
Tokenizer 背景与基础 目前的机器学习模型都是数学模型,其对应的输入要求必须是数字形式(number)的,而我们处理的真实场景往往会包含许多非数字形式的输入(有时候即使原始输入是数字形式,我们也需要转换),最典型的就是 NLP 中的文字(string),为了让文字能够作为输入参与到模型的计算中去,我们就需要构建一个映射关系(mapping):将对应的文字映射到一个数字形式上去,而其对应的数字就是 token。而对应的这个映射关系,就是我们的 tokenizer:他可以将文字映射到其对应的数字上去(encode),也可以将数字映射回对应的文字上(decode)。 诸如GPT-3/4以及LlaMA/LlaMA2大语言模型都采用了token的作为模型的输入输出,其输入是文本,然后将文本转为token(正整数),然后从一串token(对应于文本)预测下一个token。 进入OpenAI官网提供的tokenizer可以看到GPT-3tokenizer采用的方法。这里以Hello World为例说明。...
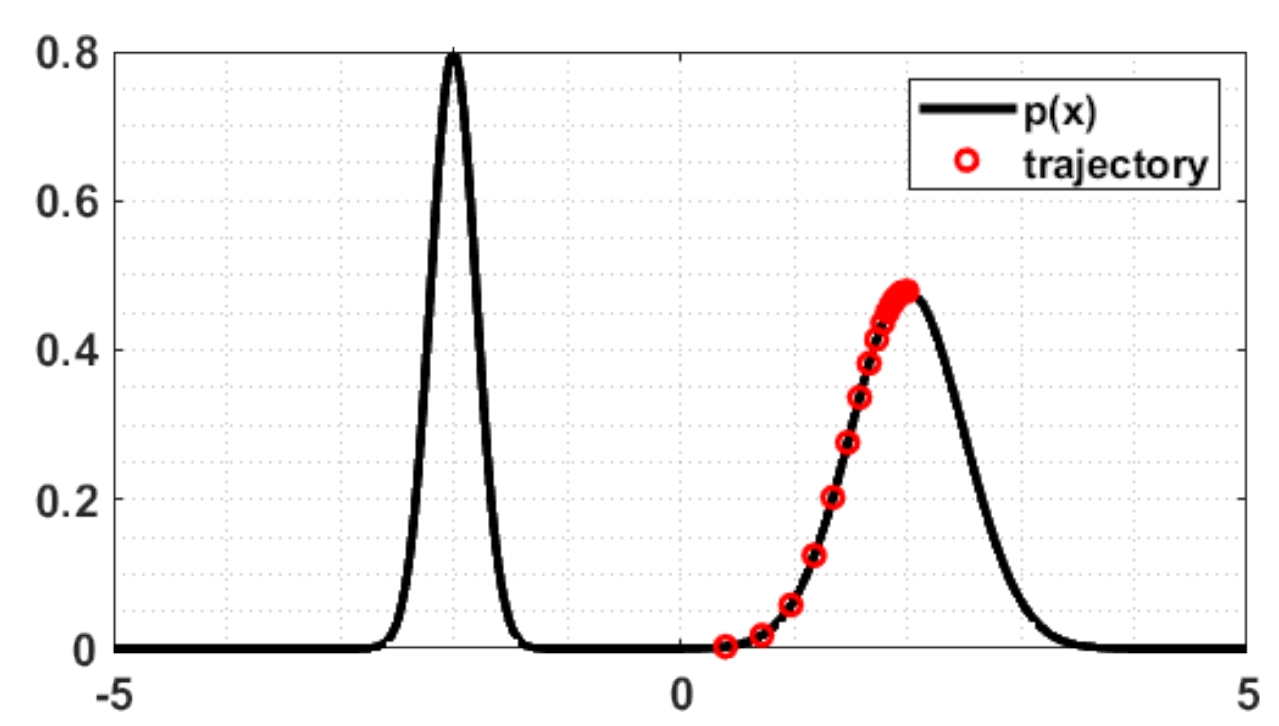
朗之万动力学(Langevin Dynamics)是扩散模型和score matching方法中的采样过程,是文本生成图像中的一个重要步骤。想要洞悉文生图的基本原理,朗之万动力学是绕不开的话题。 朗之万动力学原理简介 本文的主要内容是基于以下教程: Tutorial on Diffusion Models for Imaging and Vision 此教程写的非常好,非常推荐大家学习。教程的语言风格也很亲切,时不时地蹦出诸如“这是地球人能想出来的公式?”这样的话,为你枯燥的学习过程增添些许趣味。 朗之万动力学(Langevin Dynamics)是扩散模型和score matching方法中的采样过程,是文本生成图像中的一个重要步骤。想要洞悉文生图的基本原理,朗之万动力学是绕不开的话题。 给定一个已知的概率分布 \(p(x)\) ,我们的目标是采样出概率密度更大的那些样本。解决这个问题有多种方法,比如生成伪随机均匀分布,然后用概率分布变换的方法;或者用马尔可夫链蒙特卡洛方法(MCMC)。而朗之万动力学给出的方法是这样: 随机选取空间中一个点(这是很简单的,采用高斯生成与 \(x\)...
Generative Model
2026-03-04
Score based generative model SMLD的关键点: 以多个不同量级的噪声对数据进行扰动,并训练一个分数网络来估计不同噪声下的分数 加噪的量级有大有小,都是在原始数据上进行加噪,最终的分布趋向于 $\mathcal{N}(0,max_i{\sigma_i^2})$ 运用分数匹配的方式来训练基于U-Net结构的MCSN网络, 使得MCSN能够估计任意加噪后分布的分数 基于任意加噪分布的分数和退火的郎之万动力学应用到采样来生成准确的原始数据分布的新样本 正式开始介绍之前首先解答一下这个问题: score-based 模型是什么东西,微分方程在这个模型里到底有什么用? 我们知道生成模型基本都是从某个现有的分布中进行采样得到生成的样本,为此模型需要完成对分布的建模。根据建模方式的不同可以分为隐式建模(例如 GAN、diffusion models)和显式建模(例如 VAE、normalizing flows)。和上述的模型相同,score-based 模型也是用一定方式对分布进行了建模。具体而言,这类模型建模的对象是概率分布函数 log 的梯度,也就是 score...
Generative Model
2026-03-04

Diffusion Models from SDE 连续扩散模型 (Continuous Diffusion Models) 将传统的离散时间扩散过程扩展到连续时间域,可以被视为一个随机过程,使用随机微分方程(SDE)来描述。其前向过程可以写成如下形式: \[\mathrm d\mathbf x=\mathbf f(\mathbf x,t)\mathrm dt+g(t)\mathrm d\mathbf w\tag{1}\] 其中, \(f(x,t)\) 可以看成偏移系数, \(g(t)\) 可以看成是扩散系数, \(dw\) 是标准布朗运动。这个SDE 描述了数据在连续时间域内如何被噪声逐渐破坏。 这个随机过程的 逆向过程 存在(更准确的描述:下面的逆向时间SDE具有 与正向过程SDE相同的联合分布 )为 \[d\mathbf{x}=[\mathbf{f}(\mathbf{x},t)-g^2(t)\nabla_{\mathbf{x}}\log p_t(\mathbf{x})]dt+g(t)d\bar{\mathbf{w}}\tag{2}\]...
Generative Model
2026-03-03

基于文章 《Elucidating the Design Space of Diffusion-Based Generative Models》 来统一扩散模型框架 通用扩散模型框架推导 加噪公式 Flow Matching的一步加噪公式 \[\mathbf{x}_t=(1-t)\mathbf{x}_0+t\varepsilon\] 写成概率分布形式: \[p(\mathbf{x}_t|\mathbf{x}_0)=\mathcal{N}(\mathbf{x}_t;(1-t)\mathbf{x}_0,t^2\mathbf{I})\] Score Matching的一步加噪公式 \[\mathbf{x}_t=\mathbf{x}_0+\sigma_t\varepsilon \] 写成概率分布形式: \[p(\mathbf{x}_t|\mathbf{x}_0)=\mathcal{N}(\mathbf{x}_t;\mathbf{x}_0,\sigma_t^2\mathbf{I})\] DDPM/DDIM的一步加噪公式...
Generative Model
2026-03-03

- SMLD 和 DDPM 中使用的噪声扰动可以看作是两个不同 SDE 的离散化 - 扩散模型和评分模型在连续时间极限下完全等价,也就是说将有限次数的加噪过程推广到无穷次, 也就是推广到连续的情况下,可以得到一个更加一般的扩散过程,这个过程可以用SDE来表示,求解更加方便 - 两种方法的目标函数可以互相转换 随机微分 在DDPM中,扩散过程被划分为了固定的T步,还是用DDPM中的类比来说,就是“拆楼”和“建楼”都被事先划分为了T步,这个划分有着相当大的人为性。事实上,真实的“拆”、“建”过程应该是没有刻意划分的步骤的,我们可以将它们理解为一个在时间上连续的变换过程,可以用随机微分方程(Stochastic Differential Equation,SDE)来描述。 为此,我们用下述SDE描述前向过程(“拆楼”): \[d\boldsymbol{x} = \boldsymbol{f}_t(\boldsymbol{x}) dt + g_t d\boldsymbol{w}\tag{1}\]...
杂七杂八
2026-01-11
大数据本身是个很宽泛的概念,Hadoop生态圈(或者泛生态圈)基本上都是为了处理超过单机尺度的数据处理而诞生的。你可以把它比作一个厨房所以需要的各种工具。锅碗瓢盆,各有各的用处,互相之间又有重合。你可以用汤锅直接当碗吃饭喝汤,你可以用小刀或者刨子去皮。但是每个工具有自己的特性,虽然奇怪的组合也能工作,但是未必是最佳选择。 大数据,首先你要能存的下大数据 传统的文件系统是单机的,不能横跨不同的机器。HDFS(Hadoop Distributed FileSystem)的设计本质上是为了大量的数据能横跨成百上千台机器,但是你看到的是一个文件系统而不是很多文件系统。比如你说我要获取/hdfs/tmp/file1的数据,你引用的是一个文件路径,但是实际的数据存放在很多不同的机器上。你作为用户,不需要...
杂七杂八
2026-01-11
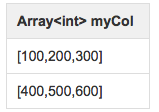
1. explode hive wiki对于expolde的解释如下: explode() takes in an array (or a map) as an input and outputs the elements of the array (map) as separate rows. UDTFs can be used in the SELECT expression list and as a part of LATERAL VIEW. As an example of using explode() in the SELECT expression list, consider a table named myTable that has a single column (m...

Apache Hadoop 是一款支持数据密集型分布式应用程序并以Apache 2.0许可协议发布的开源软件框架。它支持在商用硬件构建的大型集群上运行的应用程序。Hadoop是根据谷歌公司发表的MapReduce 和Google文件系统的论文自行实现而成。所有的Hadoop模块都有一个基本假设,即硬件故障是常见情况,应该由框架自动处理。具体参考官方教程。 Hadoop架构 HDFS: 分布式文件存储 YARN: 分布式资源管理 MapReduce: 分布式计算 Others: 利用YARN的资源管理功能实现其他的数据处理方式 内部各个节点基本都是采用MasterWoker架构 Hadoop HDFS 架构 Block数据块; NameNode Secondary NameNode DataN...