76. 最小覆盖子串 题目 给定两个字符串 s 和 t ,长度分别是 m 和 n ,返回 s 中的 最短窗口 子串 ,使得该子串包含 t 中的每一个字符( 包括重复字符 )。如果没有这样的子串,返回空字符串 "" 。 测试用例保证答案唯一。 示例 1: 输入:s = "ADOBECODEBANC", t = "ABC"
输出:"BANC"
解释:最小覆盖子串 "BANC" 包含来自字符串 t 的 'A'、'B' 和 'C'。 示例 2: 输入:s = "a", t = "a"
输出:"a"
解释:整个字符串 s 是最小覆盖子串。 示例 3: 输入: s = "a", t = "aa"
输出: ""
解释: t 中两个字符 'a' 均应包含在 s 的子串中,
因此没有符合条件的子字符串,返回空字符串。 提示: m == s.length n == t.length 1 <= m, n <= 10 5 s 和 t 由英文字母组成 题解 这是一个经典的 滑动窗口 (Sliding Window) 问题 我们需要维护一个动态的窗口 [left, right] : 右移扩大 :不断移动...
129. 滑动窗口最大值 题目 给你一个整数数组 nums ,有一个大小为 k 的滑动窗口从数组的最左侧移动到数组的最右侧。你只可以看到在滑动窗口内的 k 个数字。滑动窗口每次只向右移动一位。 返回 滑动窗口中的最大值 。 示例 1: 输入:nums = [1,3,-1,-3,5,3,6,7], k = 3
输出:[3,3,5,5,6,7]
解释:
滑动窗口的位置 最大值
--------------- -----
[1 3 -1] -3 5 3 6 7 3
1 [3 -1 -3] 5 3 6 7 3
1 3 [-1 -3 5] 3 6 7 5
1 3 -1 [-3 5 3] 6 7 5
1 3 -1 -3 [5 3 6] 7 6
1 3 -1 -3 5 [3 6 7] 7 示例 2: 输入:nums = [1], k = 1
输出:[1] 提示: 1 <= nums.length...
Generative Model
2026-01-19
基于文章 《Elucidating the Design Space of Diffusion-Based Generative Models》 来统一扩散模型框架 通用扩散模型框架推导 加噪公式 Flow Matching的一步加噪公式 \[\mathbf{x}_t=(1-t)\mathbf{x}_0+t\varepsilon\] 写成概率分布形式: \[p(\mathbf{x}_t|\mathbf{x}_0)=\mathcal{N}(\mathbf{x}_t;(1-t)\mathbf{x}_0,t^2\mathbf{I})\] Score Matching的一步加噪公式 \[\mathbf{x}_t=\mathbf{x}_0+\sigma_t\varepsilon \] 写成概率分布形式: \[p(\mathbf{x}_t|\mathbf{x}_0)=\mathcal{N}(\mathbf{x}_t;\mathbf{x}_0,\sigma_t^2\mathbf{I})\] DDPM/DDIM的一步加噪公式...
Computer Vision
2026-01-11
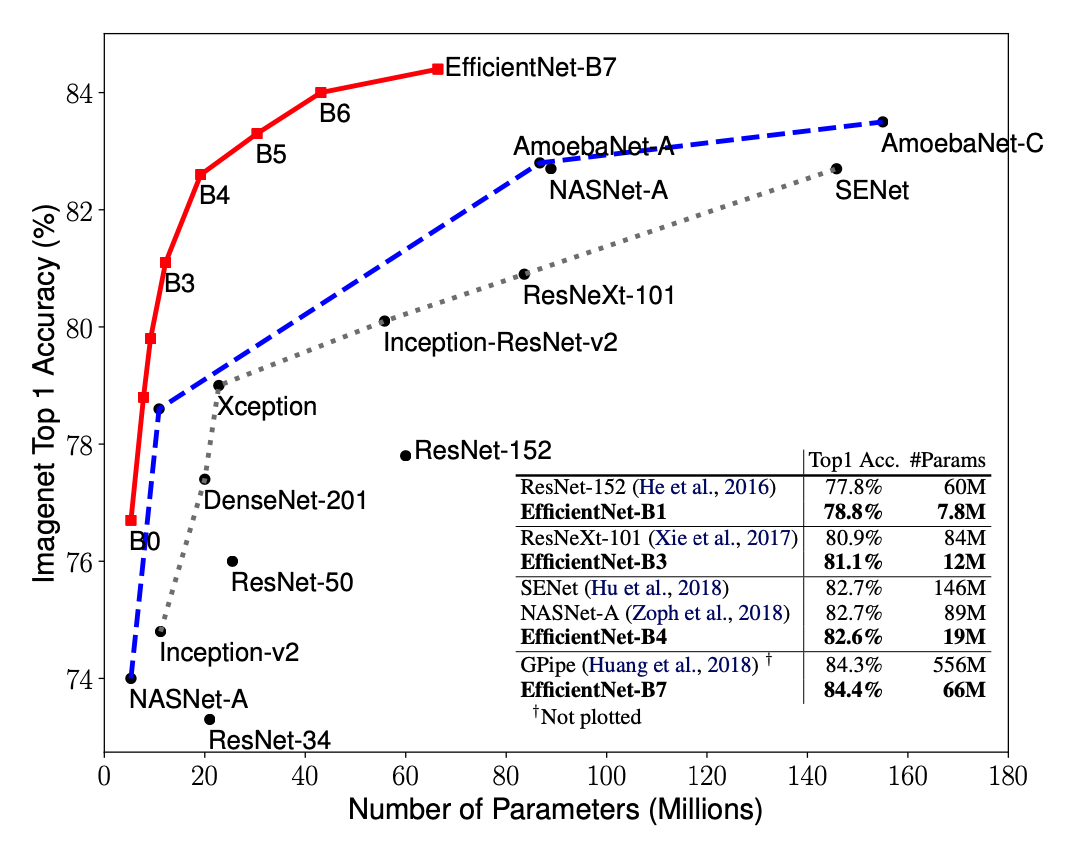
简介 EfficientNet源自Google Brain的论文EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. 从标题也可以看出,这篇论文最主要的创新点是Model Scaling. 论文提出了compound scaling,混合缩放,把网络缩放的三种方式:深度、宽度、分辨率,组合起来按照一定规则缩放,从而提高网络的效果。EfficientNet在网络变大时效果提升明显,把精度上限进一步提升,成为了当前最强网络。EfficientNetB7在ImageNet上获得了最先进的 84.4%的top1精度 和 97.1%的top5精度,比之前最好的卷积网络(GPipe, Top1: 84.3%, ...
Generative Model
2026-01-11

Diffusion Models from SDE 连续扩散模型 (Continuous Diffusion Models) 将传统的离散时间扩散过程扩展到连续时间域,可以被视为一个随机过程,使用随机微分方程(SDE)来描述。其前向过程可以写成如下形式: [公式] 其中, f(x,t) 可以看成偏移系数, g(t) 可以看成是扩散系数, dw 是标准布朗运动。这个SDE 描述了数据在连续时间域内如何被噪声逐渐破坏。 这个随机过程的逆向过程存在(更准确的描述:下面的逆向时间SDE具有与正向过程SDE相同的联合分布)为 [公式] 前面我们得到了扩散过程的逆向过程可以用一个SDE描述(逆向随机过程),事实上,存在一个确定性过程 (用ODE描述)也是它的逆向过程 (更准确的描述:这个ODE过程的在任...
Generative Model
2026-01-11

💡 Score based generative model SMLD的关键点: 正式开始介绍之前首先解答一下这个问题:scorebased 模型是什么东西,微分方程在这个模型里到底有什么用?我们知道生成模型基本都是从某个现有的分布中进行采样得到生成的样本,为此模型需要完成对分布的建模。根据建模方式的不同可以分为隐式建模(例如 GAN、diffusion models)和显式建模(例如 VAE、normalizing flows)。和上述的模型相同,scorebased 模型也是用一定方式对分布进行了建模。具体而言,这类模型建模的对象是概率分布函数 log 的梯度,也就是 score function,而为了对这个建模对象进行学习,需要使用一种叫做 score matching 的技术,这也...
Computer Vision
2026-01-11

💡 轻量级网络系列 Introduction Inception 在最初的版本 Inception/GoogleNet,其核心思想是利用多尺寸卷积核去观察输入数据。举个栗子,我们看某个景象由于远近不同,同一个物体的大小也会有所不同,那么不同尺度的卷积核观察的特征就会有这样的效果。于是就有了如下的网络结构图: 于是我们的网络就变胖了,通过增加网络的宽度,提高了对于不同尺度的适应程度。但这样的话,计算量有点大了。 Pointwise Conv 为了减少在上面结构的参数量并降低计算量,于是在 Inception V1 的基础版本上加上了 1x1 卷积核,这就形成了 Inception V1 的最终网络结构,如下图。 这个 1x1 卷积就是 Pointwise Convolution,简称 PW。利...
Computer Vision
2026-01-11

网络整体介绍 ThunderNet的整体架构如下图所示。 ThunderNet使用320×320像素作为网络的输入分辨率。整体的网络结构分为两部分:Backbone部分和Detection部分。网络的骨干部分为SNet,SNet是基于ShuffleNetV2进行修改得到的。 网络的检测部分,利用了压缩的RPN网络,修改自LightHead RCNN网络用以提高效率。 并提出Context Enhancement Module整合局部和全局特征增强网络特征表达能力。 并提出Spatial Attention Module空间注意模块,引入来自RPN的前后景信息用以优化特征分布。 backbone 部分 1.输入分辨率 为了加快推理(前向操作)速度,作者使用320320大小的输入图像。需要注意的...