
11. 盛最多水的容器 题目 给定一个长度为 n 的整数数组 height 。有 n 条垂线,第 i 条线的两个端点是 (i, 0) 和 (i, height[i]) 。 找出其中的两条线,使得它们与 x 轴共同构成的容器可以容纳最多的水。 返回容器可以储存的最大水量。 说明: 你不能倾斜容器。 示例 1: 输入:[1,8,6,2,5,4,8,3,7]
输出:49
解释:图中垂直线代表输入数组 [1,8,6,2,5,4,8,3,7]。在此情况下,容器能够容纳水(表示为蓝色部分)的最大值为 49。 示例 2: 输入:height = [1,1]
输出:1 提示: n == height.length 2 <= n <= 10 5 0 <= height[i] <= 10 4 题解 在初始时,左右指针分别指向数组的左右两端,它们可以容纳的水量为 \(min(1,7)∗8=8\) 。 此时我们需要移动一个指针。移动哪一个呢?直觉告诉我们,应该移动对应数字较小的那个指针(即此时的左指针)。这是因为,由于容纳的水量是由 两个指针指向的数字中较小值∗指针之间的距离...
Computer Vision
2026-01-11
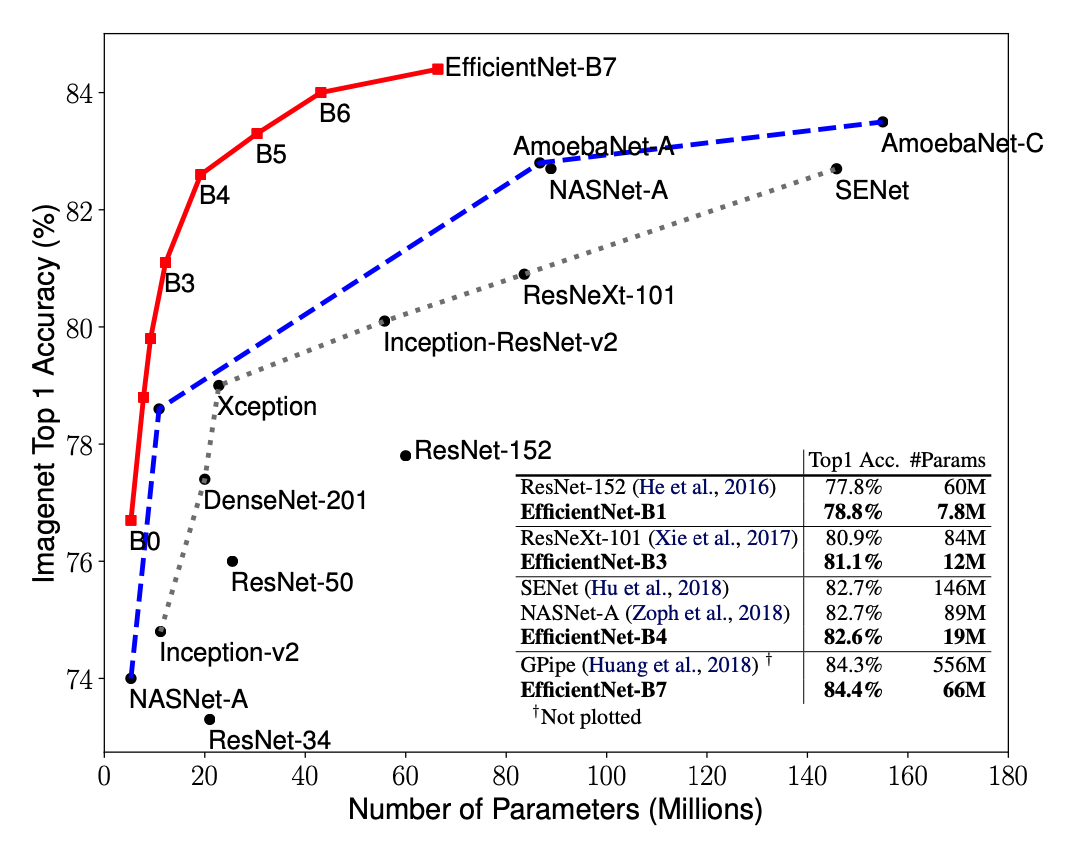
简介 EfficientNet源自Google Brain的论文EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. 从标题也可以看出,这篇论文最主要的创新点是Model Scaling. 论文提出了compound scaling,混合缩放,把网络缩放的三种方式:深度、宽度、分辨率,组合起来按照一定规则缩放,从而提高网络的效果。EfficientNet在网络变大时效果提升明显,把精度上限进一步提升,成为了当前最强网络。EfficientNetB7在ImageNet上获得了最先进的 84.4%的top1精度 和 97.1%的top5精度,比之前最好的卷积网络(GPipe, Top1: 84.3%, ...

Quick Start 一个最简单的DDP Pytorch例子! 环境准备 PyTorch(gpu)=1.5,python=3.6 推荐使用官方打好的PyTorch docker,避免乱七八糟的环境问题影响心情。 [代码] 代码 单GPU代码 [代码] 加入DDP的代码 [代码] DDP的基本原理 大白话原理 假如我们有N张显卡, 1. (缓解GIL限制)在DDP模式下,会有N个进程被启动,每个进程在一张卡上加载一个模型,这些模型的参数在数值上是相同的。 1. (RingReduce加速)在模型训练时,各个进程通过一种叫RingReduce的方法与其他进程通讯,交换各自的梯度,从而获得所有进程的梯度; 1. (实际上就是Data Parallelism)各个进程用平均后的梯度更新自己的参数,...
Python
2026-01-11
@tf_export为函数取了个名字! Tensorflow经常看到定义的函数前面加了@tf_export。例如,tensorflow/python/platform/app.py中有: [代码] 首先,@tf_export是一个修饰符。修饰符的本质是一个函数 tf_export的实现在tensorflow/python/util/tf_export.py中: [代码] 等号的右边的理解分两步: 1. functools.partial 1. api_export functools.partial是偏函数,它的本质简而言之是为函数固定某些参数。如:functools.partial(FuncA, p1)的作用是把函数FuncA的第一个参数固定为p1;又如functools.partial(...
PyTorch中,所有神经网络的核心是 autograd 包。 autograd 包为张量上的所有操作提供了自动求导机制。它是一个在运行时定义(definebyrun)的框架,这意味着反向传播是根据代码如何运行来决定的,并且每次迭代可以是不同的. 让我们用一些简单的例子来看看吧。 张量 torch.Tensor 是这个包的核心类。如果设置它的属性 .requires_grad 为 True,那么它将会追踪对于该张量的所有操作。当完成计算后可以通过调用 .backward(),来自动计算所有的梯度。这个张量的所有梯度将会自动累加到.grad属性. 要阻止一个张量被跟踪历史,可以调用 .detach() 方法将其与计算历史分离,并阻止它未来的计算记录被跟踪。 为了防止跟踪历史记录(和使用内存),...
Python
2026-01-11

相同点 nn.Xxx和nn.functional.xxx的实际功能是相同的,即nn.Conv2d和nn.functional.conv2d 都是进行卷积,nn.Dropout 和nn.functional.dropout都是进行dropout,。。。。。; 运行效率也是近乎相同。 nn.functional.xxx是函数接口,而nn.Xxx是nn.functional.xxx的类封装,并且nn.Xxx都继承于一个共同祖先nn.Module。这一点导致nn.Xxx除了具有nn.functional.xxx功能之外,内部附带了nn.Module相关的属性和方法,例如train(), eval(),load_state_dict, state_dict 等。 不同点 两者的调用方式不同。 nn.X...
Computer Vision
2026-01-11

💡 轻量级网络系列 Introduction Inception 在最初的版本 Inception/GoogleNet,其核心思想是利用多尺寸卷积核去观察输入数据。举个栗子,我们看某个景象由于远近不同,同一个物体的大小也会有所不同,那么不同尺度的卷积核观察的特征就会有这样的效果。于是就有了如下的网络结构图: 于是我们的网络就变胖了,通过增加网络的宽度,提高了对于不同尺度的适应程度。但这样的话,计算量有点大了。 Pointwise Conv 为了减少在上面结构的参数量并降低计算量,于是在 Inception V1 的基础版本上加上了 1x1 卷积核,这就形成了 Inception V1 的最终网络结构,如下图。 这个 1x1 卷积就是 Pointwise Convolution,简称 PW。利...
Computer Vision
2026-01-11

网络整体介绍 ThunderNet的整体架构如下图所示。 ThunderNet使用320×320像素作为网络的输入分辨率。整体的网络结构分为两部分:Backbone部分和Detection部分。网络的骨干部分为SNet,SNet是基于ShuffleNetV2进行修改得到的。 网络的检测部分,利用了压缩的RPN网络,修改自LightHead RCNN网络用以提高效率。 并提出Context Enhancement Module整合局部和全局特征增强网络特征表达能力。 并提出Spatial Attention Module空间注意模块,引入来自RPN的前后景信息用以优化特征分布。 backbone 部分 1.输入分辨率 为了加快推理(前向操作)速度,作者使用320320大小的输入图像。需要注意的...
Python
2026-01-11

unsupported operation: more than one element of the writtento tensor refers to a single memory location. Please clone() the tensor before performing the operation. 出现这种情况可能是在.backward()之前使用了 .expand()或者.expand_as()函数。具体原因可以看看这个老哥的提问:link 解决办法:在 .expand()或者.expand_as()函数后面添加.clone()就可以解决。