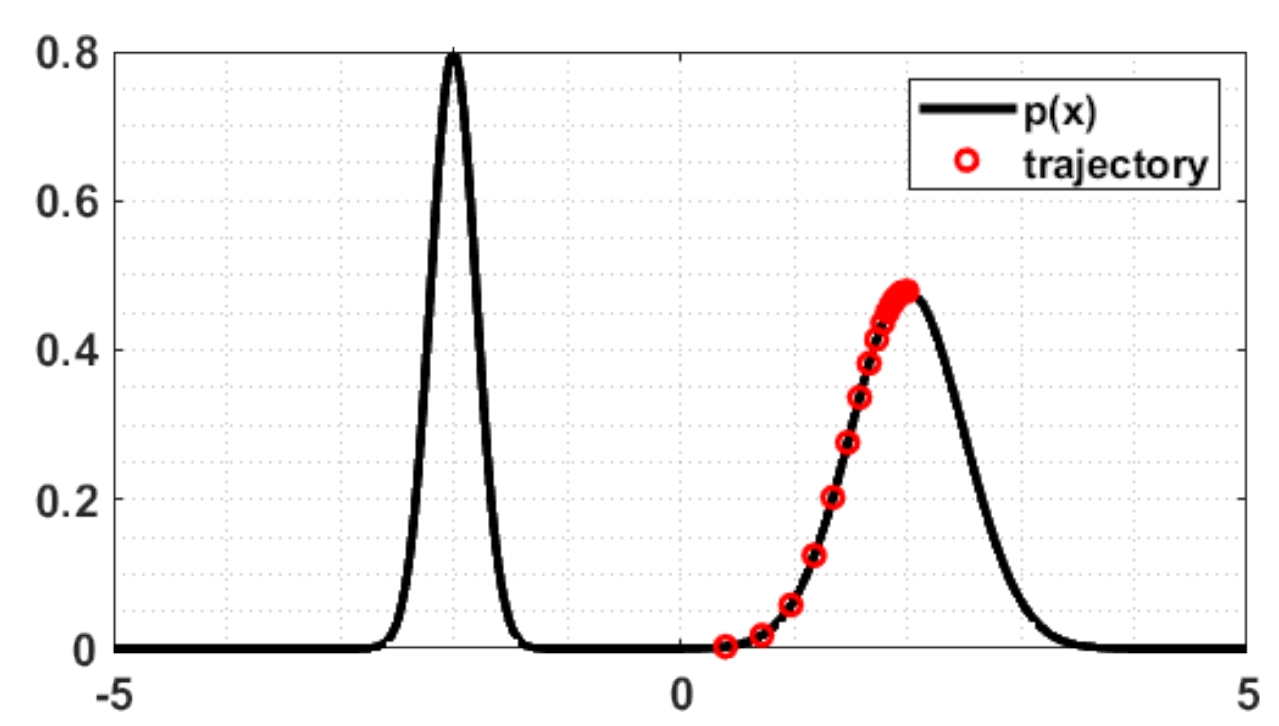
朗之万动力学(Langevin Dynamics)是扩散模型和score matching方法中的采样过程,是文本生成图像中的一个重要步骤。想要洞悉文生图的基本原理,朗之万动力学是绕不开的话题。 朗之万动力学原理简介 本文的主要内容是基于以下教程: Tutorial on Diffusion Models for Imaging and Vision 此教程写的非常好,非常推荐大家学习。教程的语言风格也很亲切,时不时地蹦出诸如“这是地球人能想出来的公式?”这样的话,为你枯燥的学习过程增添些许趣味。 朗之万动力学(Langevin Dynamics)是扩散模型和score matching方法中的采样过程,是文本生成图像中的一个重要步骤。想要洞悉文生图的基本原理,朗之万动力学是绕不开的话题。 给定一个已知的概率分布 \(p(x)\) ,我们的目标是采样出概率密度更大的那些样本。解决这个问题有多种方法,比如生成伪随机均匀分布,然后用概率分布变换的方法;或者用马尔可夫链蒙特卡洛方法(MCMC)。而朗之万动力学给出的方法是这样: 随机选取空间中一个点(这是很简单的,采用高斯生成与 \(x\)...
Computer Vision
2026-02-27

Segment Anything Segment Anything(SA)项目:一个用于图像分割的新任务、新模型和新数据集 通过FM(基础模型)+prompt解决了CV中难度较大的分割任务,给计算机视觉实现基础模型+提示学习+指令学习提供了一种思路 关键:加大模型容量(构造海量的训练数据,或者构造合适的自监督任务来预训练) Segment Anything Task SAM的一部分灵感是来源于NLP中的基座模型(Foundation Model),Foundation Model是OpenAI提出的一个概念,它指的是在超大量数据集上预训练过的大模型(如GPT系列、BERT),这些模型具有非常强大的 zero-shot 和 few-shot能力,结合prompt engineering和fine tuning等技术可以将基座模型应用在各种下游任务中并实现惊人的效果。 SAM就是想构建一个这样的图像分割基座模型,即使是一个未见过的数据集,模型也能自动或半自动(基于prompt)地完成下游的分割任务。为了实现这个目标,SAM定义了一种可提示化的分割任务(promptable...
Computer Vision
2026-02-27

空洞卷积 Dilated/Atrous Convolution 或者是 Convolution with holes 从字面上就很好理解,是在标准的 convolution map 里注入空洞,以此来增加 reception field。相比原来的正常convolution,dilated convolution 多了一个 hyper-parameter 称之为 dilation rate 指的是kernel的间隔数量(e.g. 正常的 convolution 是 dilatation rate 1)。 一个简单的例子 一维情况下空洞卷积的公式如下 \[y[i]=\sum_{k=1}^Kx[i+r\cdot k]w[k]\] 不过光理解他的工作原理还是远远不够的,要充分理解这个概念我们得重新审视卷积本身,并去了解他背后的设计直觉。以下主要讨论 dilated convolution 在语义分割 (semantic segmentation) 的应用。 重新思考卷积: Rethinking Convolution...
3D Model
2026-02-12
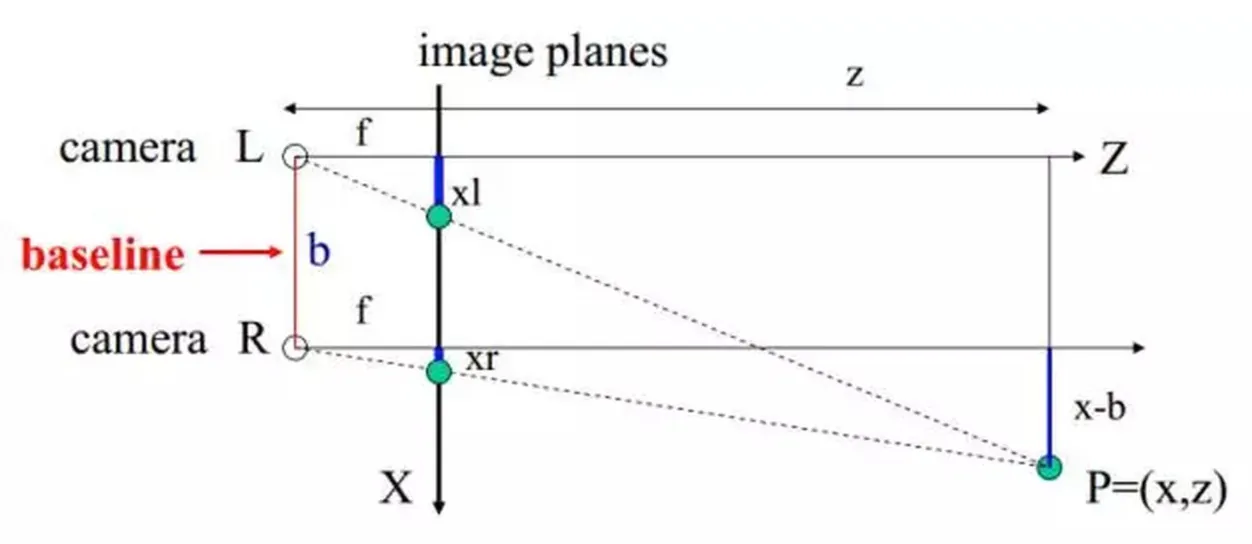
深度相机 “工欲善其事必先利其器‘’我们先从能够获取RGBD数据的相机开始谈起。首先我们来看一看其分类。 根据其工作原理主要分为三类: 1.双目方案 基于双目立体视觉的深度相机类似人类的双眼,和基于TOF、结构光原理的深度相机不同,它不对外主动投射光源,完全依靠拍摄的两张图片(彩色RGB或者灰度图)来计算深度,因此有时候也被称为被动双目深度相机。比较知名的产品有STEROLABS 推出的 ZED 2K Stereo Camera和Point Grey 公司推出的 BumbleBee。 双目立体视觉是基于视差原理,由多幅图像获取物体三维几何信息的方法。在机器视觉系统中, 双目视觉一般由双摄像机从不同角度同时获取周围景物的两幅数字图像,或有由单摄像机在不同时刻从不同角度获取周围景物的两幅数字图像 ,并基于视差原理即可恢复出物体三维几何信息,重建周围景物的三维形状与位置。 双目视觉有的时候我们也会把它称为体视,是人类利用双眼获取环境三维信息的主要途径。从目前来看,随着机器视觉理论的发展,双目立体视觉在机器视觉研究中发回来看了越来越重要的作用 为什么非得用双目相机才能得到深度?...
3D Model
2026-02-12
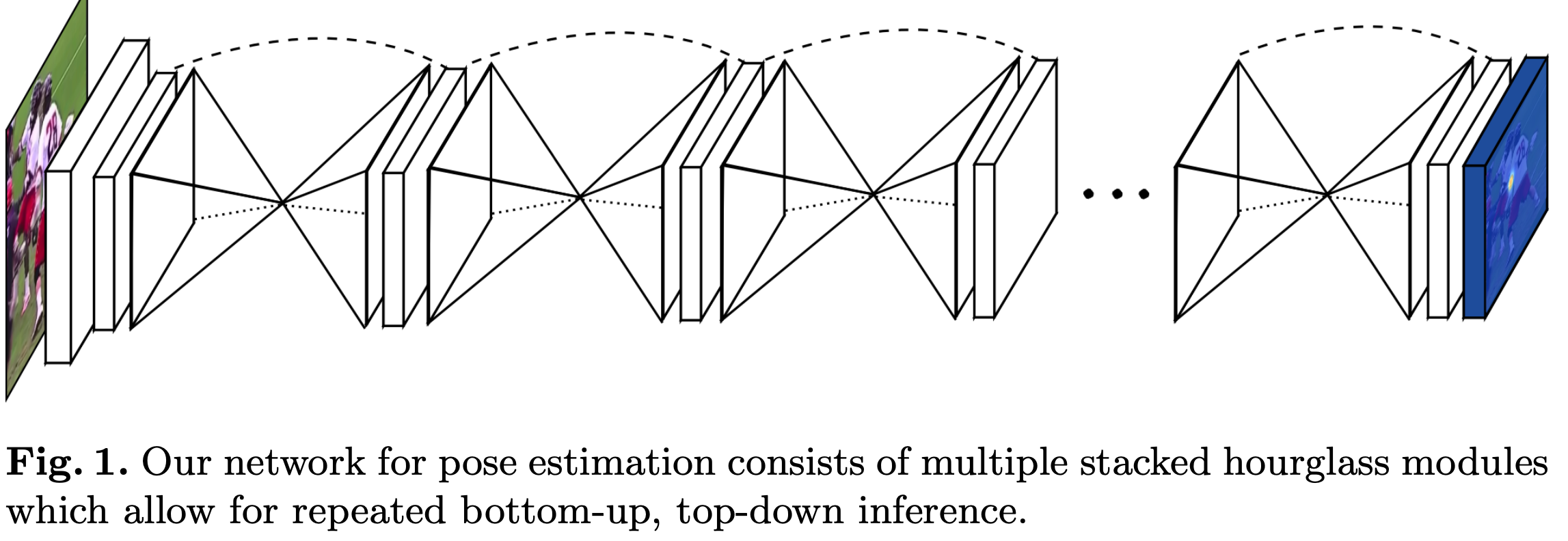
论文介绍了一种新的网络结构用于人体姿态检测,作者在论文中展现了不断重复bottom-up、top-down过程以及运用intermediate supervison(中间监督)对于网络性能的提升,下面来介绍Stacked Hourglass Networks. 简介 理解人类的姿态对于一些高级的任务比如行为识别来说特别重要,而且也是一些人机交互任务的基础。作者提出了一种新的网络结构Stacked Hourglass Networks来对人体的姿态进行识别,这个网络结构能够捕获并整合图像所有尺度的信息。之所以称这种网络为Stacked Hourglass Networks,主要是它长得很像堆叠起来的沙漏,如下图所示: 这种堆叠在一起的Hourglass模块结构是对称的,bottom-up过程将图片从高分辨率降到低分辨率,top-down过程将图片从低分辨率升到高分辨率,这种网络结构包含了许多pooling和upsampling的步骤,pooling可以将图片降到一个很低的分辨率,upsampling可以结合多个分辨率的特征。 下面介绍具体的网络结构。 Hourglass Module...
3D Model
2026-02-12
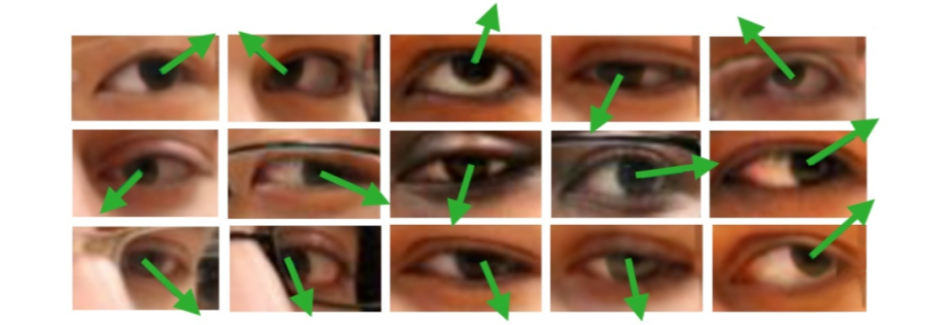
概述 问题定义 广义的 Gaze Estimation 泛指与眼球、眼动、视线等相关的研究,因此有不少做 saliency 和 egocentric 的论文也以 gaze 为关键词。而本文介绍的 Gaze Estimation 主要以眼睛图像或人脸图像为处理对象,估算人的视线方向或注视点位置, 如下图所示。 gaze角度的表示一般使用一个3d向量作为表示,也可以转换为pitch 和yaw角度,具体可参考 欧拉角、旋转矩阵、旋转向量、四元数 Model Gaze模型一般使用回归模型,所以这里基本只介绍一些在gaze model中使用的小技巧 Rle Loss RLE Loss 实际问题 Gaze采集标定方案
3D Model
2026-02-12
整体流程 # 文件夹biaoding处理加crop以及生成.yml系列文件,保存在calib_params以及biaoding_pipeline文件夹中
0_test_calibprocess.sh
# 内参标定,往往需要多天数据,且要保证标定板出现的多样性以及cover大部分区域
1_calib_intrics.sh
# 外参标定,使用混合的内参对单天数据进行外参标定,最好loss在0.000x
1_calib_extrics.sh
# 修改anchor.yaml相机信息进行15标定,loss 100以下,A88参考为50左右
2_test_merge.sh
# 选择数据送标anchor,返回后, loss 0.00x, 不准基本就是anchor标错或者方向盘等位置发生运动
python tools/display_tags.py --anchor_path /mnt/.../anchor
3_test_anchors.sh
# 检查anchor的3d位置是否正确
# 首先根据点位加入颜色
python 3_addcolor_anchor.py
#...

论文地址: https://arxiv.org/pdf/2107.11291 代码地址: https://github.com/Jeff-sjtu/res-loglikelihood-regression 前言 一般来说, 我们可以把姿态估计任务分成两个流派:Heatmap-based和Regression-based。 其主要区别在于监督信息的不同,Heatmap-based方法监督模型学习的是高斯概率分布图,即把GroundTruth中每个点渲染成一张高斯热图,最后网络输出为K张特征图对应K个关键点,然后通过argmax或soft-argmax来获取最大值点作为估计结果。这种方法由于需要渲染高斯热图,且由于热图中的最值点直接对应了结果,不可避免地需要维持一个相对高分辨率的热图(常见的是64x64,再小的话误差下界过大会造成严重的精度损失),因此也就自然而然导致了很大的计算量和内存开销。 Regression-based方法则非常简单粗暴,直接监督模型学习坐标值,计算坐标值的L1或L2...

Hough Voting 本文的标题是Deep Hough Voting,先来说一下Hough Voting。 用Hough变换检测直线大家想必都听过:对于一条直线,可以使用 \((r,θ)\) 两个参数进行描述,那么对于图像中的一点,过这个点的直线有很多条,可以生成一系列的 \((r,θ)\) ,在参数平面内就是一条曲线,也就是说,一个点对应着参数平面内的一个曲线。那如果有很多个点,则会在参数平面内生成很多曲线。那么,如果这些点是能构成一条直线的,那么这条直线的参数 \((r,θ)\) 就在每条曲线中都存在,所以看起来就像是多条曲线相交在 \((r,θ)\) 。可以用多条曲线投票的方式来看,其他点都是很少的票数,而 \((r,θ)\) 则票数很多,所以直线的参数就是 \((r,θ)\) 。 所以Hough变换的思想就是在于,在参数空间内进行投票,投票得数高的就是要得到的值。 文中提到的Hough Voting如下: A traditional Hough voting 2D detector comprises an offline and an online step....
3D Model
2026-02-12

三维深度学习简介 多视角(multi-view):通过多视角二维图片组合为三维物体,此方法将传统CNN应用于多张二维视角的图片,特征被view pooling procedure聚合起来形成三维物体; 体素(volumetric):通过将物体表现为空间中的体素进行类似于二维的三维卷积(例如,卷积核大小为5x5x5),是规律化的并且易于类比二维的,但同时因为多了一个维度出来,时间和空间复杂度都非常高,目前已经不是主流的方法了; 点云(point clouds):直接将三维点云抛入网络进行训练,数据量小。主要任务有分类、分割以及大场景下语义分割; 非欧式(manifold,graph):在流形或图的结构上进行卷积,三维点云可以表现为mesh结构,可以通过点对之间临接关系表现为图的结构。 点云的特性 无序性...

概括 这篇文章将卷积比较自然地拓展到点云的情形,思路很赞! 文章的主要创新点:“weight function”和“density function”,并能实现translation-invariance和permutation-invariance,可以实现层级化特征提取,而且能自然推广到其deconvolution的情形实现分割,在二维CIFAR-10图像分类任务中精度堪比CNN(表明能够充分近似卷积网络),达到了SOTA的性能。 缺点:每个kernel都需要由“kernel function”生成,而“kernel function”实质上是一个CNN网络,计算量比较大。 思想 察觉到:二维卷积中pixel的相对centroid位置与kernel vector的生成方式有关。 以二维卷积为例说明一下如何将卷积拓展到点云。这里只考虑使用一个kernel在一个location的一次卷积操作。 对于二维图像,我们可以将图像的pixels看作是一个点,那么图像就是整齐排列的点阵。每个point都有维度为 \(C_{in}\)...
3D Model
2026-01-30

三维空间中的旋转有很多种表示方式,欧拉角,旋转矩阵,旋转向量,四元数。由于在slam与机器人中会大量用到这方面的知识,所以在这里将此方面的知识总结一下,方便以后查阅。 欧拉角(Euler Angle) 欧拉角可以使用滑翔翼飞行器控制来理解,比如对于下面这张图,一般假设红色轴为z轴,则z轴表示空间的第三维,则去掉这一维度表示飞行器在一个二维平面上;蓝色轴为x轴,也是飞行器的朝向,因此绕此轴转动就像是飞行器在做翻滚动作,因此叫翻滚角(roll);绿色轴为y轴,绕这个轴转动其实就是飞机开始准备向上飞或者向下飞了,因此叫俯仰角(pitch);同理,绕红色轴也就是z轴转动代表飞机开始调整自身在二维平面上的朝向了,因此叫偏航角(yaw)。 在欧拉角的表示中,yaw、pitch、roll的顺序对旋转结果是有影响的。即 给定一组欧拉角角度值,比如yaw=45度,pitch=30度,roll=60度,按照yaw-pitch-roll的顺序旋转和按照yaw-roll-pitch的顺序旋转,最终刚体的朝向是不同的! 换言之,若刚体需要按照两种不同的旋转顺序旋转到相同的朝向,所需要的欧拉角角度值则是不同的!...