
Apache Hadoop 是一款支持数据密集型分布式应用程序并以Apache 2.0许可协议发布的开源软件框架。它支持在商用硬件构建的大型集群上运行的应用程序。Hadoop是根据谷歌公司发表的MapReduce 和Google文件系统的论文自行实现而成。所有的Hadoop模块都有一个基本假设,即硬件故障是常见情况,应该由框架自动处理。具体参考 官方教程 。 Hadoop架构 HDFS: 分布式文件存储 YARN: 分布式资源管理 MapReduce: 分布式计算 Others: 利用YARN的资源管理功能实现其他的数据处理方式 内部各个节点基本都是采用Master-Woker架构 Hadoop HDFS 架构 Block数据块; 基本存储单位,一般大小为64M(配置大的块主要是因为:1)减少搜寻时间,一般硬盘传输速率比寻道时间要快,大的块可以减少寻道时间;2)减少管理块的数据开销,每个块都需要在NameNode上有对应的记录;3)对数据块进行读写,减少建立网络的连接成本)...
Large Model
2026-03-09

Stanford Alpaca 结合英文语料通过Self Instruct方式微调LLaMA 7B Stanford Alpaca简介 2023年3月中旬,斯坦福的Rohan Taori等人发布Alpaca(中文名:羊驼):号称只花100美元,人人都可微调Meta家70亿参数的LLaMA大模型(即LLaMA 7B), 具体做法是通过52k指令数据,然后在8个80GB A100上训练3个小时,使得Alpaca版的LLaMA 7B在单纯对话上的性能比肩GPT-3.5(text-davinci-003) ,这便是指令调优LLaMA的意义所在 论文《Alpaca: A Strong Open-Source Instruction-Following Model》 GitHub地址: https://github.com/tatsu-lab/stanford_alpaca 数据地址 (即斯坦福团队微调LLaMA 7B所用的52K英文指令数据): raw.githubusercontent.com/tatsu-lab/stanford_alpaca/main/alpaca_data.json...
Large Model
2026-03-06
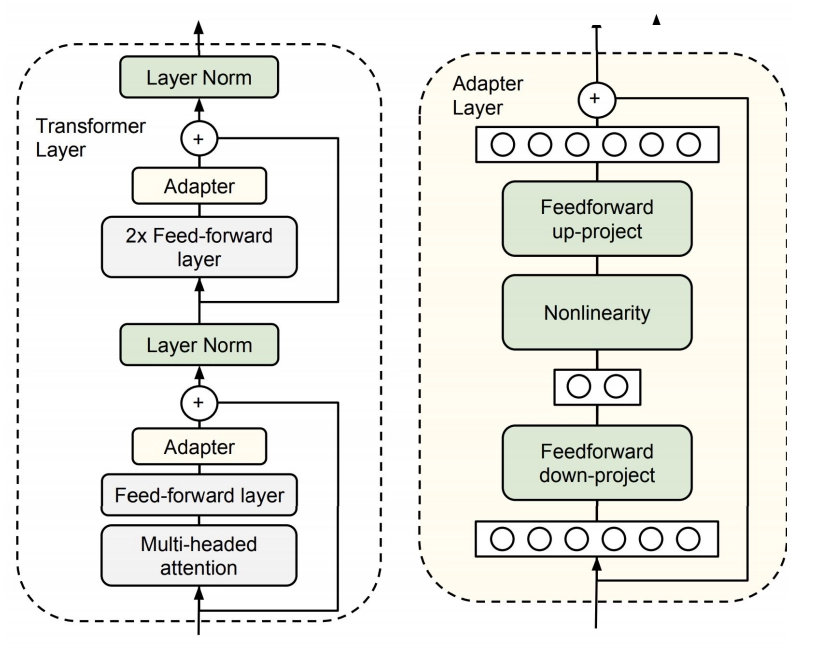
Adapter tuning Adapter Tuning试图在Transformer Layer的Self-Attetion+FFN之后插入一个先降维再升维的MLP(以及一层残差和LayerNormalization)来学习模型微调的知识。 在预训练模型每一层(或某些层)中添加Adapter模块(如上图左侧结构所示),微调时冻结预训练模型主体,由Adapter模块学习特定下游任务的知识。每个Adapter模块由两个前馈子层组成,第一个前馈子层将Transformer块的输出作为输入,将原始输入维度 \(d\) 投影到 \(m\) ,通过控制 \(m\) 的大小来限制Adapter模块的参数量,通常情况下 \(m\ll d\) 。在输出阶段,通过第二个前馈子层还原输入维度,将 \(m\) 重新投影到 \(d\)...
Deep Learning
2026-03-02
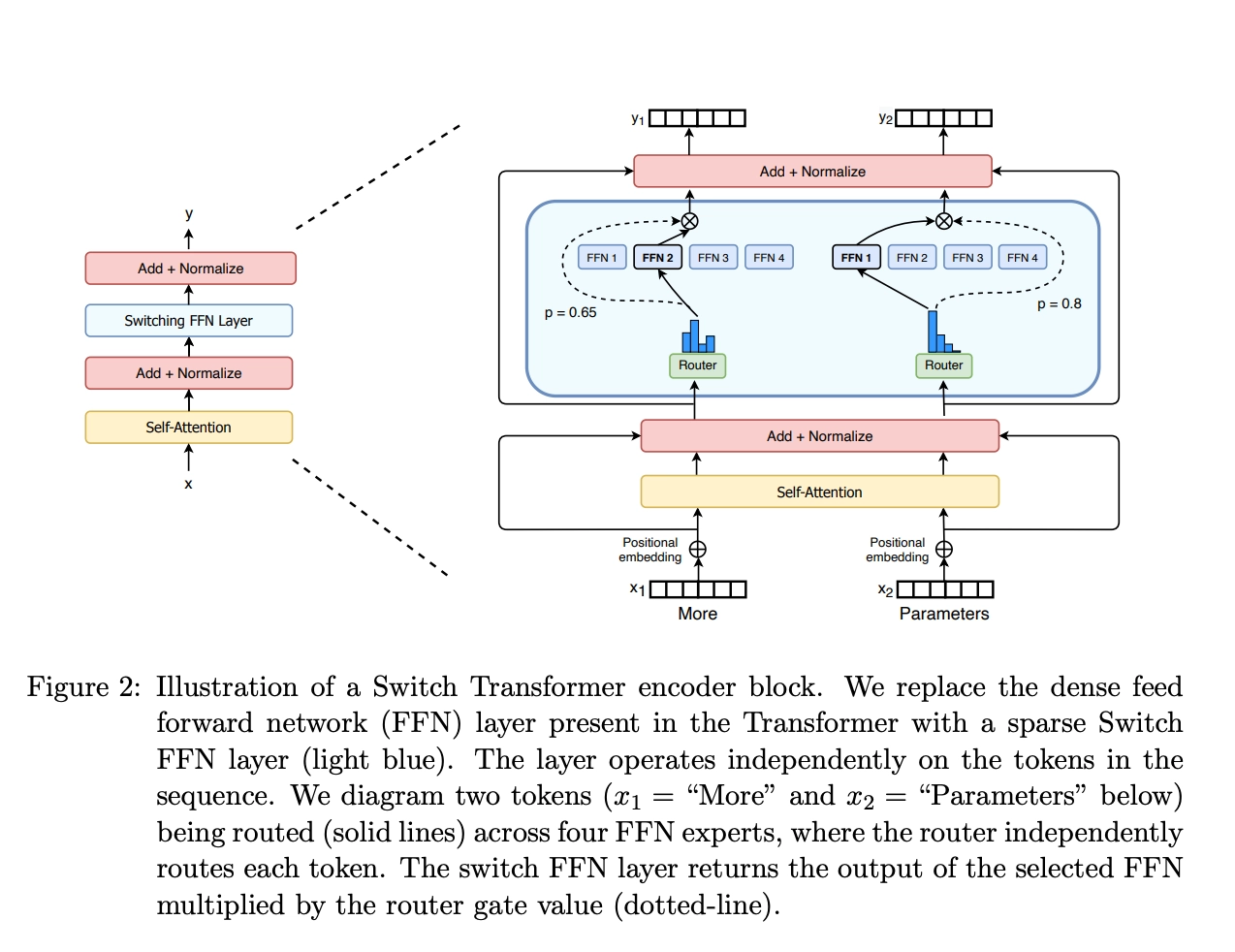
简短总结 混合专家模型 (MoEs): 与稠密模型相比, 预训练速度更快 与具有相同参数数量的模型相比,具有更快的 推理速度 需要 大量显存 ,因为所有专家系统都需要加载到内存中 在 微调方面存在诸多挑战 ,但 近期的研究 表明,对混合专家模型进行 指令调优具有很大的潜力 。 什么是混合专家模型? 模型规模是提升模型性能的关键因素之一。在有限的计算资源预算下,用更少的训练步数训练一个更大的模型,往往比用更多的步数训练一个较小的模型效果更佳。 混合专家模型 (MoE) 的一个显著优势是它们能够在远少于稠密模型所需的计算资源下进行有效的预训练。这意味着在相同的计算预算条件下,您可以显著扩大模型或数据集的规模。特别是在预训练阶段,与稠密模型相比,混合专家模型通常能够更快地达到相同的质量水平。 那么,究竟什么是一个混合专家模型 (MoE) 呢?作为一种基于 Transformer 架构的模型,混合专家模型主要由两个关键部分组成: 稀疏 MoE 层 : 这些层代替了传统 Transformer 模型中的前馈网络 (FFN) 层。MoE 层包含若干“专家”(例如 8...
Deep Learning
2026-03-02

通过卷积和池化等技术可以将图像进行降维,因此,一些研究人员也想办法恢复原分辨率大小的图像,特别是在语义分割领域应用很成熟。 Upsampling(上采样)[没有学习过程] 在FCN、U-net等网络结构中,涉及到了上采样。上采样概念: 上采样指的是任何可以让图像变成更高分辨率的技术 。最简单的方式是 重采样和插值 :将输入图片进行rescale到一个想要的尺寸,而且计算每个点的像素点,使用如双线性插值等插值方法对其余点进行插值来完成上采样过程。 在PyTorch中,上采样的层被封装在 torch.nn 中的 Vision Layers 里面,一共有4种: PixelShuffle Upsample UpsamplingNearest2d UpsamplingBilinear2d PixelShuffle 当stride = (1/r) < 1时,可以让卷积后的feature map变大——即分辨率变大,这个新的操作叫做sub-pixel convolution,具体原理可以看 “PixelShuffle:Real-Time Single Image and Video...
Deep Learning
2026-02-28
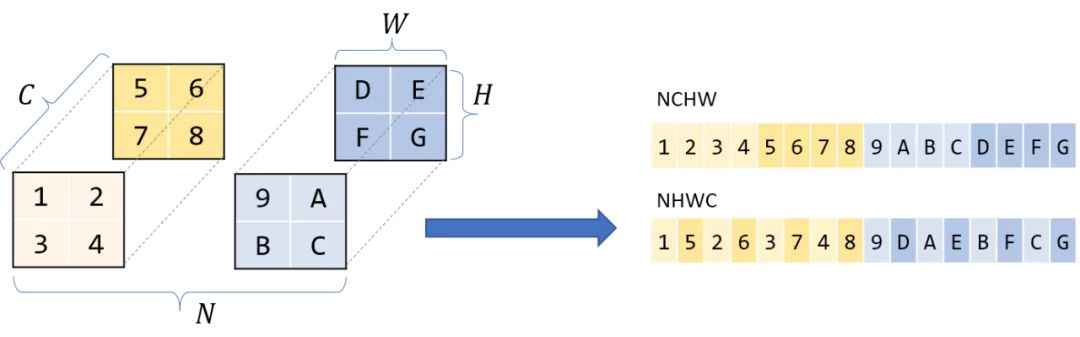
现代深度学习库对大多数操作都具有生产级的、高度优化的实现,这并不奇怪。但这些库究竟是什么魔法?他们如何能够将性能提高100倍?究竟怎样才能“优化”或加速神经网络的运行呢?在讨论高性能/高效DNNs时,我经常会问(也经常被问到)这些问题。 在这篇文章中,我将尝试带你了解在DNN库中卷积层是如何实现的。它不仅是在模型中最常见的和最重的操作,我还发现卷积高性能实现的技巧特别具有代表性——一点点算法的小聪明,非常多的仔细的调优和低层架构的开发。 我在这里介绍的很多内容都来自Goto等人的开创性论文:Anatomy of a high-performance matrix multiplication,该论文为OpenBLAS等线性代数库中使用的算法奠定了基础。 最原始的卷积实现 “过早的优化是万恶之源”——Donald Knuth 在进行优化之前,我们先了解一下基线和瓶颈。这是一个朴素的numpy/for循环卷积: '''
Convolve `input` with `kernel` to generate `output`
input.shape =...