129. 滑动窗口最大值 题目 给你一个整数数组 nums ,有一个大小为 k 的滑动窗口从数组的最左侧移动到数组的最右侧。你只可以看到在滑动窗口内的 k 个数字。滑动窗口每次只向右移动一位。 返回 滑动窗口中的最大值 。 示例 1: 输入:nums = [1,3,-1,-3,5,3,6,7], k = 3
输出:[3,3,5,5,6,7]
解释:
滑动窗口的位置 最大值
--------------- -----
[1 3 -1] -3 5 3 6 7 3
1 [3 -1 -3] 5 3 6 7 3
1 3 [-1 -3 5] 3 6 7 5
1 3 -1 [-3 5 3] 6 7 5
1 3 -1 -3 [5 3 6] 7 6
1 3 -1 -3 5 [3 6 7] 7 示例 2: 输入:nums = [1], k = 1
输出:[1] 提示: 1 <= nums.length...
Generative Model
2026-01-19
基于文章 《Elucidating the Design Space of Diffusion-Based Generative Models》 来统一扩散模型框架 通用扩散模型框架推导 加噪公式 Flow Matching的一步加噪公式 \[\mathbf{x}_t=(1-t)\mathbf{x}_0+t\varepsilon\] 写成概率分布形式: \[p(\mathbf{x}_t|\mathbf{x}_0)=\mathcal{N}(\mathbf{x}_t;(1-t)\mathbf{x}_0,t^2\mathbf{I})\] Score Matching的一步加噪公式 \[\mathbf{x}_t=\mathbf{x}_0+\sigma_t\varepsilon \] 写成概率分布形式: \[p(\mathbf{x}_t|\mathbf{x}_0)=\mathcal{N}(\mathbf{x}_t;\mathbf{x}_0,\sigma_t^2\mathbf{I})\] DDPM/DDIM的一步加噪公式...
Generative Model
2026-01-18

简介 如果以概率的视角看待世界的生成模型。 在这样的世界观中,我们可以将任何类型的观察数据(例如 \(D\) )视为来自底层分布(例如 \( p_{data}\) )的有限样本集。 任何生成模型的目标都是在访问数据集 \(D\) 的情况下近似该数据分布。 如果我们能够学习到一个好的生成模型,我们可以将学习到的模型用于下游推理。 我们主要对数据分布的参数近似感兴趣,在一组有限的参数中,它总结了关于数据集 \(D\) 的所有信息。 与非参数模型相比,参数模型在处理大型数据集时能够更有效地扩展,但受限于可以表示的分布族。 在参数的设置中,我们可以将学习生成模型的任务视为在模型分布族中挑选参数,以最小化模型分布和数据分布之间的距离。 如上图,给定一个狗的图像数据集,我们的目标是学习模型族 \(M\) 中生成模型 θ 的参数,使得模型分布 \(p_θ\) 接近 \(p_{data}\) 上的数据分布。 在数学上,我们可以将我们的目标指定为以下优化问题: \[\mathop{min}\limits_{\theta\in M}d(p_\theta,p_{data})\] 其中, \(d()\)...
Generative Model
2026-01-18

研究对象与基本设定 我们希望学习一个能够“生成数据”的概率模型。假设我们有一个数据集 \(D\) ,每个样本是 \(n\) 维二值向量: \(x \in \{0,1\}^n\) 我们的目标是用一个参数化分布 \(p_\theta(x)\) 去逼近真实数据分布 \(p_{\text{data}}(x)\) ,并最终能够: 密度估计 :给定 \(x\) 计算 \(p_\theta(x)\) 或 \(\log p_\theta(x)\) 采样生成 :从 \(p_\theta(x)\) 采样得到新的 \(x\) 表示:链式法则与自回归分解 链式法则分解联合分布 任意联合分布都可用概率链式法则分解为条件概率的乘积: \[p(x) = \prod_{i=1}^{n} p(x_i \mid x_1, x_2, \dots, x_{i-1}) = \prod_{i=1}^{n} p(x_i \mid x_{<i})\] 其中: \(x_{<i} = [x_1, x_2, \dots, x_{i-1}]\) ,这意味着:只要我们能为每个维度 \(i\) 学好一个条件分布 \(p(x_i \mid...
Self-Supervised
2026-01-18

the machine predicts any parts of its input for any observed part 这是LeCun在AAAI 2020上对自监督学习的定义,再结合传统的自监督学习定义,可以总结如下两点特征: 通过“半自动”过程从数据本身获取“标签”; 从“其他部分”预测部分数据。 个人理解, 其实任意挖掘对象之间联系、探索不同对象共同本质的方法,都或多或少算是自监督学习的思想 。 自监督学习与无监督学习的区别主要在于,无监督学习专注于检测特定的数据模式,如聚类、社区发现或异常检测,而自监督学习的目标是恢复(recovering),仍处于监督学习的范式中。上图展示了三者之间的区别, 自监督中的“related information” 可以来自其他模态、输入的其他部分以及输入的不同形式。 Self-Supervised...
Generative Model
2026-01-11

Diffusion Models from SDE 连续扩散模型 (Continuous Diffusion Models) 将传统的离散时间扩散过程扩展到连续时间域,可以被视为一个随机过程,使用随机微分方程(SDE)来描述。其前向过程可以写成如下形式: [公式] 其中, f(x,t) 可以看成偏移系数, g(t) 可以看成是扩散系数, dw 是标准布朗运动。这个SDE 描述了数据在连续时间域内如何被噪声逐渐破坏。 这个随机过程的逆向过程存在(更准确的描述:下面的逆向时间SDE具有与正向过程SDE相同的联合分布)为 [公式] 前面我们得到了扩散过程的逆向过程可以用一个SDE描述(逆向随机过程),事实上,存在一个确定性过程 (用ODE描述)也是它的逆向过程 (更准确的描述:这个ODE过程的在任...
Python
2026-01-11
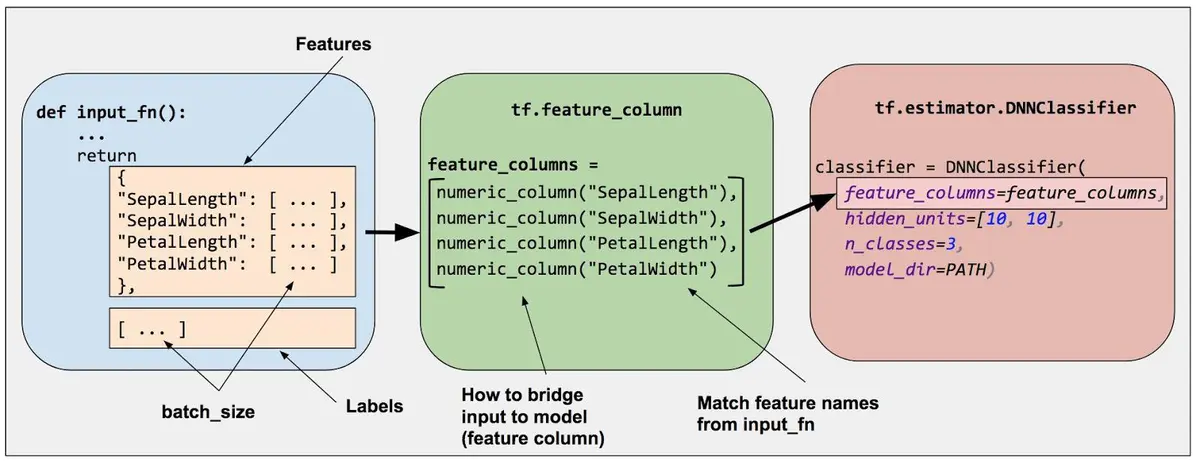
Overview 特征工程是机器学习流程中重要的一个环节,即使是通常用来做端到端学习的深度学习模型在训练之前也免不了要做一些特征工程相关的工作。Tensorflow平台提供的FeatureColumn API为特征工程提供了强大的支持。 Feature cloumns是原始数据和Estimator模型之间的桥梁,它们被用来把各种形式的原始数据转换为模型能够使用的格式。深度神经网络只能处理数值数据,网络中的每个神经元节点执行一些针对输入数据和网络权重的乘法和加法运算。然而,现实中的有很多非数值的类别数据,比如产品的品牌、类目等,这些数据如果不加转换,神经网络是无法处理的。另一方面,即使是数值数据,在仍给网络进行训练之前有时也需要做一些处理,比如标准化、离散化等。 在Tensorflow中,通过...
Python
2026-01-11
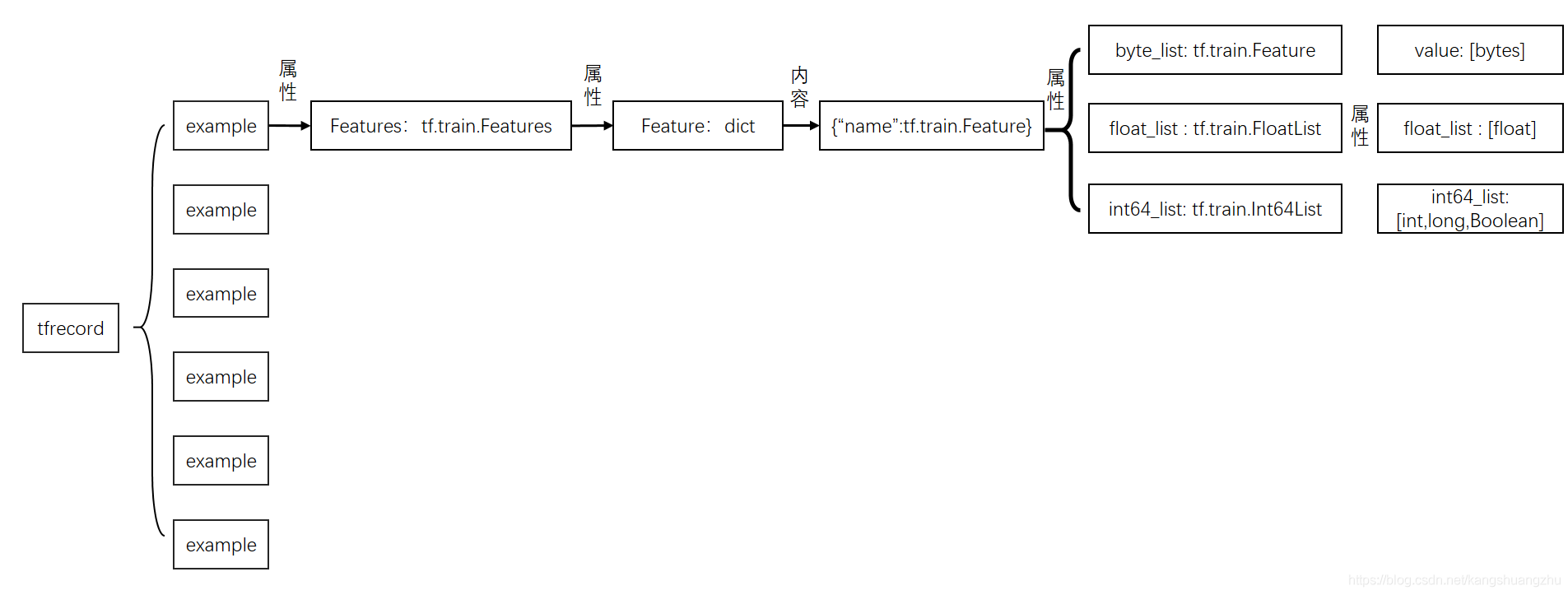
TFRecord TFRecord 是谷歌推荐的一种二进制文件格式,理论上它可以保存任何格式的信息。 tf.Example是一个Protobuffer定义的message,表达了一组string到bytes value的映射。TFRecord文件里面其实就是存储的序列化的tf.Example。关于Protobuffer参考Protobuf 终极教程。 example 我们可以具体到相关代码去详细地看下tf.Example的构成。作为一个Protobuffer message,它被定义在文件core/example/example.proto中: [代码] 只是包了一层Features的message。我们还需要进一步去查找Features的message定义: [代码] 到这里,我们可以看出...
Generative Model
2026-01-11

💡 Score based generative model SMLD的关键点: 正式开始介绍之前首先解答一下这个问题:scorebased 模型是什么东西,微分方程在这个模型里到底有什么用?我们知道生成模型基本都是从某个现有的分布中进行采样得到生成的样本,为此模型需要完成对分布的建模。根据建模方式的不同可以分为隐式建模(例如 GAN、diffusion models)和显式建模(例如 VAE、normalizing flows)。和上述的模型相同,scorebased 模型也是用一定方式对分布进行了建模。具体而言,这类模型建模的对象是概率分布函数 log 的梯度,也就是 score function,而为了对这个建模对象进行学习,需要使用一种叫做 score matching 的技术,这也...
Generative Model
2026-01-11

给定一个包含 n 维数据 x 的数据集 D , 简单起见,假设数据 [Math] . 由于真正对联合分布建模的时候, x,y 都是随机变量,故而只需讨论 p(X)=p(x_1,...,x_n) 即可,毕竟只需要令 x_n=y 即可。 给定一个具体的任务,如MNIST中的手写数字二值图分类,从Generative的角度进行Represent,并在Inference中Learning. 下面先介绍: 描述如何对这个MINST任务建模 p(X,Y) (Representation) 对MNIST任务建模 对于一张pixel为 [Math] 大小的图片,令 x_1 表示第一个pixel的随机变量, [Math] ,需明确: 任务目标:学习一个模型分布 [Math] ,使采样时 [Math] , x ...
Generative Model
2026-01-11

💡 随机微分 在DDPM中,扩散过程被划分为了固定的T步,还是用DDPM中的类比来说,就是“拆楼”和“建楼”都被事先划分为了T步,这个划分有着相当大的人为性。事实上,真实的“拆”、“建”过程应该是没有刻意划分的步骤的,我们可以将它们理解为一个在时间上连续的变换过程,可以用随机微分方程(Stochastic Differential Equation,SDE)来描述。 为此,我们用下述SDE描述前向过程(“拆楼”): [公式] 相信很多读者都对SDE很陌生,笔者也只是在硕士阶段刚好接触过一段时间,略懂皮毛。不过不懂不要紧,我们只需要将它看成是下述离散形式在 [Math] 时的极限: [公式] 再直白一点,如果假设拆楼需要1天,那么拆楼就是 [Math] 从 t=0 到 t=1 的变化过程,每一...