
💡 GRPO相比PPO主要优势: 1. 训练更稳定 引入 KL 散度惩罚项,有效控制策略更新的幅度,避免策略崩溃,提高训练的稳定性 GRPO用组内相对优势替代value model,消除了value估计误差 通过组内归一化,自动消除reward scale和bias的影响 实验中发现GRPO的advantage方差比PPO小30%左右,训练崩溃率更低 2. 工程更简单 只需要1-2个模型(policy + reference),而PPO需要4个 显存占用减少50%以上,训练速度提升2-3倍 超参数更少,更容易调优 3. 相对奖励机制 通过对同一输入生成的多个输出进行比较,GRPO 能够更稳定地估计优势函数,减少了训练过程中的方差 背景 GRPO是 DeepSeek-Math model中提出的对PPO方法的改进策略: 强化学习(RL)在提升模型数学推理能力方面被证明是有效的 传统PPO算法需要较大训练资源 GRPO作为PPO的变体被提出,可以更高效地优化模型 PPO Vs GRPO PPO回顾 PPO的目标函数为: \[\begin{aligned}J_{PPO}(\theta) =...
NLP
2026-03-26
词向量,英文名叫Word Embedding,按照字面意思,应该是词嵌入。说到词向量,不少读者应该会立马想到Google出品的Word2Vec,大牌效应就是不一样。另外,用Keras之类的框架还有一个Embedding层,也说是将词ID映射为向量。由于先入为主的意识,大家可能就会将词向量跟Word2Vec等同起来,而反过来问“Embedding是哪种词向量?”这类问题,尤其是对于初学者来说,应该是很混淆的。事实上,哪怕对于老手,也不一定能够很好地说清楚。 这一切,还得从one hot说起... 五十步笑百步 one hot,中文可以翻译为“独热”,是最原始的用来表示字、词的方式。为了简单,本文以字为例,词也是类似的。假如词表中有“科、学、空、间、不、错”六个字,one hot就是给这六个字分别用一个0-1编码: \[\begin{array}{c|c}\hline\text{科} & [1, 0, 0, 0, 0, 0]\\
\text{学} & [0, 1, 0, 0, 0, 0]\\
\text{空} & [0, 0, 1, 0, 0, 0]\\
\text{间} &...

什么是N-Gram模型 N-Gram是一种基于统计语言模型的算法。它的基本思想是将文本里面的内容按照字节进行大小为 \(N\) 的滑动窗口操作,形成了长度是 \(N\) 的字节片段序列。 每一个字节片段称为gram,对所有gram的出现频度进行统计,并且按照事先设定好的阈值进行过滤,形成关键gram列表,也就是这个文本的向量特征空间,列表中的每一种gram就是一个特征向量维度。 该模型基于这样一种假设,第 \(N\) 个词的出现只与前面 \(N-1\) 个词相关,而与其它任何词都不相关,整句的概率就是各个词出现概率的乘积。这些概率可以通过直接从语料中统计 \(N\) 个词同时出现的次数得到。常用的是二元的Bi-Gram和三元的Tri-Gram。 说完了n-gram模型的概念之后,下面讲解n-gram的一般应用。 N -Gram模型用于评估语句是否合理 如果我们有一个由 m 个词组成的序列(或者说一个句子),我们希望算得概率 \(p(w_1,w_2,...,w_m)\) ,根据链式规则,可得...
NLP
2026-03-26

概述 SSM的概念由来已久,但这里我们特指深度学习中的SSM,一般认为其开篇之作是2021年的 S4 ,不算太老,而SSM最新最火的变体大概是 Mamba 。当然,当我们谈到SSM时,也可能泛指一切线性RNN模型,这样 RWKV 、 RetNet 还有此前LRU都可以归入此类。不少SSM变体致力于成为Transformer的竞争者,尽管笔者并不认为有完全替代的可能性,但SSM本身优雅的数学性质也值得学习一番。 尽管我们说SSM起源于S4,但在S4之前,SSM有一篇非常强大的奠基之作 《HiPPO: Recurrent Memory with Optimal Polynomial Projections》 (简称HiPPO),所以本文从HiPPO开始说起。 另外值得一提的是,SSM代表作HiPPO、S4、Mamba的一作都是 Albert Gu ,他还有很多篇SSM相关的作品,毫不夸张地说,这些工作筑起了SSM大厦的基础。不论SSM前景如何,这种坚持不懈地钻研同一个课题的精神都值得我们由衷地敬佩。 今天,基本上你能叫出的任何语言模型都是 Transformer 模型。OpenAI 的...
NLP
2026-03-25

取代RNN——Transformer 在介绍Transformer前我们来回顾一下RNN的结构 对RNN有一定了解的话,一定会知道,RNN有两个很明显的问题 效率问题:需要逐个词进行处理,后一个词要等到前一个词的隐状态输出以后才能开始处理 如果传递距离过长还会有梯度消失、梯度爆炸和遗忘问题 为了缓解传递间的梯度和遗忘问题,设计了各种各样的RNN cell,最著名的两个就是LSTM和GRU了 LSTM (Long Short Term Memory) GRU (Gated Recurrent Unit) 但是,引用网上一个博主的比喻,这么做就像是在给马车换车轮,为什么不直接换成汽车呢? 于是就有了 Transformer 。Transformer 是Google Brain 2017的提出的一篇工作,它针对RNN的弱点进行重新设计,解决了RNN效率问题和传递中的缺陷等,在很多问题上都超过了RNN的表现。Transfromer的基本结构如下图所示,...
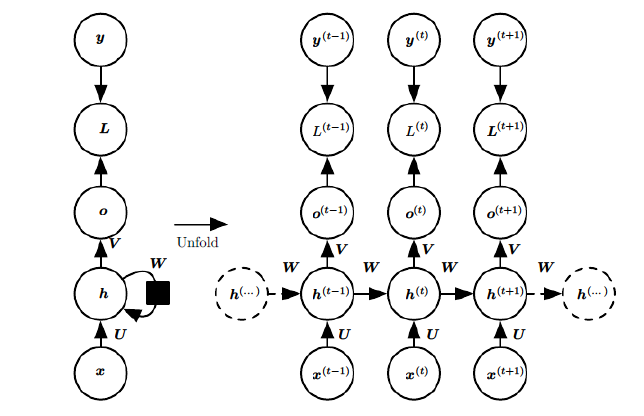
RNN 概述 在前面讲到的DNN和CNN中,训练样本的输入和输出是比较的确定的。但是有一类问题DNN和CNN不好解决,就是训练样本输入是连续的序列,且序列的长短不一,比如基于时间的序列:一段段连续的语音,一段段连续的手写文字。这些序列比较长,且长度不一,比较难直接的拆分成一个个独立的样本来通过DNN/CNN进行训练。 而对于这类问题,RNN则比较的擅长。那么RNN是怎么做到的呢?RNN假设我们的样本是基于序列的。比如是从序列索引1到序列索引 \(τ\) 。对于这其中的任意序列索引号 \(t\) ,它对应的输入是对应的样本序列中的 \(x(t)\) 。而模型在序列索引号 \(t\) 位置的隐藏状态 \(h(t)\) ,则由 \(x(t)\) 和在 \(t−1\) 位置的隐藏状态 \(h(t−1)\) 共同决定。在任意序列索引号 \(t\) ,我们也有对应的模型预测输出 \(o(t)\) 。通过预测输出 \(o(t)\) 和训练序列真实输出 \(y(t)\) ,以及损失函数 \(L(t)\) ,我们就可以用DNN类似的方法来训练模型,接着用来预测测试序列中的一些位置的输出。...
NLP
2026-03-23
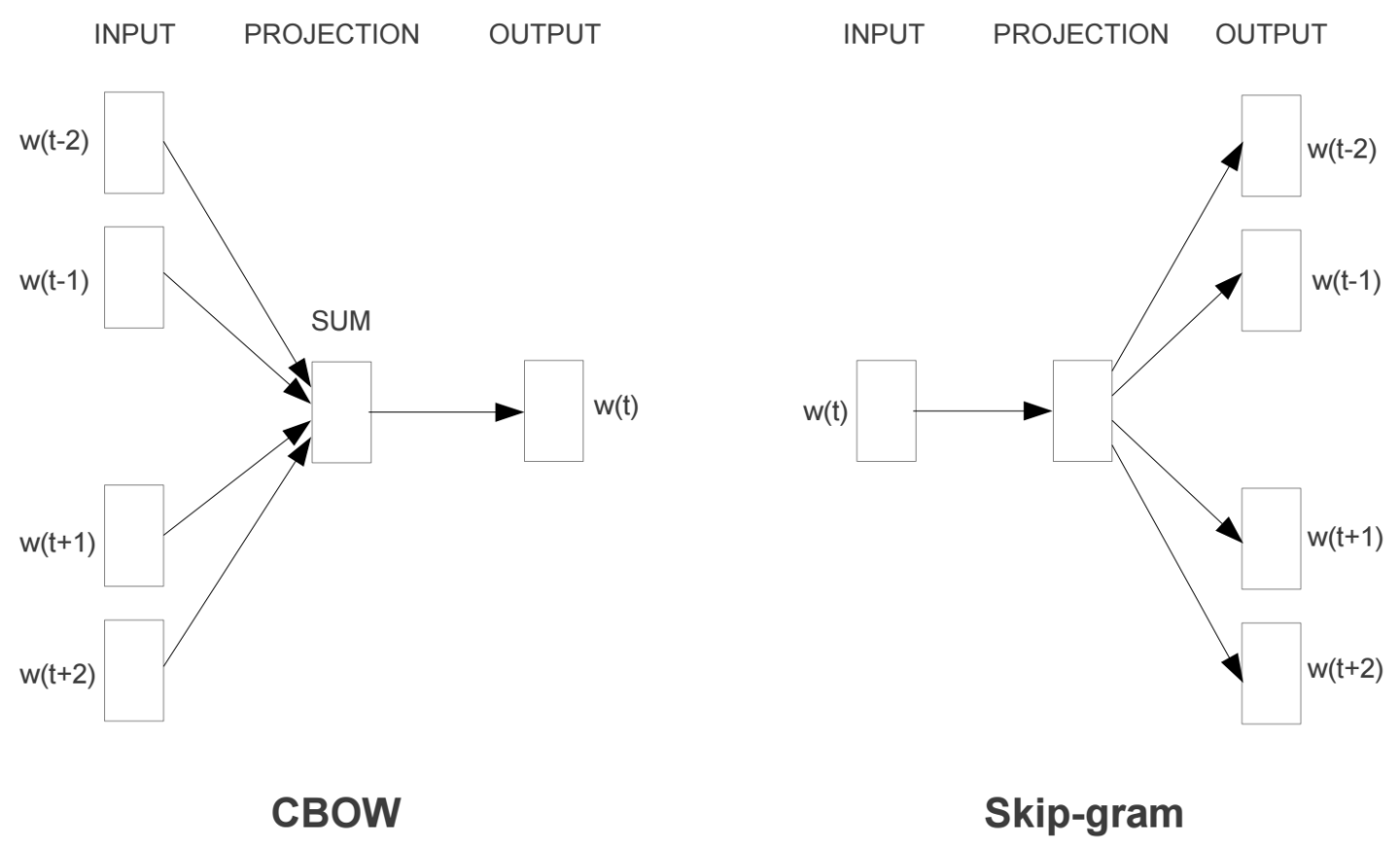
什么是Word2Vec和Embeddings? Word2Vec是从大量文本语料中以无监督的方式学习语义知识的一种模型,它被大量地用在自然语言处理(NLP)中。那么它是如何帮助我们做自然语言处理呢?Word2Vec其实就是通过学习文本来用词向量的方式表征词的语义信息,即 通过一个嵌入空间使得语义上相似的单词在该空间内距离很近 。Embedding其实就是一个映射,将单词从原先所属的空间映射到新的多维空间中,也就是把原先词所在空间嵌入到一个新的空间中去。 我们从直观角度上来理解一下,cat这个单词和kitten属于语义上很相近的词,而dog和kitten则不是那么相近,iphone这个单词和kitten的语义就差的更远了。通过对词汇表中单词进行这种数值表示方式的学习(也就是将单词转换为词向量),能够让我们基于这样的数值进行向量化的操作从而得到一些有趣的结论。比如说,如果我们对词向量kitten、cat以及dog执行这样的操作:kitten - cat + dog,那么最终得到的嵌入向量(embedded vector)将与puppy这个词向量十分相近。 第一部分 模型...

Tokenizer 背景与基础 目前的机器学习模型都是数学模型,其对应的输入要求必须是数字形式(number)的,而我们处理的真实场景往往会包含许多非数字形式的输入(有时候即使原始输入是数字形式,我们也需要转换),最典型的就是 NLP 中的文字(string),为了让文字能够作为输入参与到模型的计算中去,我们就需要构建一个映射关系(mapping):将对应的文字映射到一个数字形式上去,而其对应的数字就是 token。而对应的这个映射关系,就是我们的 tokenizer:他可以将文字映射到其对应的数字上去(encode),也可以将数字映射回对应的文字上(decode)。 诸如GPT-3/4以及LlaMA/LlaMA2大语言模型都采用了token的作为模型的输入输出,其输入是文本,然后将文本转为token(正整数),然后从一串token(对应于文本)预测下一个token。 进入OpenAI官网提供的tokenizer可以看到GPT-3tokenizer采用的方法。这里以Hello World为例说明。...
Machine Learning
2026-03-19
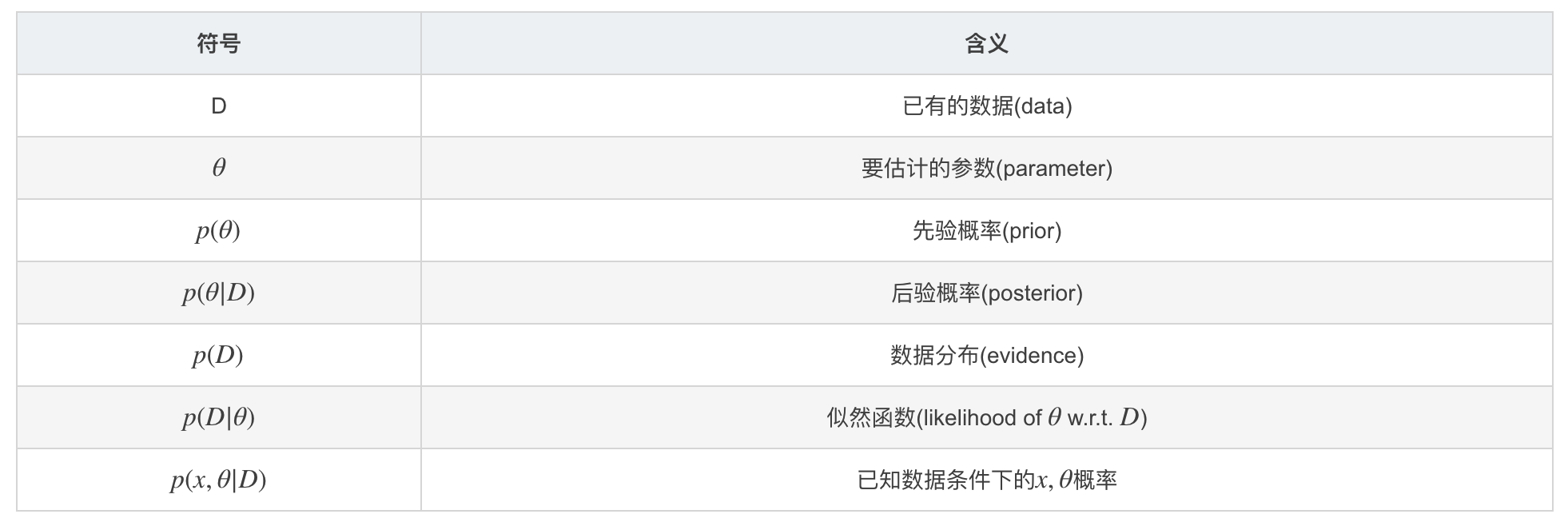
序言 极大似然估计与贝叶斯估计是统计中两种对模型的参数确定的方法,两种参数估计方法使用不同的思想。 前者来自于频率派,认为参数是固定的,我们要做的事情就是根据已经掌握的数据来估计这个参数;而后者属于贝叶斯派,认为参数也是服从某种概率分布的,已有的数据只是在这种参数的分布下产生的。 所以,直观理解上,极大似然估计就是假设一个参数 \(θ\) ,然后根据数据来求出这个 \(θ\) . 而贝叶斯估计的难点在于 \(p(θ)\) 需要人为设定,之后再考虑结合MAP(maximum a posterior)方法来求一个具体的 \(θ\) . 所以极大似然估计与贝叶斯估计最大的不同就在于是否考虑了先验,而两者适用范围也变成了:极大似然估计适用于数据大量,估计的参数能够较好的反映实际情况;而贝叶斯估计则在数据量较少或者比较稀疏的情况下,考虑先验来提升准确率。 预知识 为了更好的讨论,本节会先给出我们要解决的问题,然后给出一个实际的案例。这节不会具体涉及到极大似然估计和贝叶斯估计的细节,但是会提出问题和实例,便于后续方法理解。 问题前提 首先,我们有一堆数据...
Machine Learning
2026-03-19
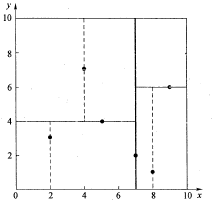
k-d树(k-dimensional树的简称),是一种分割k维数据空间的数据结构。主要应用于 多维空间关键数据的搜索 (如:范围搜索和最近邻搜索)。 应用背景 SIFT算法中做特征点匹配的时候就会利用到k-d树。而特征点匹配实际上就是一个通过距离函数在高维矢量之间进行相似性检索的问题。针对如何快速而准确地找到查询点的近邻,现在提出了很多高维空间索引结构和近似查询的算法,k-d树就是其中一种。 索引结构中相似性查询有两种基本的方式:一种是范围查询(range searches),另一种是K近邻查询(K-neighbor searches)。范围查询就是给定查询点和查询距离的阈值,从数据集中找出所有与查询点距离小于阈值的数据;K近邻查询是给定查询点及正整数K,从数据集中找到距离查询点最近的K个数据,当K=1时,就是最近邻查询(nearest neighbor searches)。...
Machine Learning
2026-03-19
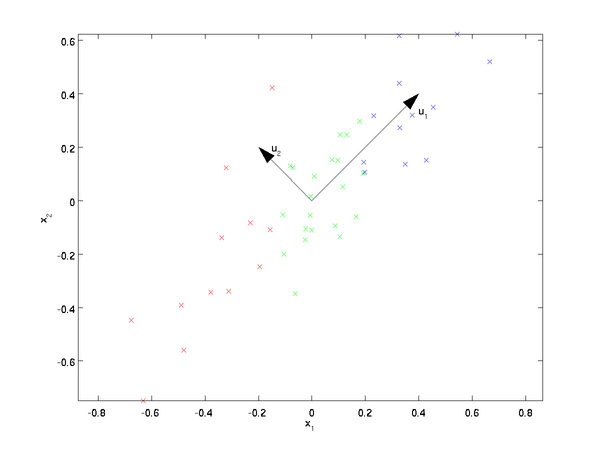
PCA PCA的思想 PCA顾名思义,就是找出数据里最主要的方面,用数据里最主要的方面来代替原始数据。具体的,假如我们的数据集是 \(n\) 维的,共有 \(m\) 个数据 \((𝑥(1),𝑥(2),...,𝑥(𝑚))\) 。我们希望将这 \(m\) 个数据的维度从 \(n\) 维降到 \(n'\) 维,希望这 \(m\) 个 \(n'\) 维的数据集尽可能的代表原始数据集。我们知道数据从 \(n\) 维降到 \(n'\) 维肯定会有损失,但是我们希望损失尽可能的小。那么如何让这 \(n'\) 维的数据尽可能表示原来的数据呢? 我们先看看最简单的情况,也就是 \(n=2\) , \(n'=1\) ,也就是将数据从二维降维到一维。数据如下图。我们希望找到某一个维度方向,它可以代表这两个维度的数据。图中列了两个向量方向, \(u_1\) 和 \(𝑢_2\) ,那么哪个向量可以更好的代表原始数据集呢?从直观上也可以看出, \(𝑢_1\) 比 \(𝑢_2\) 好。 为什么 \(𝑢_1\) 比 \(𝑢_2\)...
Machine Learning
2026-03-18
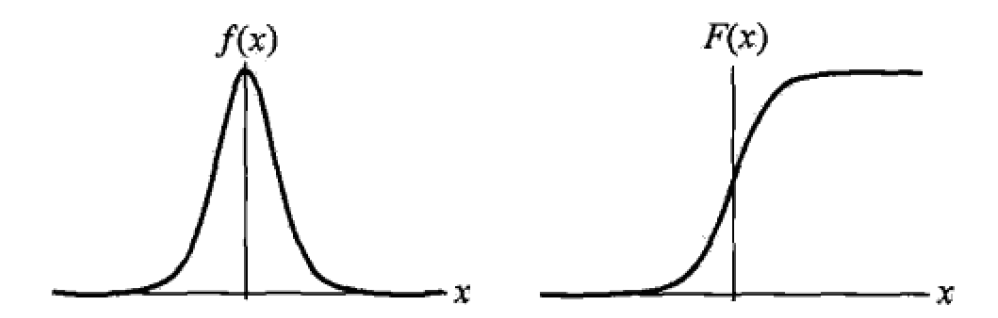
模型介绍 Logistic Regression 虽然被称为回归,但其实际上是分类模型,并常用于二分类。Logistic Regression 因其简单、可并行化、可解释强深受工业界喜爱。 Logistic 回归的本质是:假设数据服从这个分布,然后使用极大似然估计做参数的估计。 Logistic 分布 Logistic 分布是一种连续型的概率分布,其 分布函数 和 密度函数 分别为: \[F(x)=P(X\le x)=\frac{1}{1+e^{-(x-\mu)/\gamma}}\\ f(x)=F^{'}(x)=\frac{e^{-(x-\mu)/\gamma}}{\gamma(1+e^{-(x-\mu)/\gamma})^2}\] 其中, \(\mu\) 表示位置参数, \(\gamma\) 为形状参数。我们可以看下其图像特征: Logistic 分布是由其位置和尺度参数定义的连续分布。Logistic 分布的形状与正态分布的形状相似,但是 Logistic 分布的尾部更长,所以我们可以使用 Logistic...