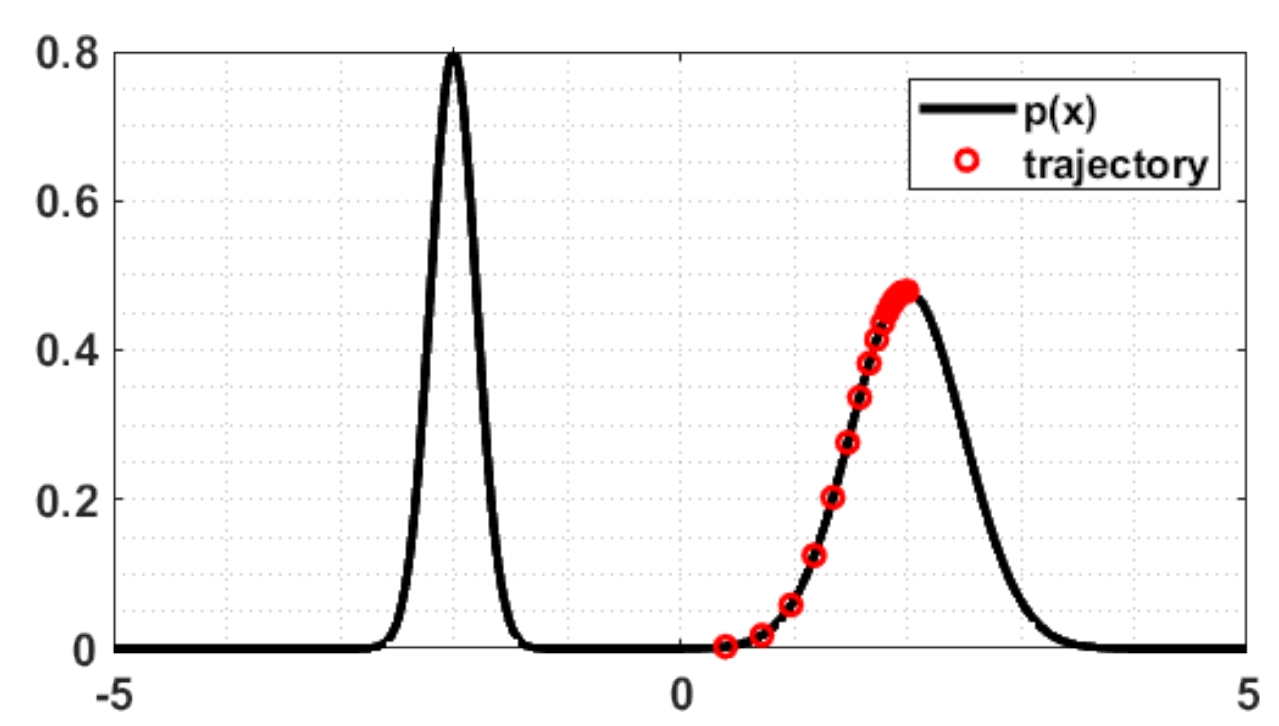
朗之万动力学(Langevin Dynamics)是扩散模型和score matching方法中的采样过程,是文本生成图像中的一个重要步骤。想要洞悉文生图的基本原理,朗之万动力学是绕不开的话题。 朗之万动力学原理简介 本文的主要内容是基于以下教程: Tutorial on Diffusion Models for Imaging and Vision 此教程写的非常好,非常推荐大家学习。教程的语言风格也很亲切,时不时地蹦出诸如“这是地球人能想出来的公式?”这样的话,为你枯燥的学习过程增添些许趣味。 朗之万动力学(Langevin Dynamics)是扩散模型和score matching方法中的采样过程,是文本生成图像中的一个重要步骤。想要洞悉文生图的基本原理,朗之万动力学是绕不开的话题。 给定一个已知的概率分布 \(p(x)\) ,我们的目标是采样出概率密度更大的那些样本。解决这个问题有多种方法,比如生成伪随机均匀分布,然后用概率分布变换的方法;或者用马尔可夫链蒙特卡洛方法(MCMC)。而朗之万动力学给出的方法是这样: 随机选取空间中一个点(这是很简单的,采用高斯生成与 \(x\)...
Deep Learning
2026-03-02

通过卷积和池化等技术可以将图像进行降维,因此,一些研究人员也想办法恢复原分辨率大小的图像,特别是在语义分割领域应用很成熟。 Upsampling(上采样)[没有学习过程] 在FCN、U-net等网络结构中,涉及到了上采样。上采样概念: 上采样指的是任何可以让图像变成更高分辨率的技术 。最简单的方式是 重采样和插值 :将输入图片进行rescale到一个想要的尺寸,而且计算每个点的像素点,使用如双线性插值等插值方法对其余点进行插值来完成上采样过程。 在PyTorch中,上采样的层被封装在 torch.nn 中的 Vision Layers 里面,一共有4种: PixelShuffle Upsample UpsamplingNearest2d UpsamplingBilinear2d PixelShuffle 当stride = (1/r) < 1时,可以让卷积后的feature map变大——即分辨率变大,这个新的操作叫做sub-pixel convolution,具体原理可以看 “PixelShuffle:Real-Time Single Image and Video...
Deep Learning
2026-02-28
现代深度学习库对大多数操作都具有生产级的、高度优化的实现,这并不奇怪。但这些库究竟是什么魔法?他们如何能够将性能提高100倍?究竟怎样才能“优化”或加速神经网络的运行呢?在讨论高性能/高效DNNs时,我经常会问(也经常被问到)这些问题。 在这篇文章中,我将尝试带你了解在DNN库中卷积层是如何实现的。它不仅是在模型中最常见的和最重的操作,我还发现卷积高性能实现的技巧特别具有代表性——一点点算法的小聪明,非常多的仔细的调优和低层架构的开发。 我在这里介绍的很多内容都来自Goto等人的开创性论文:Anatomy of a high-performance matrix multiplication,该论文为OpenBLAS等线性代数库中使用的算法奠定了基础。 最原始的卷积实现 “过早的优化是万恶之源”——Donald Knuth 在进行优化之前,我们先了解一下基线和瓶颈。这是一个朴素的numpy/for循环卷积: '''
Convolve `input` with `kernel` to generate `output`
input.shape =...
Computer Vision
2026-02-26

上图是Yolo v4中,对各种detector部件的总结:包含Input、backbone、neck、head、... Backbone 轻量级网络系列 Neck 例如:SPP 、 ASPP 、 RFB、 SAM 用来增加感受野 特征融合,主要是指不同输出层直接的特征融合,主要包括FPN、PAN、SFAM、ASFF和BiFPN。 结构 Path Aggregation Blcok Deformable Convolution系列 One stage Yolo系列 Focal Loss & RetinaNet Two-Stage Faster R-CNN R-FCN Anchor Free Anchor-Free Transformer DETR Problems 目标检测中的多尺度问题 NMS及其改进 IoU loss系列 目标检测中mAP计算
Computer Vision
2026-02-26
mAP定义及相关概念 mAP: mean Average Precision, 即各类别AP的平均值 AP: PR曲线下面积,后文会详细讲解 PR曲线: Precision-Recall曲线 Precision: TP / (TP + FP) Recall: TP / (TP + FN) TP: IoU>0.5的检测框数量(同一Ground Truth只计算一次) FP: IoU<=0.5的检测框,或者是检测到同一个GT的多余检测框的数量 FN: 没有检测到的GT的数量 mAP的具体计算 由前面定义,我们可以知道,要计算mAP必须先绘出各类别PR曲线,计算出AP。而如何采样PR曲线,VOC采用过两种不同方法。 在VOC2010以前,只需要选取当Recall >= 0, 0.1, 0.2, ..., 1共11个点时的Precision最大值,然后AP就是这11个Precision的平均值。 在VOC2010及以后,需要针对每一个不同的Recall值(包括0和1),选取其大于等于这些Recall值时的Precision最大值,然后计算PR曲线下面积作为AP值。 mAP计算示例 假设,对于...
Computer Vision
2026-02-26
简介 "Anchor-free"(无锚点)是一种目标检测方法,与传统的使用锚框(anchor boxes)的方法(例如Faster R-CNN)不同。在传统方法中,锚框是预先定义的、具有不同尺寸和长宽比的矩形区域,用于捕捉不同尺寸和形状的目标。而在"anchor-free"方法中,不再使用锚框,而是直接预测目标的位置和形状,通常使用网络输出的热图和偏移信息。 以下是对"anchor-free"方法的一些关键理解点: 无需预定义锚框: 在传统目标检测方法中,需要事先定义和生成一组锚框,这可能需要大量的人工工作。而在"anchor-free"方法中,不再需要锚框,模型可以自动学习目标的位置和形状。 直接位置和形状回归: "anchor-free"方法通过输出的热图来表示目标的存在概率,并使用偏移信息来定位目标的中心和形状。这些热图和偏移信息通常通过卷积神经网络预测。 适用于不规则目标: 传统的锚框在捕捉不规则形状的目标时可能会有困难,而"anchor-free"方法可以更好地适应不规则目标的检测。 减少计算复杂性:...
Computer Vision
2026-02-26
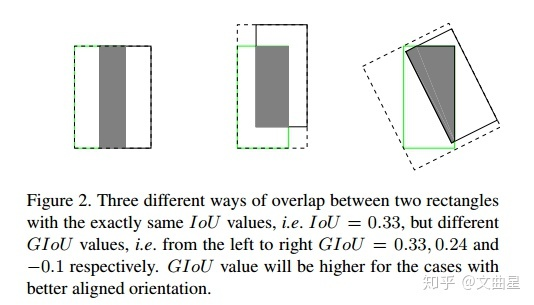
IOU(Intersection over Union) 特性(优点) IoU就是我们所说的 交并比 ,是目标检测中最常用的指标,在anchor-based的方法中,他的作用不仅用来确定正样本和负样本,还可以用来评价输出框(predict box)和ground-truth的距离。 \[IoU = \frac{|A \cap B|}{|A \cup B|}
\] 可以说 它可以反映预测检测框与真实检测框的检测效果。 还有一个很好的特性就是 尺度不变性 ,也就是对尺度不敏感(scale invariant), 在regression任务中,判断predict box和gt的距离最直接的指标就是IoU。 (满足非负性;同一性;对称性;三角不等性) import numpy as np
def Iou(box1, box2, wh=False):
if wh == False:
xmin1, ymin1, xmax1, ymax1 = box1
xmin2, ymin2, xmax2, ymax2 = box2
else:
xmin1, ymin1 =...
Computer Vision
2026-02-26

过程: 根据分类概率从小到大排序ABCDEF 从最大概率F开始,F与A~E的IOU是否大于阈值 大于的扔掉,从剩下的当中继续重复2~3 import numpy as np
def nms(bbox, scores, Nt):
if len(bbox) == 0:
return []
bboxes = np.array(bbox)
x1 = bboxes[:, 0]
y1 = bboxes[:, 1]
x2 = bboxes[:, 2]
y2 = bboxes[:, 3]
area = (x2 - x1 + 1) * (y2 - y1 + 1)
order = np.argsort(scores)
res = []
while order.size > 0:
index = order[-1]
res.append(bboxes[index])
x11 = np.maximum(x1[index], x1[order[:-1]])
...
Computer Vision
2026-02-26
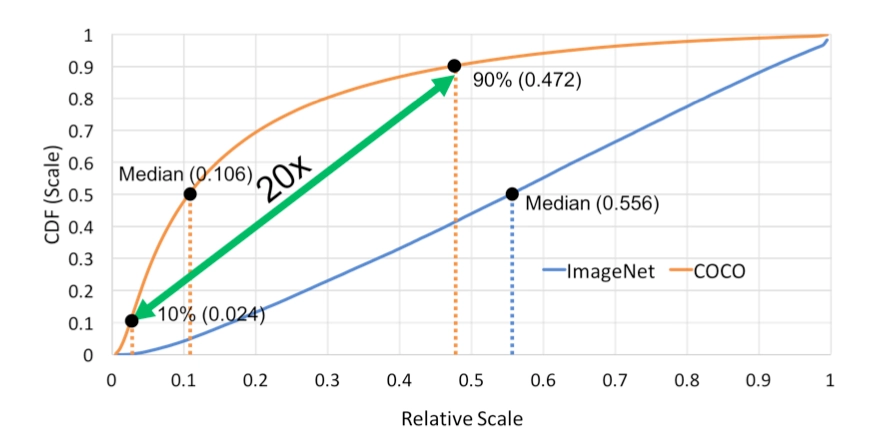
传统的图像金字塔 最开始在深度学习方法流行之前,对于不同尺度的目标,大家普遍使用将原图构建出不同分辨率的图像金字塔,再对每层金字塔用固定输入分辨率的分类器在该层滑动来检测目标,以求在金字塔底部检测出小目标;或者只用一个原图,在原图上, 用不同分辨率的分类器来检测目标,以求在比较小的窗口分类器中检测到小目标。 经典的 基于简单矩形特征(Haar)+级联Adaboost与Hog特征+SVM的DPM目标识别框架,均使用图像金字塔的方式处理多尺度目标 ,早期的CNN目标识别框架同样采用该方式,但对图像金字塔中的每一层分别进行CNN提取特征,耗时与内存消耗均无法满足需求。但 该方式毫无疑问仍然是最优的。 值得一提的是,其实目前大多数深度学习算法提交结果进行排名的时候,大多使用 多尺度测试 。同时类似于SNIP使用多尺度训练,均是图像金字塔的多尺度处理。 SNIP 图像分类算法,比如ResNeXt-101 32 × 48d网络结构,在Imagenet数据集上的Top5准确率已经98%左右,Top1为85%。对于图像检测算法,最好的模型在coco数据集上的效果 \(AP_{50}\)...
Computer Vision
2026-02-26

原理分析 网络架构: 本文的任务是Object detection,用到的工具是Transformers,特点是End-to-end。 目标检测的任务是要去预测一系列的Bounding Box的坐标以及Label, 现代大多数检测器通过定义一些proposal,anchor或者windows,把问题构建成为一个分类和回归问题来间接地完成这个任务。 文章所做的工作,就是将transformers运用到了object detection领域,取代了现在的模型需要手工设计的工作,并且取得了不错的结果。 在object detection上DETR准确率和运行时间上和Faster RCNN相当;将模型 generalize 到 panoptic segmentation 任务上,DETR表现甚至还超过了其他的baseline。DETR第一个使用End to End的方式解决检测问题,解决的方法是把检测问题视作是一个set prediction problem,如下图所示。...
Computer Vision
2026-02-26

总体流程 RPN RPN在Extractor输出的feature maps的基础之上,先增加了一个3x3卷积,然后利用两个1x1的卷积分别进行二分类(是否为正样本)和位置回归。进行分类的卷积核通道数为9×2(9个anchor,每个anchor二分类,使用交叉熵损失),进行回归的卷积核通道数为9×4(9个anchor,每个anchor有4个位置参数)。 接下来RPN做的事情就是利用(AnchorTargetCreator)将20000多个候选的anchor选出2000个proposal并采样256个positive 进行分类和回归位置loss计算。具体过程如下: proposal 前向过程中会做 NMS : 对 所有 anchors 做前背景分类和bbox regression回归(learning offset) 对 foreground (iou>0.7) softmax scores由大到小排序anchors,提取 6000/12000(test/train) anchors( 已经在上一步进行好了 coord reg) 限定超出图像边界的 foreground anchors...
Computer Vision
2026-02-26
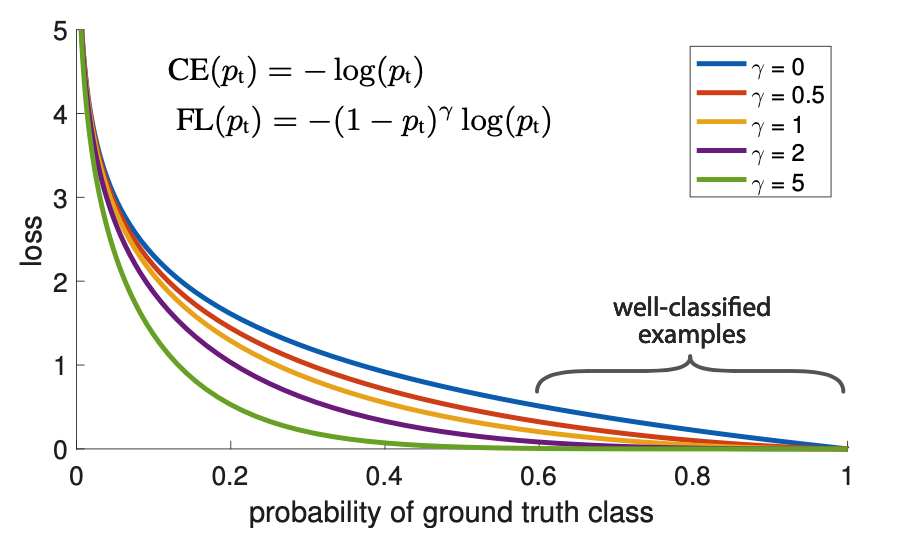
Motivation 我们知道object detection的算法主要可以分为两大类: two-stage detector和one-stage detector 。前者是指类似Faster RCNN,RFCN这样需要region proposal的检测算法,这类算法可以达到很高的准确率,但是速度较慢。虽然可以通过减少proposal的数量或降低输入图像的分辨率等方式达到提速,但是速度并没有质的提升。后者是指类似YOLO,SSD这样不需要region proposal,直接回归的检测算法,这类算法速度很快,但是准确率不如前者。 作者提出focal loss的出发点也是希望one-stage detector可以达到two-stage detector的准确率,同时不影响原有的速度。 既然有了出发点, 那么就要找one-stage detector的准确率不如two-stage detector的原因,作者认为原因是:样本的类别不均衡导致的 。我们知道在object detection领域,一张图像可能生成成千上万的candidate...