76. 最小覆盖子串 题目 给定两个字符串 s 和 t ,长度分别是 m 和 n ,返回 s 中的 最短窗口 子串 ,使得该子串包含 t 中的每一个字符( 包括重复字符 )。如果没有这样的子串,返回空字符串 "" 。 测试用例保证答案唯一。 示例 1: 输入:s = "ADOBECODEBANC", t = "ABC"
输出:"BANC"
解释:最小覆盖子串 "BANC" 包含来自字符串 t 的 'A'、'B' 和 'C'。 示例 2: 输入:s = "a", t = "a"
输出:"a"
解释:整个字符串 s 是最小覆盖子串。 示例 3: 输入: s = "a", t = "aa"
输出: ""
解释: t 中两个字符 'a' 均应包含在 s 的子串中,
因此没有符合条件的子字符串,返回空字符串。 提示: m == s.length n == t.length 1 <= m, n <= 10 5 s 和 t 由英文字母组成 题解 这是一个经典的 滑动窗口 (Sliding Window) 问题 我们需要维护一个动态的窗口 [left, right] : 右移扩大 :不断移动...
Computer Vision
2026-01-11

在正式介绍之前,先简单回顾一下现有的两大类方法。第一大类,也是从非Deep时代,乃至CV初期就被就被广泛使用的方法叫做image pyramid。在image pyramid中,我们直接对图像进行不同尺度的缩放,然后将这些图像直接输入到detector中去进行检测。虽然这样的方法十分简单,但其效果仍然是最佳,也后续启发了SNIP这一系列的工作。单论性能而言,multiscale training/testing仍然是一个不可缺少的组件。然而其缺点也是很明显的,测试时间大幅度提高,对于实际使用并不友好。 另外一大类方法,也是Deep方法所独有的,也就是feature pyramid。最具代表性的工作便是经典的FPN了。这一类方法的思想是直接在feature层面上来近似image pyramid...
Computer Vision
2026-01-11
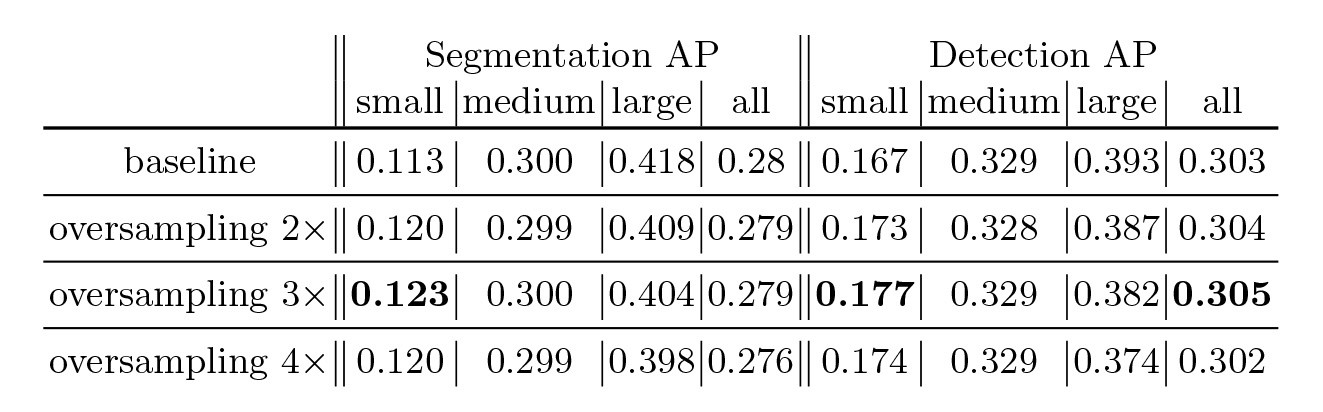
在深度学习目标检测中,特别是人脸检测中,由于分辨率低、图像模糊、信息少、噪声多,小目标和小人脸的检测一直是一个实用和常见的难点问题。然而,在过去几年的发展中,也出现了一些提高小目标检测性能的解决方案。本文将对这些方法进行分析、整理和总结。 图像金字塔和多尺度滑动窗口检测 一开始,在深学习方法成为流行之前,对于不同尺度的目标,通常是从原始图像开始,使用不同的分辨率构建图像金字塔,然后使用分类器对金字塔的每一层进行滑动窗口的目标检测。 在著名的人脸检测器MTCNN中,使用图像金字塔法检测不同分辨率的人脸目标。然而,这种方法通常是缓慢的,虽然构建图像金字塔可以使用卷积核分离加速或简单粗暴地缩放,但仍需要做多个特征提取,后来有人借其想法想出一个特征金字塔网络FPN,在不同层融合特征,只需要一次正向计...
Computer Vision
2026-01-11
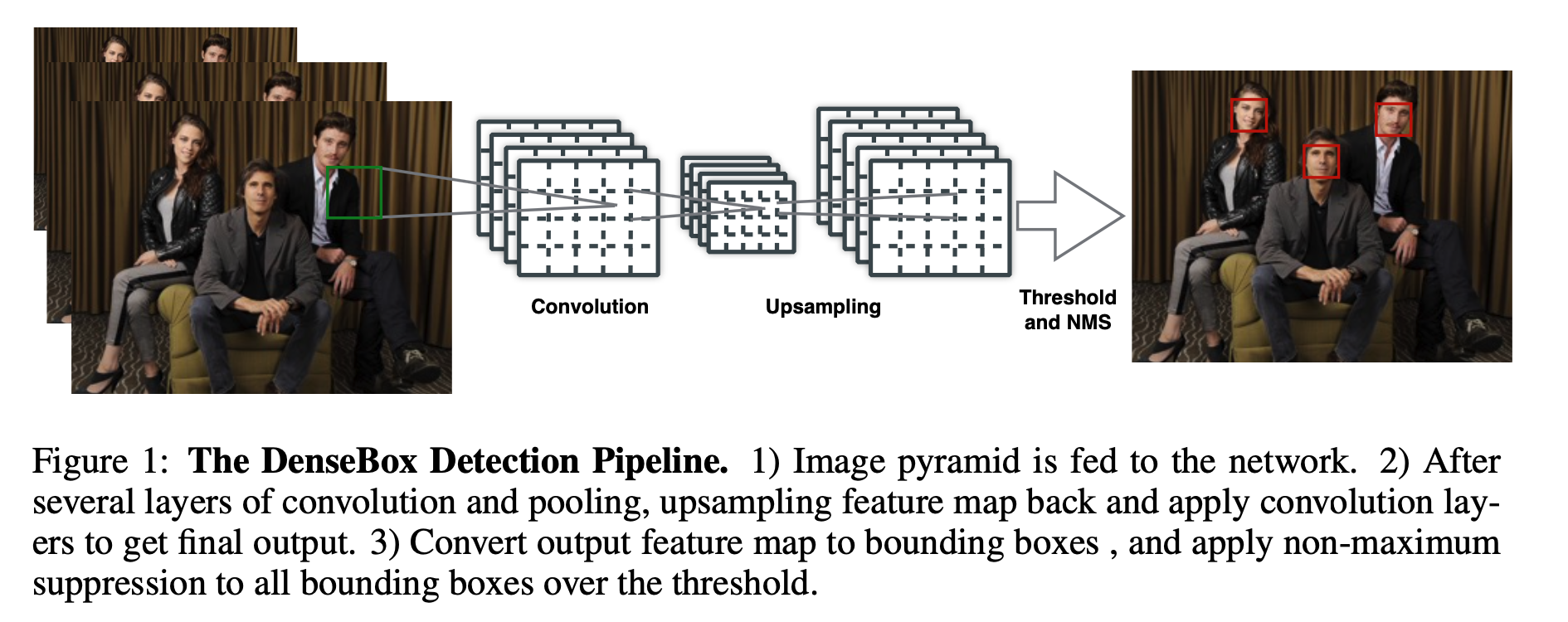
简介 "Anchorfree"(无锚点)是一种目标检测方法,与传统的使用锚框(anchor boxes)的方法(例如Faster RCNN)不同。在传统方法中,锚框是预先定义的、具有不同尺寸和长宽比的矩形区域,用于捕捉不同尺寸和形状的目标。而在"anchorfree"方法中,不再使用锚框,而是直接预测目标的位置和形状,通常使用网络输出的热图和偏移信息。 以下是对"anchorfree"方法的一些关键理解点: 无需预定义锚框: 在传统目标检测方法中,需要事先定义和生成一组锚框,这可能需要大量的人工工作。而在"anchorfree"方法中,不再需要锚框,模型可以自动学习目标的位置和形状。 直接位置和形状回归: "anchorfree"方法通过输出的热图来表示目标的存在概率,并使用偏移信息来定位目...
Computer Vision
2026-01-11
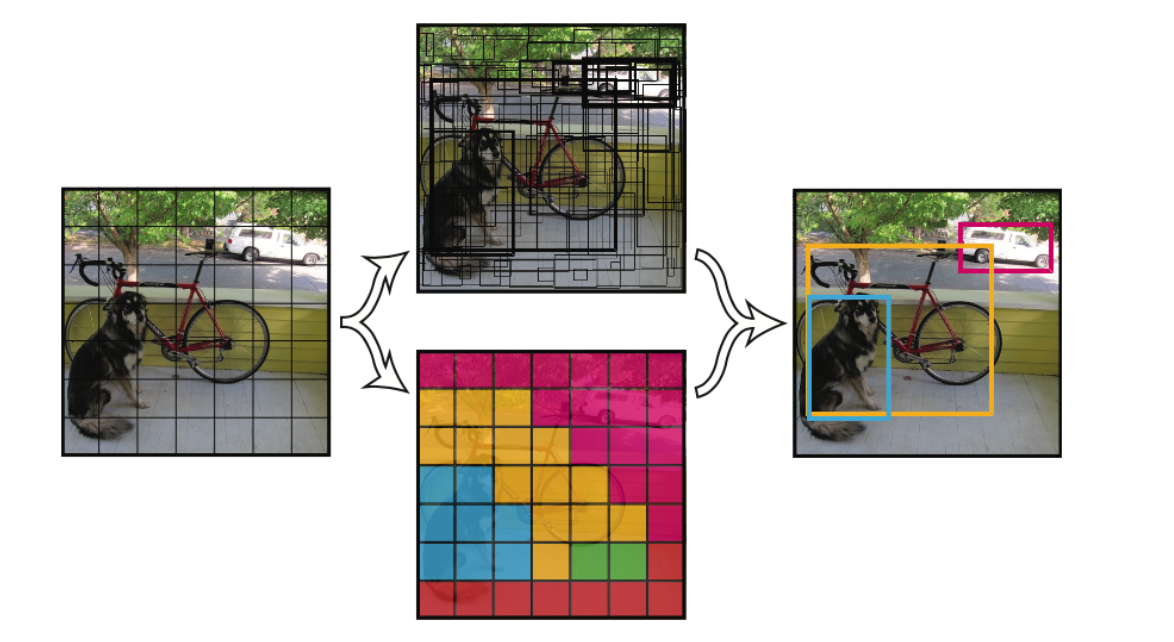
YOLO的核心思想就是利用整张图作为网络的输入,直接在输出层回归bounding box的位置和bounding box所属的类别。 faster RCNN中也直接用整张图作为输入,但是fasterRCNN整体还是采用了RCNN那种 proposal+classifier的思想,只不过是将提取proposal的步骤放在CNN中实现了,而YOLO则采用直接回归的思路。 YOLO v1 将一幅图像分成SxS个网格(grid cell),如果某个object的中心 落在这个网格中,则这个网格就负责预测这个object。 每个网格要预测B个bounding box,每个bounding box除了要回归自身的位置之外,还要附带预测一个confidence值。 这个confidence代表了所预测的b...
Python
2026-01-11

1. 列表和元组总结 列表和元组都是一个可以放置任意数据类型的有序集合,他们有以下共同点 列表和元组中的元素可以任意,并且都可以嵌套。 列表和元组都支持索引,且都支持负数索引,1表示最后一个元素,2表示倒数第二个元素 列表和元组都支持切片操作 都支持in关键词 都可以使用.index()、.count()、sorted()和enumerate()等方法 两者之间的相互转换,list()和tuple() 但是他们也是有区别 列表是动态的,长度大小不固定,可以随意地增加、删减或者改变元素(mutable) 元组是静态的,长度大小不固定,无法增删改,想要对已有的元组做任何“改变”,就只能开辟一块内存,创建新的元组 2. 列表和元组存储方式的差异 由于列表是动态的;元组是静态的,不可变的。这样的差异...
Python
2026-01-11
生成器 什么是生成器? 通过列表生成式,我们可以直接创建一个列表,但是,受到内存限制,列表容量肯定是有限的,而且创建一个包含100万个元素的列表,不仅占用很大的存储空间,如果我们仅仅需要访问前面几个元素,那后面绝大多数元素占用的空间都白白浪费了。 所以,如果列表元素可以按照某种算法推算出来,那我们是否可以在循环的过程中不断推算出后续的元素呢?这样就不必创建完整的list,从而节省大量的空间,在Python中,这种一边循环一边计算的机制,称为生成器:generator 生成器是一个特殊的程序,可以被用作控制循环的迭代行为,python中生成器是迭代器的一种,使用yield返回值函数,每次调用yield会暂停,而可以使用next()函数和send()函数恢复生成器。 生成器类似于返回值为数组的一...
Python
2026-01-11
概念 可变对象与不可变对象的区别在于对象本身是否可变。 python内置的一些类型中 可变对象:list dict set 不可变对象:tuple string int float bool 举一个例子 [代码] 上面例子很直观地展现了,可变对象是可以直接被改变的,而不可变对象则不可以 地址问题 下面我们来看一下可变对象的内存地址变化 [代码] 我们可以看到,可变对象变化后,地址是没有改变的 如果两个变量同时指向一个地址 1.可变对象 [代码] 我们可以看到,改变a则b也跟着变,因为他们始终指向同一个地址 2.不可变对象 [代码] 我们可以看到,a改变后,它的地址也发生了变化,而b则维持原来的地址,原来地址中的内容也没有发生变化 作为函数参数 1.可变对象 [代码] 我们可以看到,可变对象作...
Python
2026-01-11
概述 python采用的是引用计数机制为主,标记清除和分代收集两种机制为辅的策略。 引用计数 Python语言默认采用的垃圾收集机制是『引用计数法 Reference Counting』,该算法最早George E. Collins在1960的时候首次提出,50年后的今天,该算法依然被很多编程语言使用。 『引用计数法』的原理是:每个对象维护一个ob_ref字段,用来记录该对象当前被引用的次数,每当新的引用指向该对象时,它的引用计数ob_ref加1,每当该对象的引用失效时计数ob_ref减1,一旦对象的引用计数为0,该对象立即被回收,对象占用的内存空间将被释放。 它的缺点是需要额外的空间维护引用计数,这个问题是其次的,不过最主要的问题是它不能解决对象的“循环引用”,因此,也有很多语言比如Jav...

Pycharm 的图形化界面虽然好用,但是在某些场景中,是无法使用的。而 Python 本身已经给我们提供了一个调试神器 pdb. 准备文件 在调试之前先将这两个文件准备好(做为演示用),并放在同级目录中。 utils.py [代码] pdb_demo.py [代码] 进入调试模式 主要有两种方法 做为脚本调用,方法很简单,就像正常执行python脚本一样,只是多加了m pdb [代码] 使用这个方式进入调试模式,会在脚本的第一行开始单步调试。 对于单文件的脚本并没有什么问题,如果是一个大型的项目,项目里有很多的文件,使用这种方式只能大大降低我们的效率。 一般情况下,都会直接在你需要的地方打一个断点,那如何打呢? 只需在你想要打断点的地方加上这两行。 [代码] 然后执行时,也不需要再指定m ...
Python
2026-01-11
通过继承创建的新类称为“子类”或“派生类”,被继承的类称为“基类”、“父类”或“超类”,继承的过程,就是从一般到特殊的过程。在某些 OOP 语言中,一个子类可以继承多个基类。但是一般情况下,一个子类只能有一个基类,要实现多重继承,可以通过多级继承来实现 python2中经典类和新式类的继承方式不同,经典类采用深度优先搜索的继承,新式类采用的是广度优先搜索的继承方式 python3中经典类和新式类的继承方式都采用的是都采用广度优先搜索的继承方式 [代码] [代码] 举个例子来说明:现有4个类,A,B,C,D类,D类继承于B类和C类,B类与C类继承于A类。class D(B,C) 实例化D类 深度优先 现在构造函数的继承情况为: 若D类有构造函数,则重写所有父类的继承 若D类没有构造函数,B类有...
Python
2026-01-11
Python程序中存储的所有数据都是对象,每一个对象有一个身份,一个类型和一个值。 看变量的实际作用,执行a = 8 这行代码时,就会创建一个值为8的int对象。 变量名是对这个"一个值为8的int对象"的引用。(也可以简称a绑定到8这个对象) 1、可以通过id()来取得对象的身份 这个内置函数,它的参数是a这个变量名,这个函数返回的值 是这个变量a引用的那个"一个值为8的int对象"的内存地址。 [代码] 2、可以通过type()来取得a引用对象的数据类型 [代码] 3、对象的值 当变量出现在表达式中,它会被它引用的对象的值替代。 总结:类型是属于对象,而不是变量。变量只是对对象的一个引用。 对象有可变对象和不可变对象之分。 Python函数传递参数到底是传值还是引用? 传值、引用这个是c...