
11. 盛最多水的容器 题目 给定一个长度为 n 的整数数组 height 。有 n 条垂线,第 i 条线的两个端点是 (i, 0) 和 (i, height[i]) 。 找出其中的两条线,使得它们与 x 轴共同构成的容器可以容纳最多的水。 返回容器可以储存的最大水量。 说明: 你不能倾斜容器。 示例 1: 输入:[1,8,6,2,5,4,8,3,7]
输出:49
解释:图中垂直线代表输入数组 [1,8,6,2,5,4,8,3,7]。在此情况下,容器能够容纳水(表示为蓝色部分)的最大值为 49。 示例 2: 输入:height = [1,1]
输出:1 提示: n == height.length 2 <= n <= 10 5 0 <= height[i] <= 10 4 题解 在初始时,左右指针分别指向数组的左右两端,它们可以容纳的水量为 \(min(1,7)∗8=8\) 。 此时我们需要移动一个指针。移动哪一个呢?直觉告诉我们,应该移动对应数字较小的那个指针(即此时的左指针)。这是因为,由于容纳的水量是由 两个指针指向的数字中较小值∗指针之间的距离...
Large Model
2026-01-23

总览 由于是“图文多模态”,还是要从“图”和“文”的表征方法讲起,然后讲清楚图文表征的融合方法。这里只讲两件事情: 视觉表征 :分为两个部分问题,一是如何合理建模视觉输入特征,二是如何通过预训练手段进行充分学习表征,这两点是基于视觉完成具体算法任务的基础; 视觉与自然语言的对齐(Visul Language Alignment)或融合 :目的是将视觉和自然语言建模到同一表征空间并进行融合,实现自然语言和视觉语义的互通,这点同样离不开预训练这一过程。模态对齐是处理多模态问题的基础,也是现在流行的多模态大模型技术前提。 对于视觉表征,从发展上可以分为卷积神经网络(CNN)和Vision Transformer(VIT)两大脉络,二者分别都有各自的表征、预训练以及多模态对齐的发展过程。而对于VIT线,另有多模态大模型如火如荼的发展,可谓日新月异。 CNN:视觉理解的一代先驱 点击展开 卷积视觉表征模型和预训练...
Deep Learning
2026-01-22

文章从连续情形出发开始介绍重参数,主要的例子是正态分布的重参数;然后引入离散分布的重参数,这就涉及到了Gumbel Softmax,包括Gumbel Softmax的一些证明和讨论;最后再讲讲重参数背后的一些故事,这主要跟梯度估计有关。 基本概念 重参数(Reparameterization) 实际上是处理如下期望形式的目标函数的一种技巧: \[L_{\theta}=\mathbb{E}_{z\sim p_{\theta}(z)}[f(z)]\tag{1}\] 这样的目标在VAE中会出现,在文本GAN也会出现,在强化学习中也会出现( \(f(z)\) 对应于奖励函数),所以深究下去,我们会经常碰到这样的目标函数。取决于 \(z\) 的连续性,它对应不同的形式: \[\int p_{\theta}(z) f(z)dz\,\,\,\text{(连续情形)}\qquad\qquad \sum_{z} p_{\theta}(z) f(z)\,\,\,\text{(离散情形)}\tag{2}\] 当然,离散情况下我们更喜欢将记号 \(z\) 换成 \(y\) 或者 \(c\) 。 为了最小化...
Computer Vision
2026-01-21
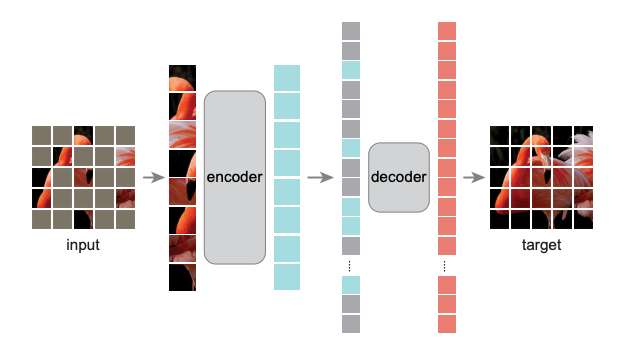
导言 自监督学习(Self-Supervised Learning)能利用大量无标注的数据进行表征学习,然后在特定下游任务上对参数进行微调。通过这样的方式,能够在较少有标注数据上取得优于有监督学习方法的精度。近年来,自监督学习受到了越来越多的关注,如Yann Lecun也在 AAAI 上讲 Self-Supervised Learning 是未来的大势所趋。在CV领域涌现了如SwAV、MOCO、DINO、MoBY等一系列工作。MAE是kaiming继MOCO之后在自监督学习领域的又一力作。首先,本文会对MAE进行解读,然后基于EasyCV库的精度复现过程及其中遇到的一些问题作出解答。 概述 MAE的做法很简单:随机mask掉图片中的一些patch,然后通过模型去重建这些丢失的区域。包括两个核心的设计:1.非对称编码-解码结构 2.用较高的掩码率(75%)。通过这两个设计MAE在预训练过程中可以取得3倍以上的训练速度和更高的精度,如ViT-Huge能够通过ImageNet-1K数据上取得87.8%的准确率。 模型拆解...
Computer Vision
2026-01-21
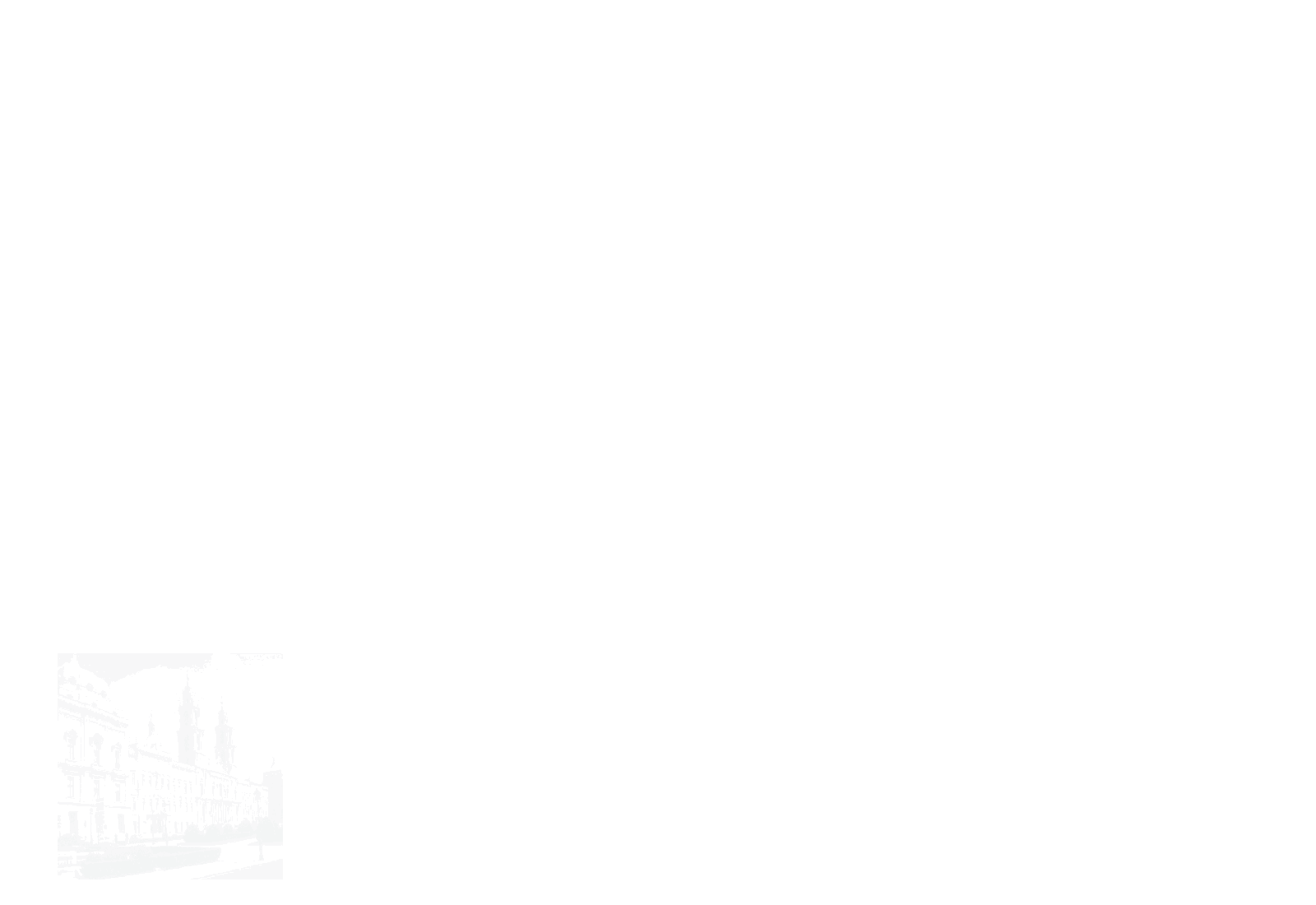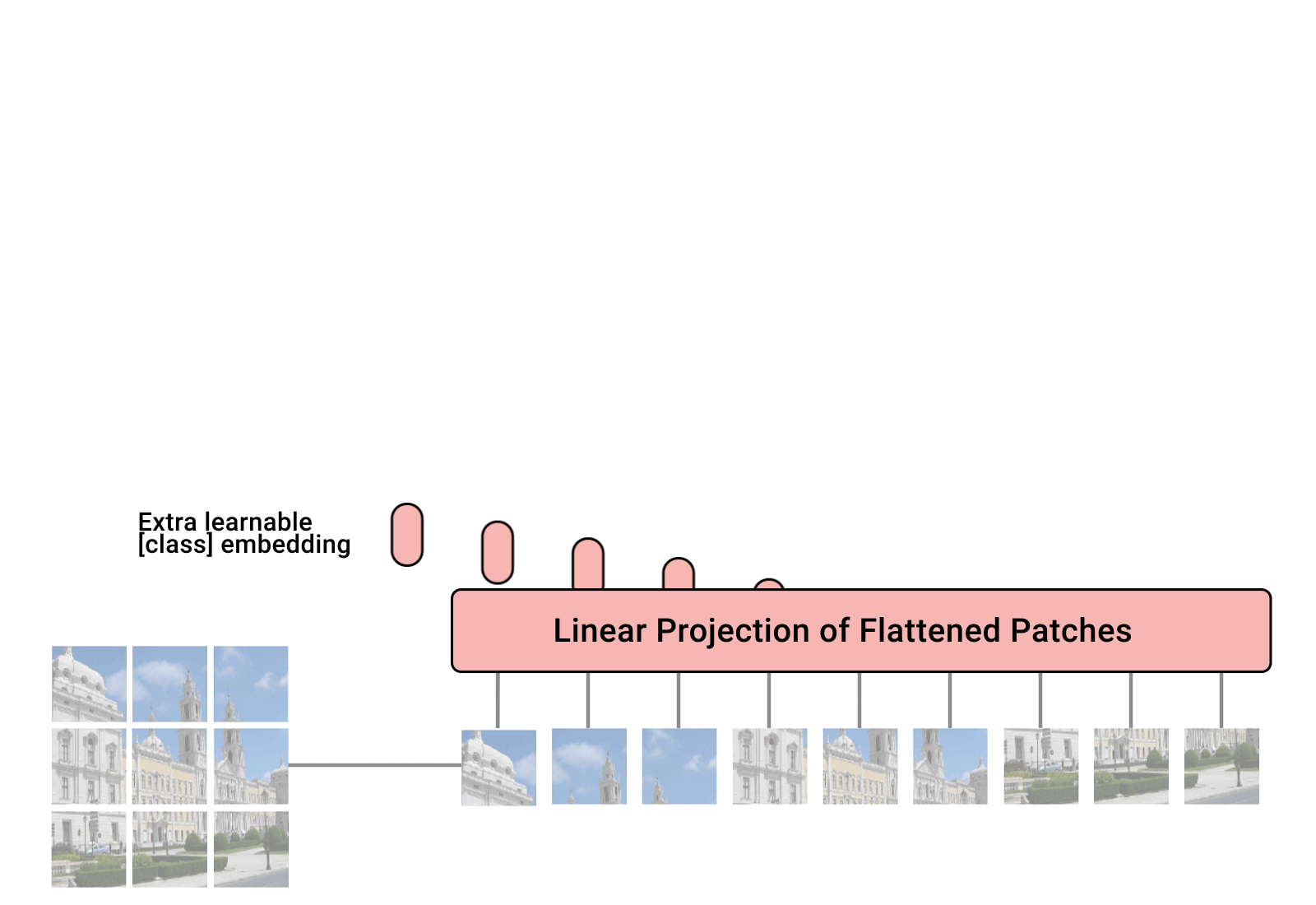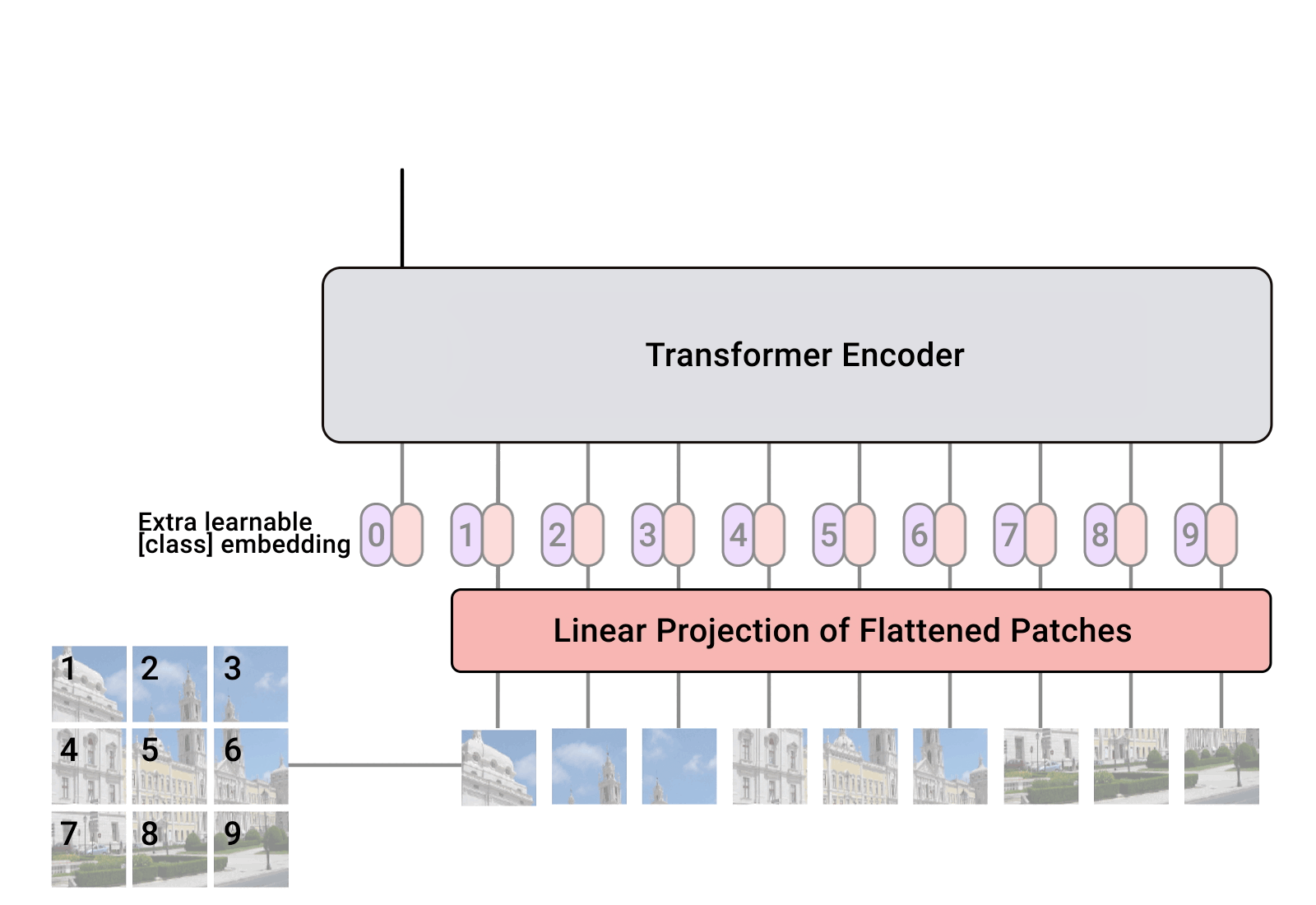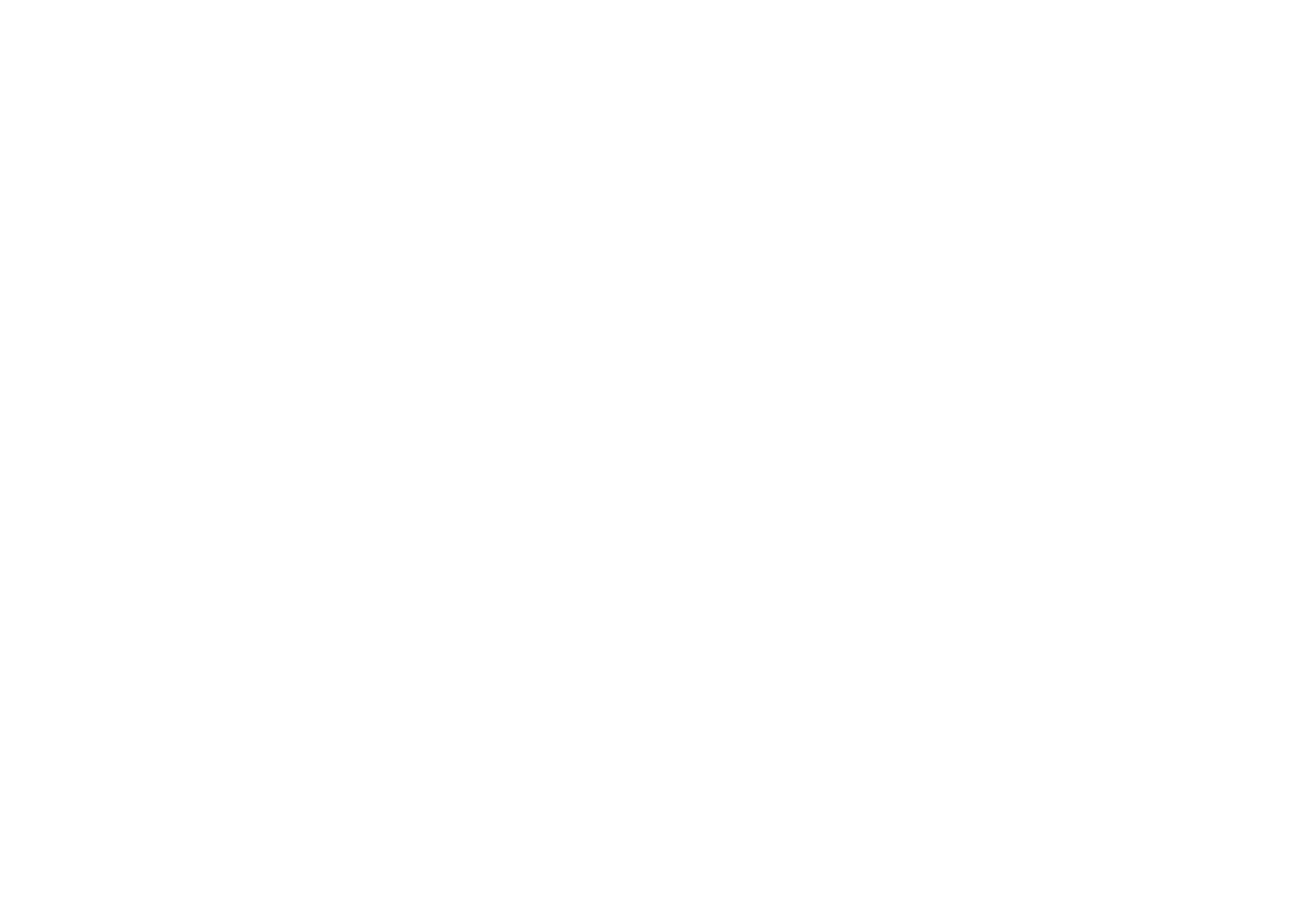
概述 在计算机视觉领域(CV),对视觉特征的理解CNN是长期处于主导地位的。而在NLP领域,Transformer框架的巨大成功,也激发了不少研究者探索将Transformer用于计算机视觉任务。ViT(Vision Transformer)的出现标志着在CV领域Transformer架构迈出了重要的一步。尤其在当前结合LLM的多模态探索上(MM-LLM),都是以LLM大语言模型为骨干架构的模型,多种模态的信息需要先做token化处理,再输入到LLM模型。ViT天然具有序列化特征的建模能力,自然在MM-LLM探索中大放异彩~ ViT在多模态模型中的角色类似于自然语言建模中的Tokenizer组件,对图像进行视觉特征编码,产出图像的序列特征。只不过ViT的编码过程本身也是采用了Transformer的模型结构。 本文主要结合几篇paper和源码讲讲ViT和针对ViT的一些优化方法~ ViT(Vision Transformer)...
Computer Vision
2026-01-21
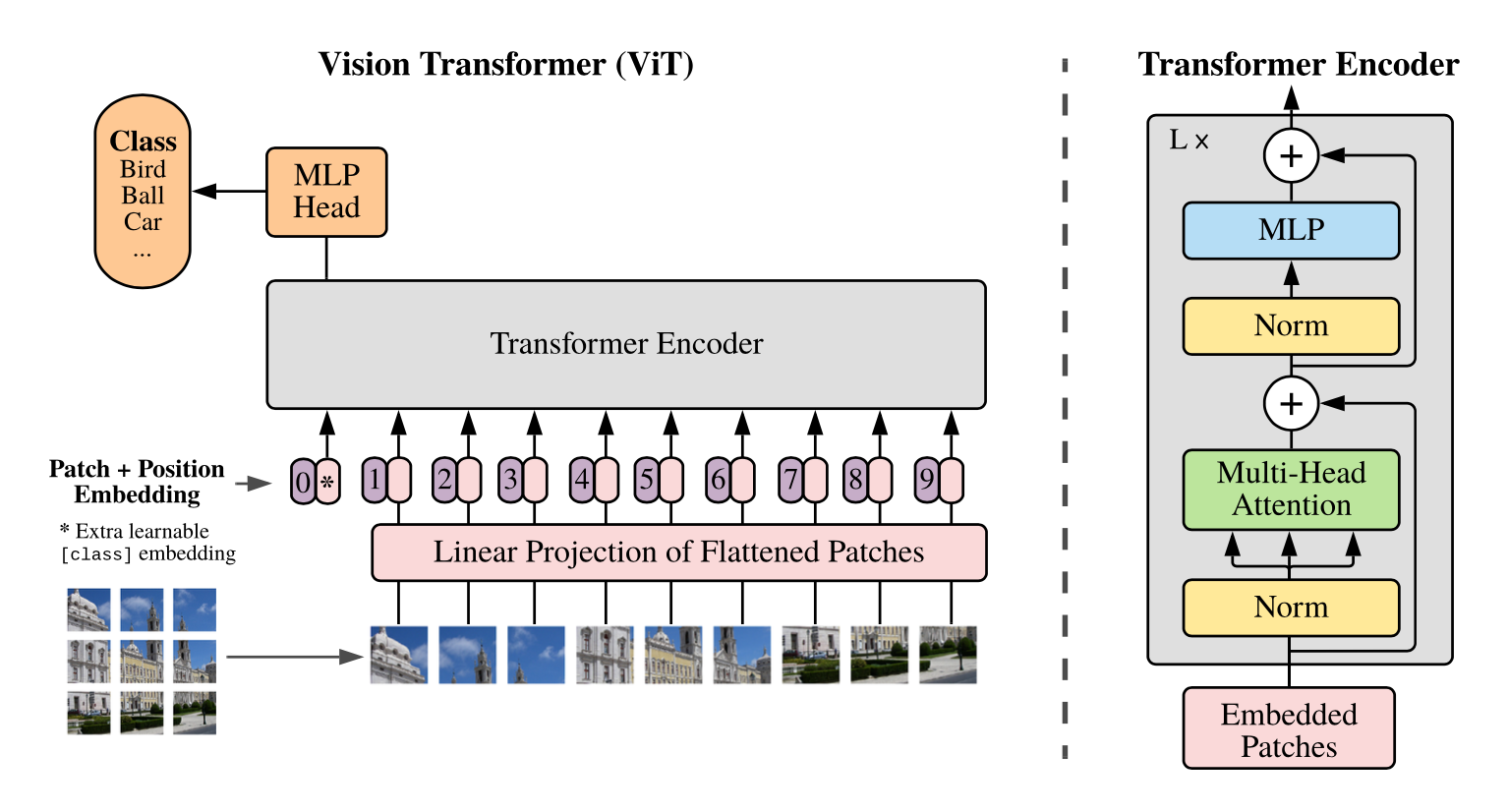
ViT(vision transformer)是Google在2020年提出的直接将transformer应用在图像分类的模型,后面很多的工作都是基于ViT进行改进的。ViT的思路很简单:直接把图像分成固定大小的patchs,然后通过线性变换得到patch embedding,这就类比NLP的words和word embedding,由于transformer的输入就是a sequence of token embeddings,所以将图像的patch embeddings送入transformer后就能够进行特征提取从而分类了。ViT模型原理如下图所示,其实ViT模型只是用了transformer的Encoder来提取特征(原始的transformer还有decoder部分,用于实现sequence to sequence,比如机器翻译)。下面将分别对各个部分做详细的介绍。 Patch Embedding 对于ViT来说,首先要将原始的2-D图像转换成一系列1-D的patch embeddings,这就好似NLP中的word embedding。输入的2-D图像记为 \(x\in...
Generative Model
2026-01-18

简介 如果以概率的视角看待世界的生成模型。 在这样的世界观中,我们可以将任何类型的观察数据(例如 \(D\) )视为来自底层分布(例如 \( p_{data}\) )的有限样本集。 任何生成模型的目标都是在访问数据集 \(D\) 的情况下近似该数据分布。 如果我们能够学习到一个好的生成模型,我们可以将学习到的模型用于下游推理。 我们主要对数据分布的参数近似感兴趣,在一组有限的参数中,它总结了关于数据集 \(D\) 的所有信息。 与非参数模型相比,参数模型在处理大型数据集时能够更有效地扩展,但受限于可以表示的分布族。 在参数的设置中,我们可以将学习生成模型的任务视为在模型分布族中挑选参数,以最小化模型分布和数据分布之间的距离。 如上图,给定一个狗的图像数据集,我们的目标是学习模型族 \(M\) 中生成模型 θ 的参数,使得模型分布 \(p_θ\) 接近 \(p_{data}\) 上的数据分布。 在数学上,我们可以将我们的目标指定为以下优化问题: \[\mathop{min}\limits_{\theta\in M}d(p_\theta,p_{data})\] 其中, \(d()\)...
Generative Model
2026-01-18

研究对象与基本设定 我们希望学习一个能够“生成数据”的概率模型。假设我们有一个数据集 \(D\) ,每个样本是 \(n\) 维二值向量: \(x \in \{0,1\}^n\) 我们的目标是用一个参数化分布 \(p_\theta(x)\) 去逼近真实数据分布 \(p_{\text{data}}(x)\) ,并最终能够: 密度估计 :给定 \(x\) 计算 \(p_\theta(x)\) 或 \(\log p_\theta(x)\) 采样生成 :从 \(p_\theta(x)\) 采样得到新的 \(x\) 表示:链式法则与自回归分解 链式法则分解联合分布 任意联合分布都可用概率链式法则分解为条件概率的乘积: \[p(x) = \prod_{i=1}^{n} p(x_i \mid x_1, x_2, \dots, x_{i-1}) = \prod_{i=1}^{n} p(x_i \mid x_{<i})\] 其中: \(x_{<i} = [x_1, x_2, \dots, x_{i-1}]\) ,这意味着:只要我们能为每个维度 \(i\) 学好一个条件分布 \(p(x_i \mid...
Self-Supervised
2026-01-18

the machine predicts any parts of its input for any observed part 这是LeCun在AAAI 2020上对自监督学习的定义,再结合传统的自监督学习定义,可以总结如下两点特征: 通过“半自动”过程从数据本身获取“标签”; 从“其他部分”预测部分数据。 个人理解, 其实任意挖掘对象之间联系、探索不同对象共同本质的方法,都或多或少算是自监督学习的思想 。 自监督学习与无监督学习的区别主要在于,无监督学习专注于检测特定的数据模式,如聚类、社区发现或异常检测,而自监督学习的目标是恢复(recovering),仍处于监督学习的范式中。上图展示了三者之间的区别, 自监督中的“related information” 可以来自其他模态、输入的其他部分以及输入的不同形式。 Self-Supervised...
Computer Vision
2026-01-11
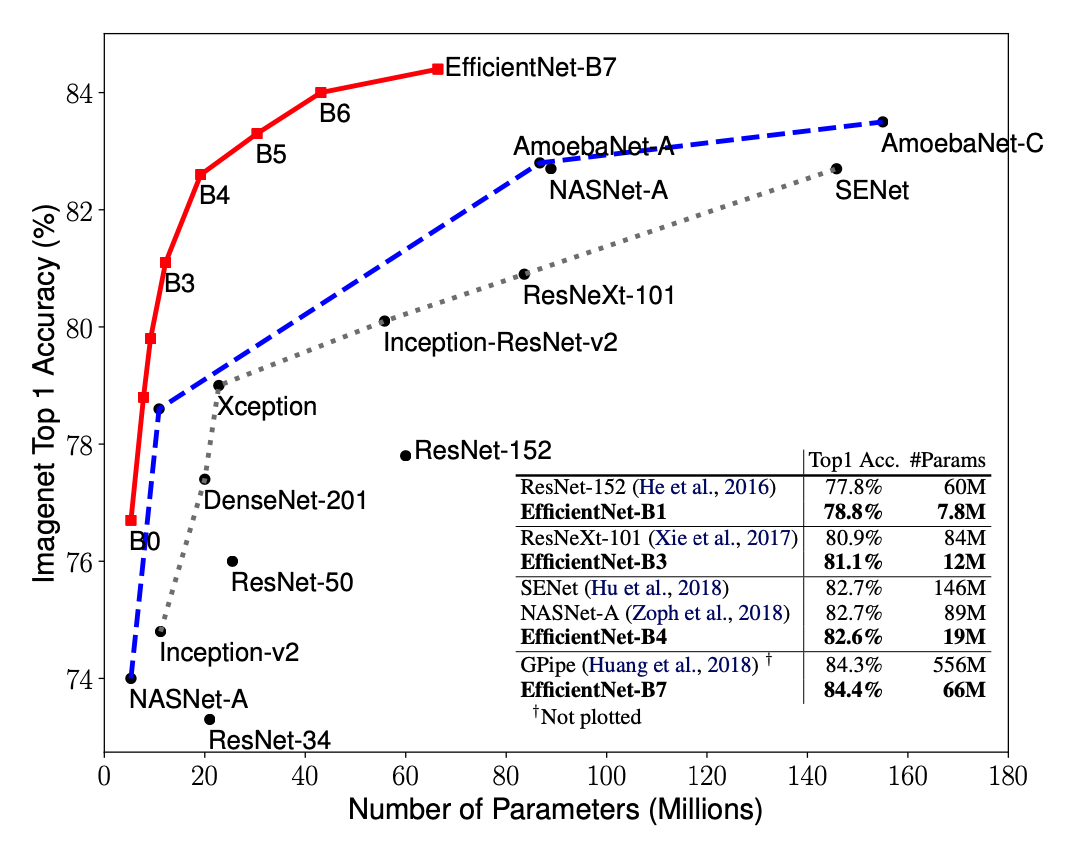
简介 EfficientNet源自Google Brain的论文EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. 从标题也可以看出,这篇论文最主要的创新点是Model Scaling. 论文提出了compound scaling,混合缩放,把网络缩放的三种方式:深度、宽度、分辨率,组合起来按照一定规则缩放,从而提高网络的效果。EfficientNet在网络变大时效果提升明显,把精度上限进一步提升,成为了当前最强网络。EfficientNetB7在ImageNet上获得了最先进的 84.4%的top1精度 和 97.1%的top5精度,比之前最好的卷积网络(GPipe, Top1: 84.3%, ...
Deep Learning
2026-01-11
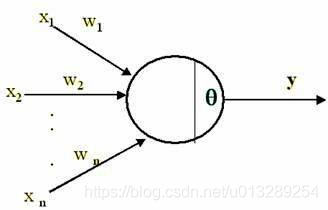
1.深度学习偏置的作用? 我们在学深度学习的时候,最早接触到的神经网络应该属于感知器(感知器本身就是一个很简单的神经网络,也许有人认为它不属于神经网络,当然认为它和神经网络长得像也行) 要想激活这个感知器,使得 y=1 ,就必须使 x_1w_1 + x_2w_2 +....+x_nw_n T ( T 为一个阈值),而 T 越大,想激活这个感知器的难度越大,人工选择一个阈值并不是一个好的方法,因为样本那么多,我不可能手动选择一个阈值,使得模型整体表现最佳,那么我们可以使得T变成可学习的,这样一来, T 会自动学习到一个数,使得模型的整体表现最佳。当把T移动到左边,它就成了偏置, x_1w_1 + x_2w_2 +....+x_nw_n T 0 xw +b 0 ,总之,偏置的大小控制着激活这个感...
Deep Learning
2026-01-11
一般来说,神经网络处理的东西都是连续的浮点数,标准的输出也是连续型的数字。但实际问题中,我们很多时候都需要一个离散的结果,比如分类问题中我们希望输出正确的类别,“类别”是离散的,“类别的概率”才是连续的;又比如我们很多任务的评测指标实际上都是离散的,比如分类问题的正确率和F1、机器翻译中的BLEU,等等。 还是以分类问题为例,常见的评测指标是正确率,而常见的损失函数是交叉熵。交叉熵的降低与正确率的提升确实会有一定的关联,但它们不是绝对的单调相关关系。换句话说,交叉熵下降了,正确率不一定上升。显然,如果能用正确率的相反数做损失函数,那是最理想的,但正确率是不可导的(涉及到 [Math] 等操作),所以没法直接用。 这时候一般有两种解决方案;一是动用强化学习,将正确率设为奖励函数,这是“用牛刀杀...