
💡 GRPO相比PPO主要优势: 1. 训练更稳定 引入 KL 散度惩罚项,有效控制策略更新的幅度,避免策略崩溃,提高训练的稳定性 GRPO用组内相对优势替代value model,消除了value估计误差 通过组内归一化,自动消除reward scale和bias的影响 实验中发现GRPO的advantage方差比PPO小30%左右,训练崩溃率更低 2. 工程更简单 只需要1-2个模型(policy + reference),而PPO需要4个 显存占用减少50%以上,训练速度提升2-3倍 超参数更少,更容易调优 3. 相对奖励机制 通过对同一输入生成的多个输出进行比较,GRPO 能够更稳定地估计优势函数,减少了训练过程中的方差 背景 GRPO是 DeepSeek-Math model中提出的对PPO方法的改进策略: 强化学习(RL)在提升模型数学推理能力方面被证明是有效的 传统PPO算法需要较大训练资源 GRPO作为PPO的变体被提出,可以更高效地优化模型 PPO Vs GRPO PPO回顾 PPO的目标函数为: \[\begin{aligned}J_{PPO}(\theta) =...
Machine Learning
2026-03-18

集成学习主要分为以下几类:Bagging,Boosting以及Stacking。 传统机器学习算法 (例如:决策树,人工神经网络,支持向量机,朴素贝叶斯等) 的目标都是寻找一个最优分类器尽可能的将训练数据分开。集成学习 (Ensemble Learning) 算法的基本思想就是将多个分类器组合,从而实现一个预测效果更好的集成分类器。集成算法可以说从一方面验证了中国的一句老话:三个臭皮匠,赛过诸葛亮。 Thomas G. Dietterich 指出了集成算法在统计,计算和表示上的有效原因: 统计上的原因 一个学习算法可以理解为在一个假设空间 H 中选找到一个最好的假设。但是,当训练样本的数据量小到不够用来精确的学习到目标假设时,学习算法可以找到很多满足训练样本的分类器。所以,学习算法选择任何一个分类器都会面临一定错误分类的风险,因此将多个假设集成起来可以降低选择错误分类器的风险。 计算上的原因 很多学习算法在进行最优化搜索时很有可能陷入局部最优的错误中,因此对于学习算法而言很难得到一个全局最优的假设。事实上人工神经网络和决策树已经被证实为是一 个NP...
Machine Learning
2026-03-18

从GBDT到XGBoost 作为GBDT的高效实现,XGBoost是一个上限特别高的算法,因此在算法竞赛中比较受欢迎。简单来说,对比原算法GBDT,XGBoost主要从下面三个方面做了优化: 一是算法本身的优化:在算法的弱学习器模型选择上,对比GBDT只支持决策树,还可以选择很多其他的弱学习器。在算法的损失函数上,除了本身的损失,还加上了正则化部分。在算法的优化方式上,GBDT的损失函数只对误差部分做负梯度(一阶泰勒)展开,而XGBoost损失函数对误差部分做二阶泰勒展开,更加准确。算法本身的优化是我们后面讨论的重点。 二是算法运行效率的优化:对每个弱学习器,比如决策树建立的过程做并行选择,找到合适的子树分裂特征和特征值。在并行选择之前,先对所有的特征的值进行排序分组,方便前面说的并行选择。对分组的特征,选择合适的分组大小,使用CPU缓存进行读取加速。将各个分组保存到多个硬盘以提高IO速度。 三是算法健壮性的优化:对于缺失值的特征,通过枚举所有缺失值在当前节点是进入左子树还是右子树来决定缺失值的处理方式。算法本身加入了L1和L2正则化项,可以防止过拟合,泛化能力更强。...
Machine Learning
2026-03-18
GBDT (Gradient Boosting Decision Tree) 是另一种基于 Boosting 思想的集成算法,除此之外 GBDT 还有很多其他的叫法,例如:GBM (Gradient Boosting Machine),GBRT (Gradient Boosting Regression Tree),MART (Multiple Additive Regression Tree) 等等。GBDT 算法由 3 个主要概念构成:Gradient Boosting (GB),Regression Decision Tree (DT 或 RT) 和 Shrinkage。 Decision Tree:CART回归树 首先,GBDT使用的决策树是CART回归树,无论是处理回归问题还是二分类以及多分类,GBDT使用的决策树通通都是都是CART回归树。为什么不用CART分类树呢?因为GBDT每次迭代要拟合的是 梯度值...
Machine Learning
2026-03-18
分类问题 Adaboost 是 Boosting 算法中有代表性的一个。原始的 Adaboost 算法用于解决二分类问题,因此对于一个训练集 \[T = \{\left(x_1, y_1\right), \left(x_2, y_2\right), ..., \left(x_n, y_n\right)\}\] 其中 \(x_i \in \mathcal{X} \subseteq \mathbb{R}^n, y_i \in \mathcal{Y} = \{-1, +1\}\) ,,首先初始化训练集的权重 \[\begin{aligned}
D_1 =& \left(w_{11}, w_{12}, ..., w_{1n}\right) \\
w_{1i} =& \dfrac{1}{n}, i = 1, 2, ..., n
\end{aligned}\] 根据每一轮训练集的权重 \(D_m\) ,对训练集数据进行抽样得到 \(T_m\) ,再根据 \(T_m\) 训练得到每一轮的基学习器 \(h_m\) 。通过计算可以得出基学习器 \(h_m\) 的误差为 \(e_m\) \[e_m =...
Large Model
2026-03-18
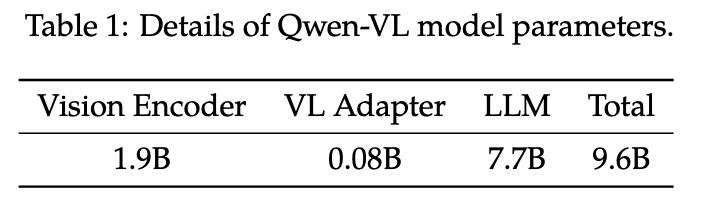
Qwen-VL 模型框架 Qwen-VL的整体网络架构由三个组件组成: LLM:使用 Qwen-7B 的预训练权重进行初始化。 视觉编码器:Qwen-VL 的可视化编码器使用ViT 架构,使用 Openclip 的 ViT-bigG 的预训练权重进行初始化。在训练和推理过程中,输入图像的大小都会调整为特定分辨率。视觉编码器通过以 14 步幅将图像分割成块来处理图像,生成一组图像特征。 位置感知视觉语言适配器:为了缓解长图像特征序列带来的效率问题,Qwen-VL 引入了一种视觉语言适配器来压缩图像特征。类似QFormer,该适配器包括一个随机初始化的单层交叉注意力模块。使用一组可训练向量(嵌入)作为query,并将视觉编码器中的图像特征作为交叉注意力作的key。该机制将视觉特征序列压缩到固定长度 256。 图像输入 图像不会直接以像素形式喂给语言模型(LLM)。 典型流程是: Visual Encoder :把图片编码成一串视觉特征(embedding/feature sequence)。 Adapter :把视觉特征映射到语言模型可接入的表征空间/维度。 最终得到:...
Large Model
2026-03-18
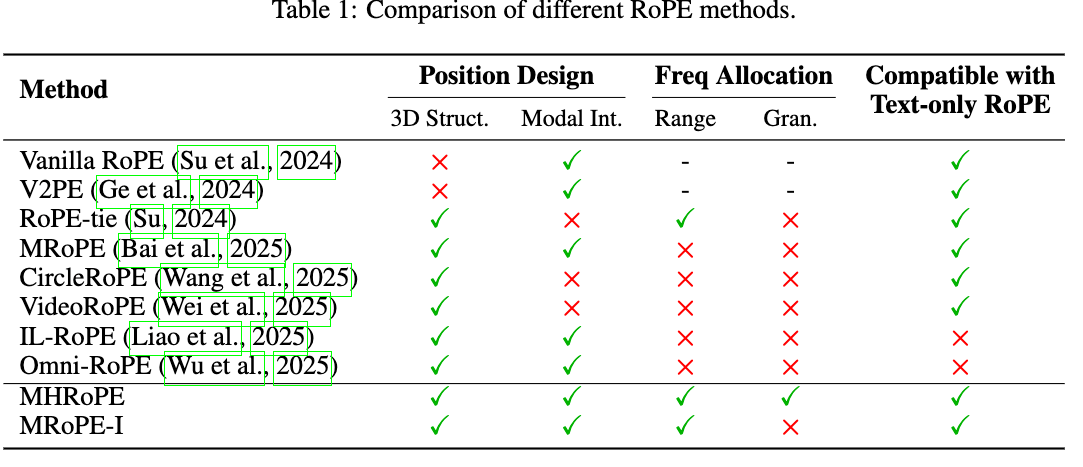
简介 论文: 《REVISITING MULTIMODAL POSITIONAL ENCODING IN VISION–LANGUAGE MODELS》 通过对多模态旋转位置嵌入(RoPE)的两个核心组件——位置设计和频率分配进行综合分析。通过实验,确定了三个关键指南:位置一致性、频率全利用和保留文本先验。基于这些见解,提出了多头RoPE(MHRoPE)和MRoPE-Interleave(MRoPE-I),这两种简单且即插即用的变体不需要任何架构更改。 为了构建更稳健的多模态位置编码,作者在MRoPE的基础上,系统地探索了三个未充分研究的方案: 位置设计——如何为文本和视觉标记分配无歧义、分离良好的坐标; 频率分配——如何将旋转频率分配到每个位置轴的嵌入维度; 与纯文本RoPE的兼容性——确保设计默认为标准RoPE,以便进行有效的迁移学习。 Vanilla RoPE RoPE与加性位置嵌入不同,RoPE对query和key向量应用旋转变换,从而将相对位置依赖直接纳入自注意力机制。给定位置 \(m\) 的查询向量 \(q\) 和位置 \(n\) 的键向量 \(k\) ,注意力分数...
Large Model
2026-03-12

比起两年前,NLG任务已经得到了非常有效的发展,transformers模块的使用广泛程度也达到前所未有的程度。在模型推理预测时,一个核心的语句就是 model.generate() ,本文就来详细介绍一下generate方法是如何运作的。在生成的过程中,包含了诸多生成策略,本文将以最常用的beam search为例,尽可能详细地展开介绍。 随着各种LLM的出现,transformers中与generate相关的代码发生了一些变化,主要区别在于: generate的源码位置发生了改变; generate方法中,采用一个 generation_config 参数来管理生成相关的各种配置,并优化了逻辑,使得逻辑更加清晰。 generate的代码位置 在之前版本的transformers中(transformers~=4.9),generate方法位于 transformers.generation_utils.py ,这个方法是 GenerationMixin 类的一个方法。 而在新版本的transformers中(transformers~=4.42),generate方法被转移到了...
Large Model
2026-03-12

概述 https://github.com/FasterDecoding/Medusa Medusa 是自投机领域较早的一篇工作,对后续工作启发很大,其主要思想是 multi-decoding head + tree attention + typical acceptance(threshold)。Medusa 没有使用独立的草稿模型,而是在原始模型的基础上增加多个解码头(MEDUSA heads),并行预测多个后续 token。 正常的LLM只有一个用于预测 \(t\) 时刻token的head。Medusa 在 LLM 的最后一个 Transformer层之后保留原始的 LM Head,然后额外增加多个(假设是 \(k\) 个) 可训练的Medusa Head(解码头),分别负责预测 \(t+1,t+2,...,\) 和 \(t+k\) 时刻的不同位置的多个 Token。 Medusa 让每个头生成多个候选 token,而非像投机解码那样只生成一个候选。然后将所有的候选结果组装成多个候选序列,多个候选序列又构成一棵树。再通过树注意力机制并行验证这些候选序列 。 原理...
Large Model
2026-03-10

概述 投机解码(Speculative Decoding)也叫预测解码/投机采样,它会利用小模型来预测大型模型的行为,从而提升模型在解码(decoding)阶段的解码效率问题,加速大型模型的执行。其核心思路如下图所示,首先以低成本的方式(以小模型为主,也有多头,检索,Early Exit 等方式)快速生成多个候选 Token(串行序列、树、多头树等),然后通过一次并行验证阶段快速验证多个 Token的正确性,只要平均每个 Step 验证的 Token 数 > 1,就可以一次性生成多个token,进而减少总的 Decoding 步数,实现加速的目的。 下图左侧是自回归解码模型,右侧是投机解码机制。 从本质上来说,投机解码希望在推理阶段在不大幅度改变模型的情况下,通过更好利用冗余算力来并行"投机"地猜测出模型接下来要输出的token。作为对比,也有一种方案是通过路由的方式组合多个不同规模和性能的模型。路由方式在调用之前已经确定好需要调用哪个模型,直到调用结束。而投机解码在一个 Query 内会反复调用大小模型。 背景 我们都知道,生成式 LLM 大部分是 Decoder-only...
Large Model
2026-03-10

引言 Structured Generation with LLM,是指 让LLM按照预先定义的schema,输出符合schema的结构化结果 。 常见的应用场景有: 数据处理 。主要功能为a -> b,即从源文本中 抽取/生成 符合schema的结果,例如给定新闻,进行分类、抽取关键词、生成总结等; Agent 。主要功能是Tool Calling,即根据用户query,选择适当的tool和入参。 将 LLM 限制为始终生成符合特定模式的、有效的 JSON 或 YAML,是许多应用的关键功能。 Kor Kor ,一个 基于prompt的技术方案 ;Kor比较适合 数据处理 场景,且原理简单、易于理解,适合作为入门, 并且Kor适用于那些不支持function calling的比较旧的模型。 使用Kor进行structured generation的流程如下: 定义schema,包括结构、注释还有例子; Kor用特定的 prompt template ,将用户提供的schema和待处理的raw text,组装成prompt; 将prompt发送给LLM,借助其通用的In...
Large Model
2026-03-10

问题背景 首先简化一下问题,本文所讨论的多模态,主要指图文混合的双模态,即输入和输出都可以是图文。可能有不少读者的第一感觉是:多模态模型难道不也是烧钱堆显卡,Transformer“一把梭”,最终“大力出奇迹”吗? 其实没那么简单。先看文本生成,事实上文本生成自始至终都只有一条主流路线,那就是语言模型,即建模条件概率 \(p(x_t|x_1,\cdots,x_{t-1})\) ,不论是最初的 n-gram语言模型,还是后来的Seq2Seq、GPT,都是这个条件概率的近似。也就是说,一直以来,人们对“实现文本生成需要往哪个方向走”是很明确的,只是背后所用的模型有所不同,比如LSTM、CNN、Attention乃至最近复兴的线性RNN等。所以, 文本生成确实可以All in Transformer来大力出奇迹,因为方向是标准的、清晰的。 然而,对于图像生成,并没有这样的“标准方向”。就本站所讨论过的图像生成模型,就有 VAE 、 GAN 、 Flow 、 Diffusion ,还有小众的 EBM...