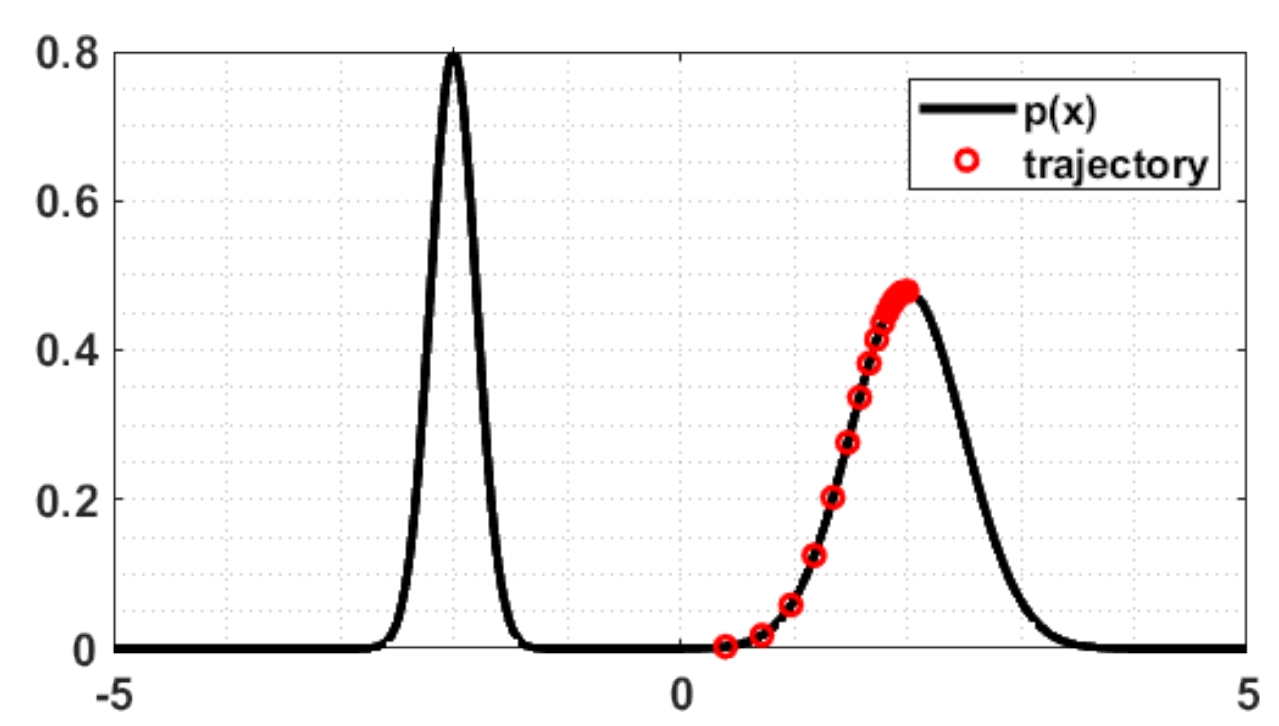
朗之万动力学(Langevin Dynamics)是扩散模型和score matching方法中的采样过程,是文本生成图像中的一个重要步骤。想要洞悉文生图的基本原理,朗之万动力学是绕不开的话题。 朗之万动力学原理简介 本文的主要内容是基于以下教程: Tutorial on Diffusion Models for Imaging and Vision 此教程写的非常好,非常推荐大家学习。教程的语言风格也很亲切,时不时地蹦出诸如“这是地球人能想出来的公式?”这样的话,为你枯燥的学习过程增添些许趣味。 朗之万动力学(Langevin Dynamics)是扩散模型和score matching方法中的采样过程,是文本生成图像中的一个重要步骤。想要洞悉文生图的基本原理,朗之万动力学是绕不开的话题。 给定一个已知的概率分布 \(p(x)\) ,我们的目标是采样出概率密度更大的那些样本。解决这个问题有多种方法,比如生成伪随机均匀分布,然后用概率分布变换的方法;或者用马尔可夫链蒙特卡洛方法(MCMC)。而朗之万动力学给出的方法是这样: 随机选取空间中一个点(这是很简单的,采用高斯生成与 \(x\)...
Computer Vision
2026-02-26
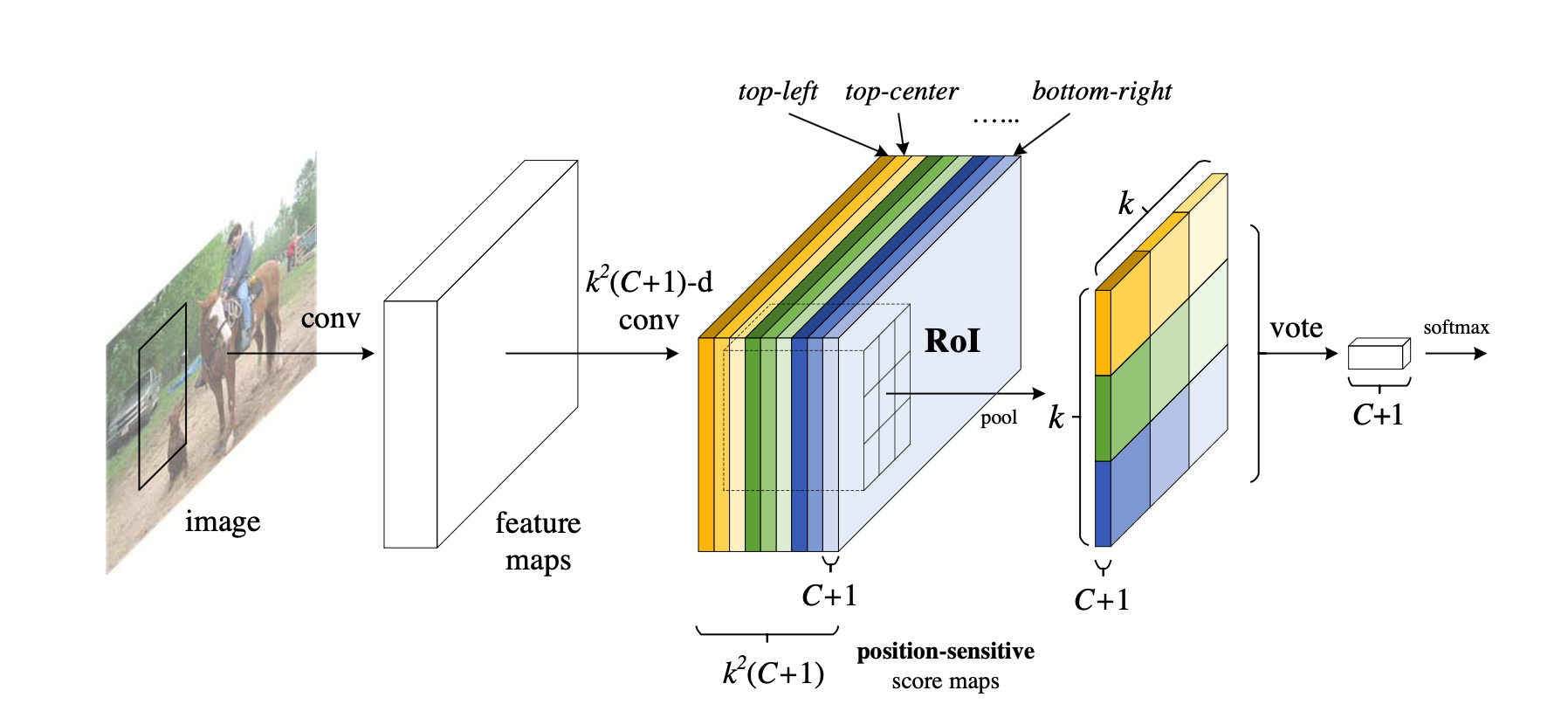
动机 Faster R-CNN是首个利用CNN来完成proposals的预测的,之后的很多目标检测网络都是借助了Faster R-CNN的思想。而Faster R-CNN系列的网络都可以分成2个部分: Fully Convolutional subnetwork before RoI Layer RoI-wise subnetwork 第1部分就是直接用普通分类网络的卷积层,用其来提取共享特征,然后一个RoI Pooling Layer在第1部分的最后一张特征图上进行提取针对各个RoIs的特征向量(或者说是特征图,维度变换一下即可),然后将所有RoIs的特征向量都交由第2部分来处理(分类和回归),而第二部分一般都是一些全连接层,在最后有2个并行的loss函数:softmax和smoothL1,分别用来对每一个RoI进行分类和回归,这样就可以得到每个RoI的真实类别和较为精确的坐标和长宽了。...
Computer Vision
2026-02-26
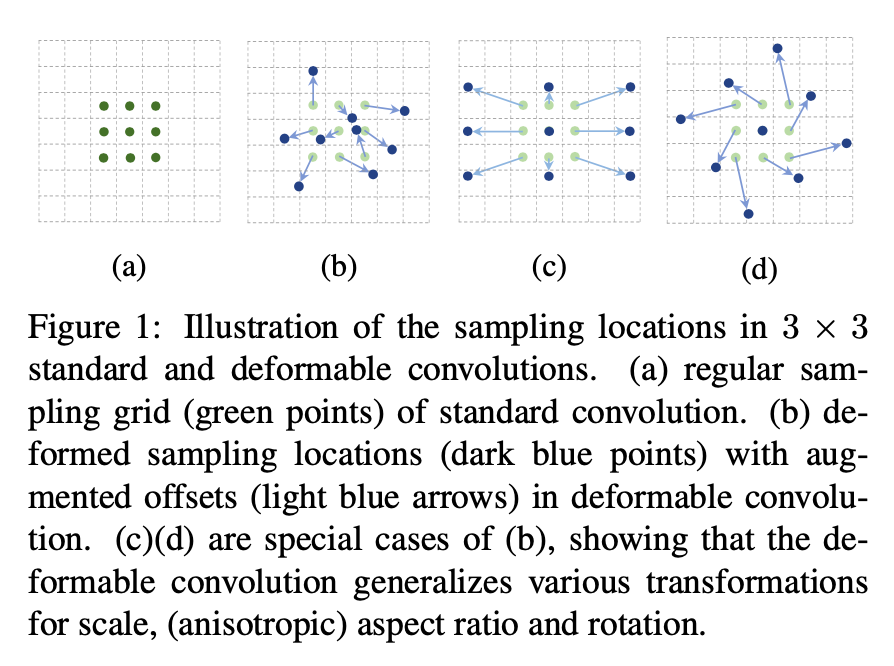
Deformable Conv v1 这篇文章其实比较老了,是 2017 年 5 月出的 Motivation Task 上的难点 视觉任务中一个难点就是如何 model 物体的几何变换,比如由于物体大小,pose, viewpoint 引起的。一般有两类做法: 在数据集上做文章,让 training dataset 就包含所有可能的集合变换。通过 affine transformation 去做 augmentation 另一种就是设计 transformation-invariant (对那些几何变换不变)的 feature 和算法。比如 SIFT 和 sliding window 的方式。 文章说上述两种方式有问题,几何变换我们是事先知道的,这种不能 generalize 到其它场景和任务中。以及 hand-crafted 的设计适应不了负责场景。 CNN 的缺陷 对于geometric transformation 的问题,目前的 CNN 主要是通过 data augmentation 和一些手工设计,比如 max-pooling 解决的(max-pooling...
3D Model
2026-02-13

Temporal action detection可以分为两种setting, 一是offline的,在检测时视频是完整可得的,也就是可以利用完整的视频检测动作发生的时间区间(开始时间+结束时间)以及动作的类别; 二是 online的,即处理的是一个视频流,需要在线的检测(or 预测未来)发生的动作类别,但无法知道检测时间点之后的内容。online的问题设定更符合surveillance的需求,需要做实时的检测或者预警;offline的设定更符合视频搜索的需求,比如youtube可能用到的 highlight detection / preview generation。 问题演化 Early action detection -> Online action detection -> Online action anticipation: 在学术界关注online action detection之前,有一个相似的问题叫做 early event detection ,问题定义是 “detect the event as soon as possible, after it...
3D Model
2026-02-12

Classification,Detection Classification:给定预先裁剪好的视频片段,预测其所属的行为类别 Detection:视频是未经过裁剪的,需要先进行人的检测where和行为定位(分析行为的始末时间)when,再进行行为的分类what。 通常所说的行为识别更偏向于对时域预先分割好的序列进行行为动作的分类,即 Trimmed Video Action Classification。 Two-Stream Two-stream convolutional networks 简介 Two-Stream CNN网络顾名思义分为两个部分, 空间流 处理 RGB图像 ,得到形状信息; 时间流/光流 处理 光流图像 ,得到运动信息。 两个流最后经过softmax后,做分类分数的融合,可以采用平均法或者是SVM。不过这两个流都是二维卷积操作。最终联合训练,并分类。 如图所示,其实做法非常的简单,相当于训练两个CNN的分类器。一个是专门对于 RGB 图的, 一个专门对于光流图的, 然后将两者的结果进行一个 fushion 的过程。...
3D Model
2026-02-12

光流(Optical Flow)是物体在三维空间中的运动(运动场)在二维图像平面上的投影,由物体与相机的相对速度产生,反映了微小时间内物体对应的图像像素的运动方向和速度。 KLT 是基于光流原理的一种特征点跟踪算法,本文首先介绍光流原理,然后介绍 KLT 及相关 KLT 变种算法。 Optical Flow 光流法假设: 亮度恒定,图像中物体的像素亮度在连续帧之间不会发生变化; 短距离(短时)运动,相邻帧之间的时间足够短,物体运动较小; 空间一致性,相邻像素具有相似的运动; 记 \(I(x,y,t)\) 为 \(t\) 时刻像素点 \((x,y)\) 的像素值,那么根据前两个假设,可得到: \[I(x,y,t)=I(x+dx,y+dy,t+dt)\] 一阶泰勒展开: \[I(x+dx,y+dy,t+dt)=I(x,y,t)+\frac{\partial I}{\partial x}dx+\frac{\partial I}{\partial y}dy+\frac{\partial I}{\partial t}dt\] 由此可得: \[\frac{\partial I}{\partial...
Self-Supervised
2026-01-23

如果把 近几年对比学习在视觉领域有代表性的工作做一下总结,那么对比学习的发展历程大概可以分为四个阶段: 百花齐放 这个阶段代表性工作有InstDisc(instance discrimination,)、CPC、CMC等。在这个阶段中,方法、模型、目标函数、代理任务都还没有统一,所以说是一个百花齐放的时代 CV双雄 代表作有MoCo v1、SimCLR v1、MoCo v2、SimCLR v2;CPC、CMC的延伸工作、SwAV等。这个阶段发展非常迅速,有的工作间隔甚至不到一个月,ImageNet上的成绩基本上每个月都在被刷新。 不用负样本 BYOL及其改进工作、SimSiam(CNN在对比学习中的总结性工作) transformer MoCo v3、DINO。这个阶段,无论是对比学习还是最新的掩码学习,都是用Vision Transformer做的。 第一阶段:百花齐放(2018-2019Mid) InstDisc(instance discrimination) 这篇文章提出了个体判别任务(代理任务)以及 memory bank ,非常经典,后人给它的方法起名为InstDisc。...
Self-Supervised
2026-01-23
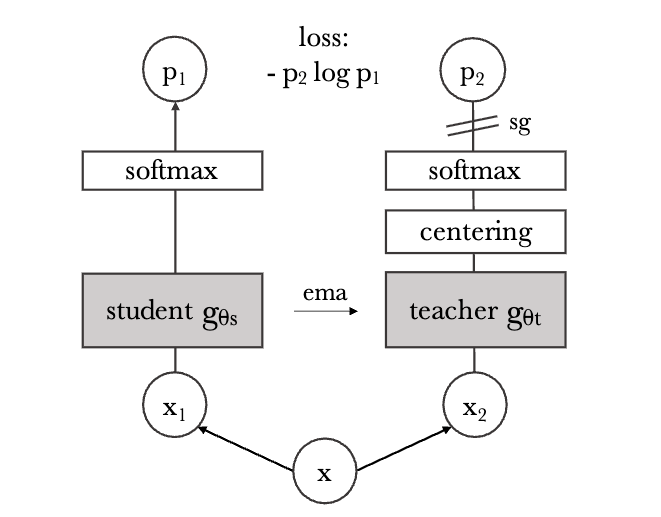
DINO Emerging Properties in Self-Supervised Vision Transformers 论文地址: arxiv.org/pdf/2104.14294 DINO摇摆到了动量式更新,果然【加动量】还是比【只用梯度停止】香。DINO的名字来自于Self- di stillation with no labels中的蒸馏和No标签。 DINO的训练步骤 其实以前的对比学习方案也可以理解为知识蒸馏,DINO里更具体得描述了知识蒸馏的含义。 下图展示了一个样本通过数据增强得到一对views \((x_1,x_2)\) 。注意DINO后面还会使用更复杂的裁剪和对比方案,但这里简单起见先不考虑那些。模型将输入图像的两种不同的随机变换 \(x_1\) 和 \(x_2\) 分别传递给学生和教师网络。 这两个网络具有相同的架构,但参数不同 。教师网络的输出以batch内计算的平均值,进行中心化(减去均值)。每个网络输出一个 \(K\)...
Self-Supervised
2026-01-23
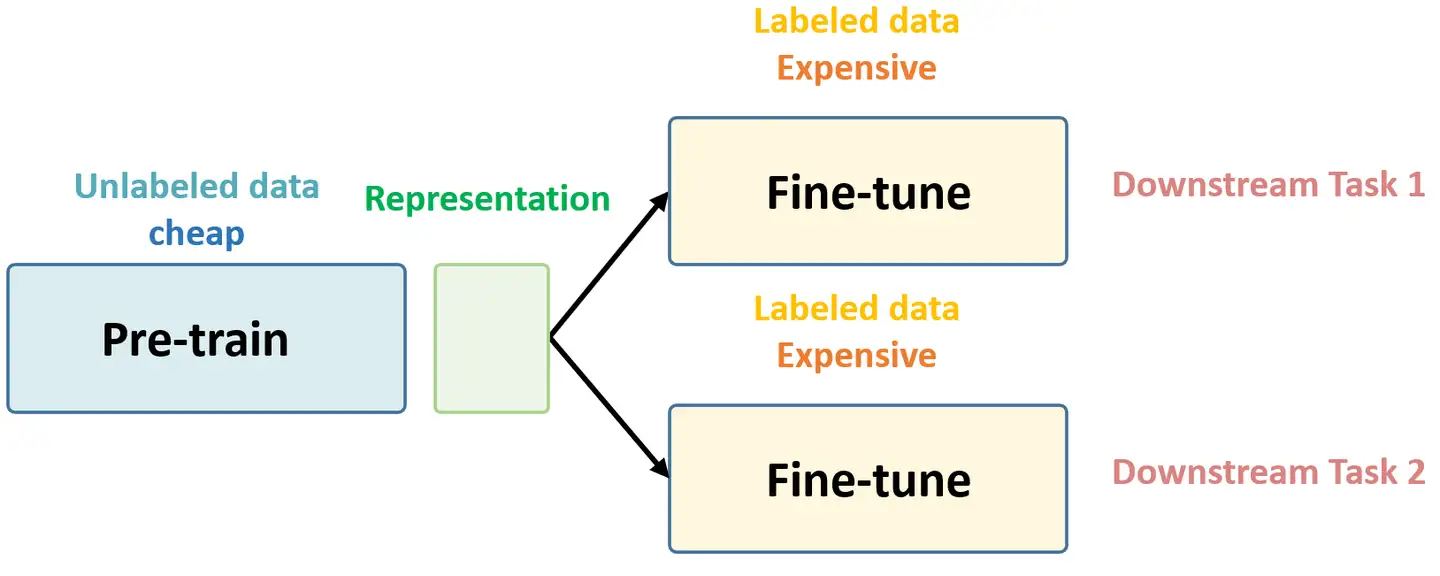
Self-Supervised Learning ,又称为自监督学习,我们知道一般机器学习分为有监督学习,无监督学习和强化学习。 而 Self-Supervised Learning 是无监督学习里面的一种,主要是希望能够学习到一种 通用的特征表达 用于 下游任务 (Downstream Tasks) 。 其主要的方式就是通过自己监督自己。作为代表作的 kaiming 的 MoCo 引发一波热议, Yann Lecun也在 AAAI 上讲 Self-Supervised Learning 是未来的大势所趋。所以在这个系列中,我会系统地解读 Self-Supervised Learning 的经典工作。 总结下 Self-Supervised Learning 的方法,用 4 个英文单词概括一下就是: Unsupervised Pre-train, Supervised Fine-tune. 这段话先放在这里,可能你现在还不一定完全理解,后面还会再次提到它。 在预训练阶段我们使用 无标签的数据集 (unlabeled data) ,因为有标签的数据集 很贵...
Self-Supervised
2026-01-23
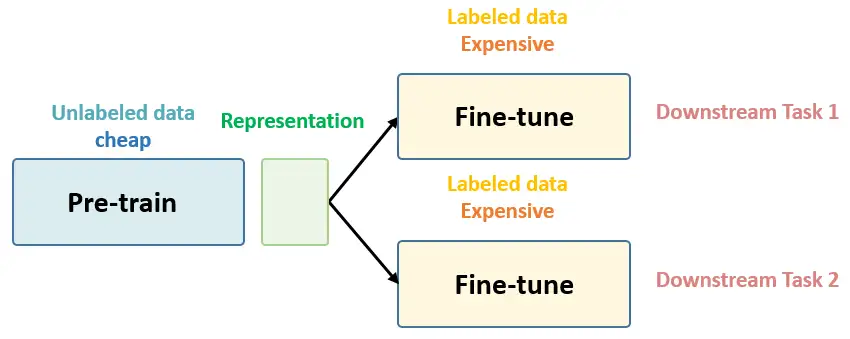
总结下 Self-Supervised Learning 的方法,用 4 个英文单词概括一下就是: Unsupervised Pre-train, Supervised Fine-tune. 在预训练阶段我们使用 无标签的数据集 (unlabeled data) ,因为有标签的数据集 很贵 ,打标签得要多少人工劳力去标注,那成本是相当高的,所以这玩意太贵。相反,无标签的数据集网上随便到处爬,它 便宜 。在训练模型参数的时候,我们不追求把这个参数用带标签数据从 初始化的一张白纸 给一步训练到位,原因就是数据集太贵。于是 Self-Supervised Learning 就想先把参数从 一张白纸 训练到 初步成型 ,再从 初步成型 训练到 完全成型 。注意这是2个阶段。这个 训练到初步成型的东西 ,我们把它叫做 Visual Representation 。预训练模型的时候,就是模型参数从 一张白纸 到 初步成型 的这个过程,还是用无标签数据集。等我把模型参数训练个八九不离十,这时候再根据你 下游任务 (Downstream Tasks) 的不同去用带标签的数据集把参数训练到 完全成型...
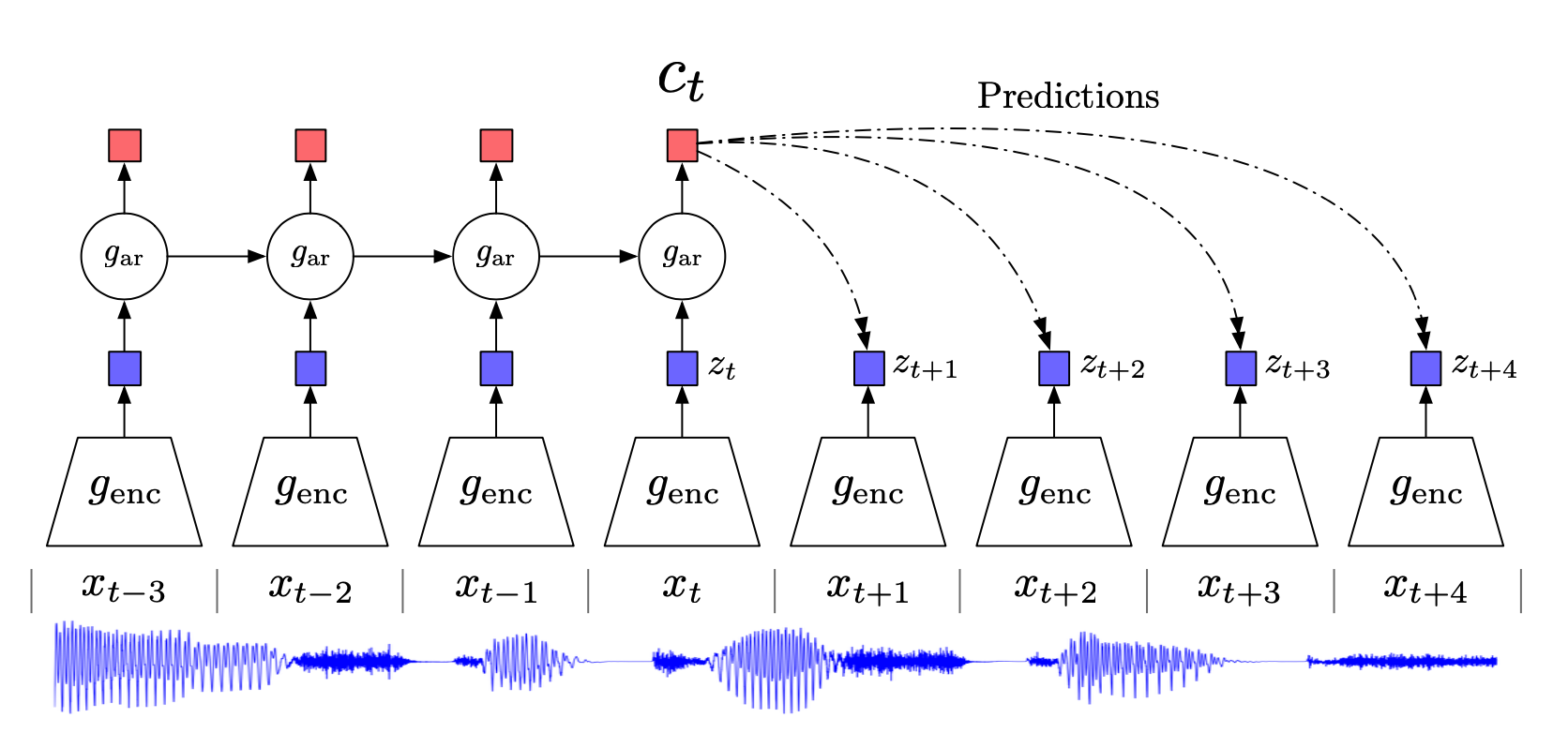
补充知识 表示学习 (Representation Learning): 学习数据的表征,以便在构建分类器或其他预测器时更容易提取有用的信息 ,无监督学习也属于表示学习。 互信息 (Mutual Information):表示两个变量 \(X\) 和 \(Y\) 之间的关系,定义为: \[I(X;Y)=\sum_{x\in X}\sum_{y\in Y}p(x,y)log\frac{p(x|y)}{p(x)}\] 对比损失(contrastive loss) :计算成对样本的匹配程度,主要用于降维中。计算公式为: \[L=\frac{1}{2N}\sum_{n-1}^N[yd^2+(1-y)max(margin-d, 0)^2]\] 其中, \(d=\sqrt{(a_n-b_n)^2}\) 为两个样本的欧式距离, \(y=\{0,1\}\) 代表两个样本的匹配程度, \(margin\) 代表设定的阈值。这种损失函数可以很好的表达成对样本的匹配程度,也能够很好用于训练提取特征的模型。当 \( y=1\) (即样本相似)时,损失函数只剩下 \(∑d^2\)...
Self-Supervised
2026-01-23

从 NLP 入手 n-gram 语言模型(language model)就是假设一门语言所有可能的句子服从一个概率分布,每个句子出现的概率加起来是1,那么语言模型的任务就是预测每个句子在语言中出现的概率。如果把句子 \(s\) 看成单词 \(w\) 的序列 \(s=\{w_1,w_2,...,w_m\}\) ,那么语言模型就是建模一个 \(p(w_1,w_2,...,w_m)\) 来计算这个句子 \(s\) 出现的概率,直观上我们要得到这个语言模型,基于链式法则可以表示为每个单词出现的条件概率的乘积,我们将条件概率的条件 \((w_1,w_2,...,w_{i-1})\) 称为单词 \(w_i\) 的上下文,用 \(c_i\) 表示。 \[\begin{aligned} p\left(w_{1}, w_{2}, \ldots, w_{m}\right)&=p\left(w_{1}\right) * p\left(w_{2} \mid w_{1}\right) * p\left(w_{3} \mid w_{1}, w_{2}\right) \ldots p\left(w_{m}...