
11. 盛最多水的容器 题目 给定一个长度为 n 的整数数组 height 。有 n 条垂线,第 i 条线的两个端点是 (i, 0) 和 (i, height[i]) 。 找出其中的两条线,使得它们与 x 轴共同构成的容器可以容纳最多的水。 返回容器可以储存的最大水量。 说明: 你不能倾斜容器。 示例 1: 输入:[1,8,6,2,5,4,8,3,7]
输出:49
解释:图中垂直线代表输入数组 [1,8,6,2,5,4,8,3,7]。在此情况下,容器能够容纳水(表示为蓝色部分)的最大值为 49。 示例 2: 输入:height = [1,1]
输出:1 提示: n == height.length 2 <= n <= 10 5 0 <= height[i] <= 10 4 题解 在初始时,左右指针分别指向数组的左右两端,它们可以容纳的水量为 \(min(1,7)∗8=8\) 。 此时我们需要移动一个指针。移动哪一个呢?直觉告诉我们,应该移动对应数字较小的那个指针(即此时的左指针)。这是因为,由于容纳的水量是由 两个指针指向的数字中较小值∗指针之间的距离...
129. 滑动窗口最大值 题目 给你一个整数数组 nums ,有一个大小为 k 的滑动窗口从数组的最左侧移动到数组的最右侧。你只可以看到在滑动窗口内的 k 个数字。滑动窗口每次只向右移动一位。 返回 滑动窗口中的最大值 。 示例 1: 输入:nums = [1,3,-1,-3,5,3,6,7], k = 3
输出:[3,3,5,5,6,7]
解释:
滑动窗口的位置 最大值
--------------- -----
[1 3 -1] -3 5 3 6 7 3
1 [3 -1 -3] 5 3 6 7 3
1 3 [-1 -3 5] 3 6 7 5
1 3 -1 [-3 5 3] 6 7 5
1 3 -1 -3 [5 3 6] 7 6
1 3 -1 -3 5 [3 6 7] 7 示例 2: 输入:nums = [1], k = 1
输出:[1] 提示: 1 <= nums.length...
Generative Model
2026-01-18

简介 如果以概率的视角看待世界的生成模型。 在这样的世界观中,我们可以将任何类型的观察数据(例如 \(D\) )视为来自底层分布(例如 \( p_{data}\) )的有限样本集。 任何生成模型的目标都是在访问数据集 \(D\) 的情况下近似该数据分布。 如果我们能够学习到一个好的生成模型,我们可以将学习到的模型用于下游推理。 我们主要对数据分布的参数近似感兴趣,在一组有限的参数中,它总结了关于数据集 \(D\) 的所有信息。 与非参数模型相比,参数模型在处理大型数据集时能够更有效地扩展,但受限于可以表示的分布族。 在参数的设置中,我们可以将学习生成模型的任务视为在模型分布族中挑选参数,以最小化模型分布和数据分布之间的距离。 如上图,给定一个狗的图像数据集,我们的目标是学习模型族 \(M\) 中生成模型 θ 的参数,使得模型分布 \(p_θ\) 接近 \(p_{data}\) 上的数据分布。 在数学上,我们可以将我们的目标指定为以下优化问题: \[\mathop{min}\limits_{\theta\in M}d(p_\theta,p_{data})\] 其中, \(d()\)...
Generative Model
2026-01-18

研究对象与基本设定 我们希望学习一个能够“生成数据”的概率模型。假设我们有一个数据集 \(D\) ,每个样本是 \(n\) 维二值向量: \(x \in \{0,1\}^n\) 我们的目标是用一个参数化分布 \(p_\theta(x)\) 去逼近真实数据分布 \(p_{\text{data}}(x)\) ,并最终能够: 密度估计 :给定 \(x\) 计算 \(p_\theta(x)\) 或 \(\log p_\theta(x)\) 采样生成 :从 \(p_\theta(x)\) 采样得到新的 \(x\) 表示:链式法则与自回归分解 链式法则分解联合分布 任意联合分布都可用概率链式法则分解为条件概率的乘积: \[p(x) = \prod_{i=1}^{n} p(x_i \mid x_1, x_2, \dots, x_{i-1}) = \prod_{i=1}^{n} p(x_i \mid x_{<i})\] 其中: \(x_{<i} = [x_1, x_2, \dots, x_{i-1}]\) ,这意味着:只要我们能为每个维度 \(i\) 学好一个条件分布 \(p(x_i \mid...
Self-Supervised
2026-01-18

the machine predicts any parts of its input for any observed part 这是LeCun在AAAI 2020上对自监督学习的定义,再结合传统的自监督学习定义,可以总结如下两点特征: 通过“半自动”过程从数据本身获取“标签”; 从“其他部分”预测部分数据。 个人理解, 其实任意挖掘对象之间联系、探索不同对象共同本质的方法,都或多或少算是自监督学习的思想 。 自监督学习与无监督学习的区别主要在于,无监督学习专注于检测特定的数据模式,如聚类、社区发现或异常检测,而自监督学习的目标是恢复(recovering),仍处于监督学习的范式中。上图展示了三者之间的区别, 自监督中的“related information” 可以来自其他模态、输入的其他部分以及输入的不同形式。 Self-Supervised...
Computer Vision
2026-01-11
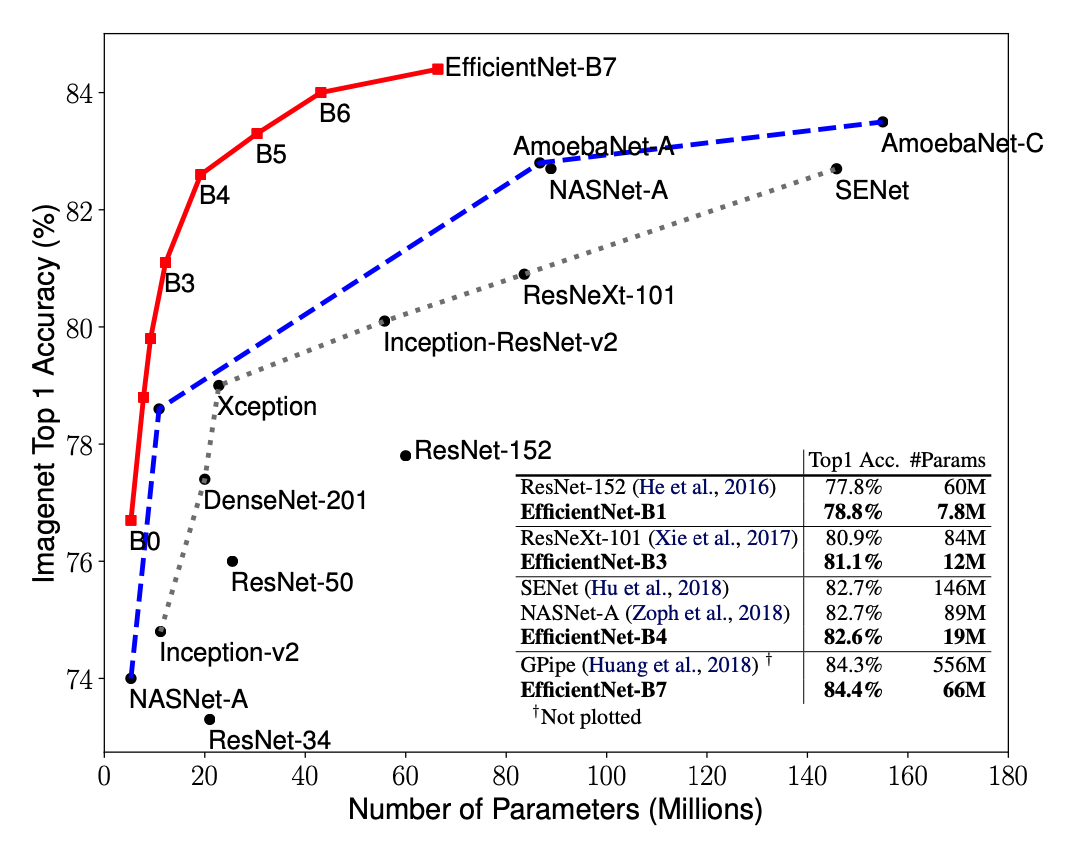
简介 EfficientNet源自Google Brain的论文EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. 从标题也可以看出,这篇论文最主要的创新点是Model Scaling. 论文提出了compound scaling,混合缩放,把网络缩放的三种方式:深度、宽度、分辨率,组合起来按照一定规则缩放,从而提高网络的效果。EfficientNet在网络变大时效果提升明显,把精度上限进一步提升,成为了当前最强网络。EfficientNetB7在ImageNet上获得了最先进的 84.4%的top1精度 和 97.1%的top5精度,比之前最好的卷积网络(GPipe, Top1: 84.3%, ...
Generative Model
2026-01-11

给定一个包含 n 维数据 x 的数据集 D , 简单起见,假设数据 [Math] . 由于真正对联合分布建模的时候, x,y 都是随机变量,故而只需讨论 p(X)=p(x_1,...,x_n) 即可,毕竟只需要令 x_n=y 即可。 给定一个具体的任务,如MNIST中的手写数字二值图分类,从Generative的角度进行Represent,并在Inference中Learning. 下面先介绍: 描述如何对这个MINST任务建模 p(X,Y) (Representation) 对MNIST任务建模 对于一张pixel为 [Math] 大小的图片,令 x_1 表示第一个pixel的随机变量, [Math] ,需明确: 任务目标:学习一个模型分布 [Math] ,使采样时 [Math] , x ...
Computer Vision
2026-01-11

💡 轻量级网络系列 Introduction Inception 在最初的版本 Inception/GoogleNet,其核心思想是利用多尺寸卷积核去观察输入数据。举个栗子,我们看某个景象由于远近不同,同一个物体的大小也会有所不同,那么不同尺度的卷积核观察的特征就会有这样的效果。于是就有了如下的网络结构图: 于是我们的网络就变胖了,通过增加网络的宽度,提高了对于不同尺度的适应程度。但这样的话,计算量有点大了。 Pointwise Conv 为了减少在上面结构的参数量并降低计算量,于是在 Inception V1 的基础版本上加上了 1x1 卷积核,这就形成了 Inception V1 的最终网络结构,如下图。 这个 1x1 卷积就是 Pointwise Convolution,简称 PW。利...
Computer Vision
2026-01-11

网络整体介绍 ThunderNet的整体架构如下图所示。 ThunderNet使用320×320像素作为网络的输入分辨率。整体的网络结构分为两部分:Backbone部分和Detection部分。网络的骨干部分为SNet,SNet是基于ShuffleNetV2进行修改得到的。 网络的检测部分,利用了压缩的RPN网络,修改自LightHead RCNN网络用以提高效率。 并提出Context Enhancement Module整合局部和全局特征增强网络特征表达能力。 并提出Spatial Attention Module空间注意模块,引入来自RPN的前后景信息用以优化特征分布。 backbone 部分 1.输入分辨率 为了加快推理(前向操作)速度,作者使用320320大小的输入图像。需要注意的...