等等。GBDT 算法由 3 个主要概念构成:Gradient Boosting (GB),Regression Decision Tree (DT 或 RT) 和 Shrinkage。 Decision Tree:CART回归树 首先,GBDT使用的决策树是CART回归树,无论是处理回归问题还是二分类以及多分类,GBDT使用的决策树通通都是都是CART回归树。为什么不用CART分类树呢?因为GBDT每次迭代要拟合的是 梯度值...
Machine Learning
2026-03-18
分类问题 Adaboost 是 Boosting 算法中有代表性的一个。原始的 Adaboost 算法用于解决二分类问题,因此对于一个训练集 \[T = \{\left(x_1, y_1\right), \left(x_2, y_2\right), ..., \left(x_n, y_n\right)\}\] 其中 \(x_i \in \mathcal{X} \subseteq \mathbb{R}^n, y_i \in \mathcal{Y} = \{-1, +1\}\) ,,首先初始化训练集的权重 \[\begin{aligned}
D_1 =& \left(w_{11}, w_{12}, ..., w_{1n}\right) \\
w_{1i} =& \dfrac{1}{n}, i = 1, 2, ..., n
\end{aligned}\] 根据每一轮训练集的权重 \(D_m\) ,对训练集数据进行抽样得到 \(T_m\) ,再根据 \(T_m\) 训练得到每一轮的基学习器 \(h_m\) 。通过计算可以得出基学习器 \(h_m\) 的误差为 \(e_m\) \[e_m =...
3D Model
2026-02-13

Temporal action detection可以分为两种setting, 一是offline的,在检测时视频是完整可得的,也就是可以利用完整的视频检测动作发生的时间区间(开始时间+结束时间)以及动作的类别; 二是 online的,即处理的是一个视频流,需要在线的检测(or 预测未来)发生的动作类别,但无法知道检测时间点之后的内容。online的问题设定更符合surveillance的需求,需要做实时的检测或者预警;offline的设定更符合视频搜索的需求,比如youtube可能用到的 highlight detection / preview generation。 问题演化 Early action detection -> Online action detection -> Online action anticipation: 在学术界关注online action detection之前,有一个相似的问题叫做 early event detection ,问题定义是 “detect the event as soon as possible, after it...
3D Model
2026-02-12

Classification,Detection Classification:给定预先裁剪好的视频片段,预测其所属的行为类别 Detection:视频是未经过裁剪的,需要先进行人的检测where和行为定位(分析行为的始末时间)when,再进行行为的分类what。 通常所说的行为识别更偏向于对时域预先分割好的序列进行行为动作的分类,即 Trimmed Video Action Classification。 Two-Stream Two-stream convolutional networks 简介 Two-Stream CNN网络顾名思义分为两个部分, 空间流 处理 RGB图像 ,得到形状信息; 时间流/光流 处理 光流图像 ,得到运动信息。 两个流最后经过softmax后,做分类分数的融合,可以采用平均法或者是SVM。不过这两个流都是二维卷积操作。最终联合训练,并分类。 如图所示,其实做法非常的简单,相当于训练两个CNN的分类器。一个是专门对于 RGB 图的, 一个专门对于光流图的, 然后将两者的结果进行一个 fushion 的过程。...
3D Model
2026-02-12

光流(Optical Flow)是物体在三维空间中的运动(运动场)在二维图像平面上的投影,由物体与相机的相对速度产生,反映了微小时间内物体对应的图像像素的运动方向和速度。 KLT 是基于光流原理的一种特征点跟踪算法,本文首先介绍光流原理,然后介绍 KLT 及相关 KLT 变种算法。 Optical Flow 光流法假设: 亮度恒定,图像中物体的像素亮度在连续帧之间不会发生变化; 短距离(短时)运动,相邻帧之间的时间足够短,物体运动较小; 空间一致性,相邻像素具有相似的运动; 记 \(I(x,y,t)\) 为 \(t\) 时刻像素点 \((x,y)\) 的像素值,那么根据前两个假设,可得到: \[I(x,y,t)=I(x+dx,y+dy,t+dt)\] 一阶泰勒展开: \[I(x+dx,y+dy,t+dt)=I(x,y,t)+\frac{\partial I}{\partial x}dx+\frac{\partial I}{\partial y}dy+\frac{\partial I}{\partial t}dt\] 由此可得: \[\frac{\partial I}{\partial...
杂七杂八
2026-01-11
大数据本身是个很宽泛的概念,Hadoop生态圈(或者泛生态圈)基本上都是为了处理超过单机尺度的数据处理而诞生的。你可以把它比作一个厨房所以需要的各种工具。锅碗瓢盆,各有各的用处,互相之间又有重合。你可以用汤锅直接当碗吃饭喝汤,你可以用小刀或者刨子去皮。但是每个工具有自己的特性,虽然奇怪的组合也能工作,但是未必是最佳选择。 大数据,首先你要能存的下大数据 传统的文件系统是单机的,不能横跨不同的机器。HDFS(Hadoop Distributed FileSystem)的设计本质上是为了大量的数据能横跨成百上千台机器,但是你看到的是一个文件系统而不是很多文件系统。比如你说我要获取/hdfs/tmp/file1的数据,你引用的是一个文件路径,但是实际的数据存放在很多不同的机器上。你作为用户,不需要...
杂七杂八
2026-01-11
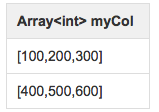
1. explode hive wiki对于expolde的解释如下: explode() takes in an array (or a map) as an input and outputs the elements of the array (map) as separate rows. UDTFs can be used in the SELECT expression list and as a part of LATERAL VIEW. As an example of using explode() in the SELECT expression list, consider a table named myTable that has a single column (m...

Apache Hadoop 是一款支持数据密集型分布式应用程序并以Apache 2.0许可协议发布的开源软件框架。它支持在商用硬件构建的大型集群上运行的应用程序。Hadoop是根据谷歌公司发表的MapReduce 和Google文件系统的论文自行实现而成。所有的Hadoop模块都有一个基本假设,即硬件故障是常见情况,应该由框架自动处理。具体参考官方教程。 Hadoop架构 HDFS: 分布式文件存储 YARN: 分布式资源管理 MapReduce: 分布式计算 Others: 利用YARN的资源管理功能实现其他的数据处理方式 内部各个节点基本都是采用MasterWoker架构 Hadoop HDFS 架构 Block数据块; NameNode Secondary NameNode DataN...