
11. 盛最多水的容器 题目 给定一个长度为 n 的整数数组 height 。有 n 条垂线,第 i 条线的两个端点是 (i, 0) 和 (i, height[i]) 。 找出其中的两条线,使得它们与 x 轴共同构成的容器可以容纳最多的水。 返回容器可以储存的最大水量。 说明: 你不能倾斜容器。 示例 1: 输入:[1,8,6,2,5,4,8,3,7]
输出:49
解释:图中垂直线代表输入数组 [1,8,6,2,5,4,8,3,7]。在此情况下,容器能够容纳水(表示为蓝色部分)的最大值为 49。 示例 2: 输入:height = [1,1]
输出:1 提示: n == height.length 2 <= n <= 10 5 0 <= height[i] <= 10 4 题解 在初始时,左右指针分别指向数组的左右两端,它们可以容纳的水量为 \(min(1,7)∗8=8\) 。 此时我们需要移动一个指针。移动哪一个呢?直觉告诉我们,应该移动对应数字较小的那个指针(即此时的左指针)。这是因为,由于容纳的水量是由 两个指针指向的数字中较小值∗指针之间的距离...
Self-Supervised
2026-01-23

如果把 近几年对比学习在视觉领域有代表性的工作做一下总结,那么对比学习的发展历程大概可以分为四个阶段: 百花齐放 这个阶段代表性工作有InstDisc(instance discrimination,)、CPC、CMC等。在这个阶段中,方法、模型、目标函数、代理任务都还没有统一,所以说是一个百花齐放的时代 CV双雄 代表作有MoCo v1、SimCLR v1、MoCo v2、SimCLR v2;CPC、CMC的延伸工作、SwAV等。这个阶段发展非常迅速,有的工作间隔甚至不到一个月,ImageNet上的成绩基本上每个月都在被刷新。 不用负样本 BYOL及其改进工作、SimSiam(CNN在对比学习中的总结性工作) transformer MoCo v3、DINO。这个阶段,无论是对比学习还是最新的掩码学习,都是用Vision Transformer做的。 第一阶段:百花齐放(2018-2019Mid) InstDisc(instance discrimination) 这篇文章提出了个体判别任务(代理任务)以及 memory bank ,非常经典,后人给它的方法起名为InstDisc。...
Self-Supervised
2026-01-23
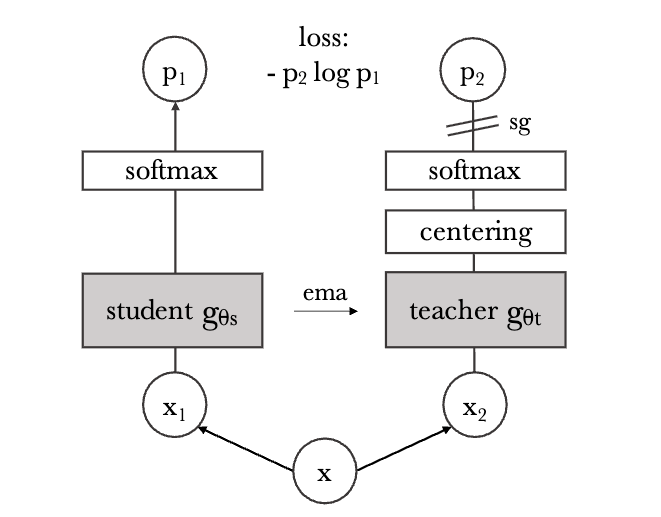
DINO Emerging Properties in Self-Supervised Vision Transformers 论文地址: arxiv.org/pdf/2104.14294 DINO摇摆到了动量式更新,果然【加动量】还是比【只用梯度停止】香。DINO的名字来自于Self- di stillation with no labels中的蒸馏和No标签。 DINO的训练步骤 其实以前的对比学习方案也可以理解为知识蒸馏,DINO里更具体得描述了知识蒸馏的含义。 下图展示了一个样本通过数据增强得到一对views \((x_1,x_2)\) 。注意DINO后面还会使用更复杂的裁剪和对比方案,但这里简单起见先不考虑那些。模型将输入图像的两种不同的随机变换 \(x_1\) 和 \(x_2\) 分别传递给学生和教师网络。 这两个网络具有相同的架构,但参数不同 。教师网络的输出以batch内计算的平均值,进行中心化(减去均值)。每个网络输出一个 \(K\)...
Self-Supervised
2026-01-23
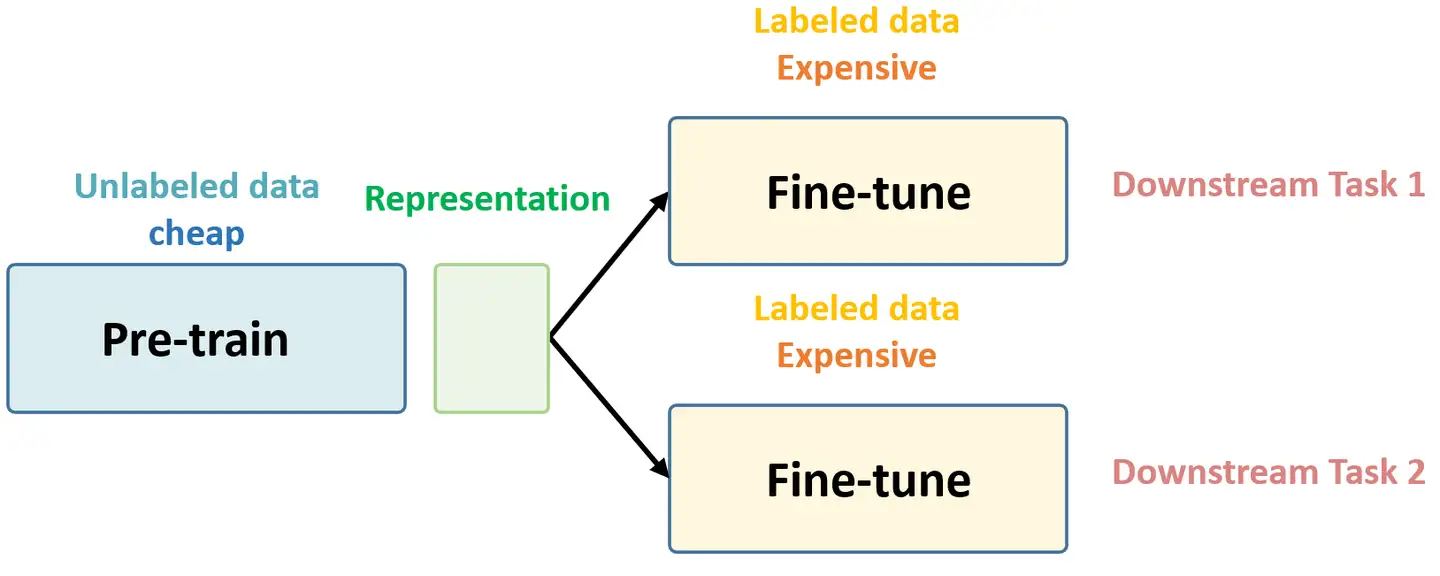
Self-Supervised Learning ,又称为自监督学习,我们知道一般机器学习分为有监督学习,无监督学习和强化学习。 而 Self-Supervised Learning 是无监督学习里面的一种,主要是希望能够学习到一种 通用的特征表达 用于 下游任务 (Downstream Tasks) 。 其主要的方式就是通过自己监督自己。作为代表作的 kaiming 的 MoCo 引发一波热议, Yann Lecun也在 AAAI 上讲 Self-Supervised Learning 是未来的大势所趋。所以在这个系列中,我会系统地解读 Self-Supervised Learning 的经典工作。 总结下 Self-Supervised Learning 的方法,用 4 个英文单词概括一下就是: Unsupervised Pre-train, Supervised Fine-tune. 这段话先放在这里,可能你现在还不一定完全理解,后面还会再次提到它。 在预训练阶段我们使用 无标签的数据集 (unlabeled data) ,因为有标签的数据集 很贵...
Self-Supervised
2026-01-23
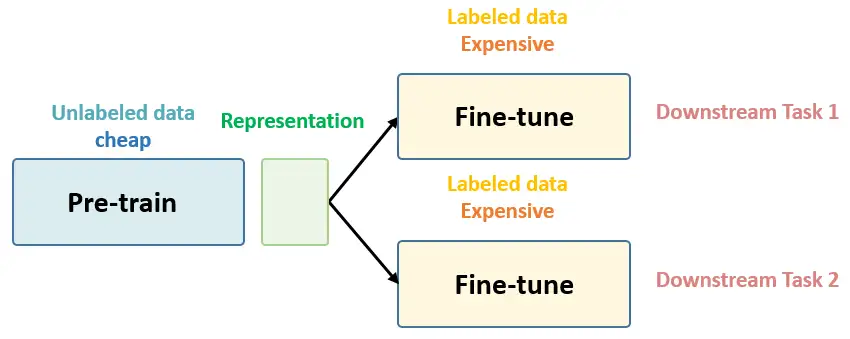
总结下 Self-Supervised Learning 的方法,用 4 个英文单词概括一下就是: Unsupervised Pre-train, Supervised Fine-tune. 在预训练阶段我们使用 无标签的数据集 (unlabeled data) ,因为有标签的数据集 很贵 ,打标签得要多少人工劳力去标注,那成本是相当高的,所以这玩意太贵。相反,无标签的数据集网上随便到处爬,它 便宜 。在训练模型参数的时候,我们不追求把这个参数用带标签数据从 初始化的一张白纸 给一步训练到位,原因就是数据集太贵。于是 Self-Supervised Learning 就想先把参数从 一张白纸 训练到 初步成型 ,再从 初步成型 训练到 完全成型 。注意这是2个阶段。这个 训练到初步成型的东西 ,我们把它叫做 Visual Representation 。预训练模型的时候,就是模型参数从 一张白纸 到 初步成型 的这个过程,还是用无标签数据集。等我把模型参数训练个八九不离十,这时候再根据你 下游任务 (Downstream Tasks) 的不同去用带标签的数据集把参数训练到 完全成型...
补充知识 表示学习 (Representation Learning): 学习数据的表征,以便在构建分类器或其他预测器时更容易提取有用的信息 ,无监督学习也属于表示学习。 互信息 (Mutual Information):表示两个变量 \(X\) 和 \(Y\) 之间的关系,定义为: \[I(X;Y)=\sum_{x\in X}\sum_{y\in Y}p(x,y)log\frac{p(x|y)}{p(x)}\] 对比损失(contrastive loss) :计算成对样本的匹配程度,主要用于降维中。计算公式为: \[L=\frac{1}{2N}\sum_{n-1}^N[yd^2+(1-y)max(margin-d, 0)^2]\] 其中, \(d=\sqrt{(a_n-b_n)^2}\) 为两个样本的欧式距离, \(y=\{0,1\}\) 代表两个样本的匹配程度, \(margin\) 代表设定的阈值。这种损失函数可以很好的表达成对样本的匹配程度,也能够很好用于训练提取特征的模型。当 \( y=1\) (即样本相似)时,损失函数只剩下 \(∑d^2\)...
Self-Supervised
2026-01-23

从 NLP 入手 n-gram 语言模型(language model)就是假设一门语言所有可能的句子服从一个概率分布,每个句子出现的概率加起来是1,那么语言模型的任务就是预测每个句子在语言中出现的概率。如果把句子 \(s\) 看成单词 \(w\) 的序列 \(s=\{w_1,w_2,...,w_m\}\) ,那么语言模型就是建模一个 \(p(w_1,w_2,...,w_m)\) 来计算这个句子 \(s\) 出现的概率,直观上我们要得到这个语言模型,基于链式法则可以表示为每个单词出现的条件概率的乘积,我们将条件概率的条件 \((w_1,w_2,...,w_{i-1})\) 称为单词 \(w_i\) 的上下文,用 \(c_i\) 表示。 \[\begin{aligned} p\left(w_{1}, w_{2}, \ldots, w_{m}\right)&=p\left(w_{1}\right) * p\left(w_{2} \mid w_{1}\right) * p\left(w_{3} \mid w_{1}, w_{2}\right) \ldots p\left(w_{m}...
Computer Vision
2026-01-11
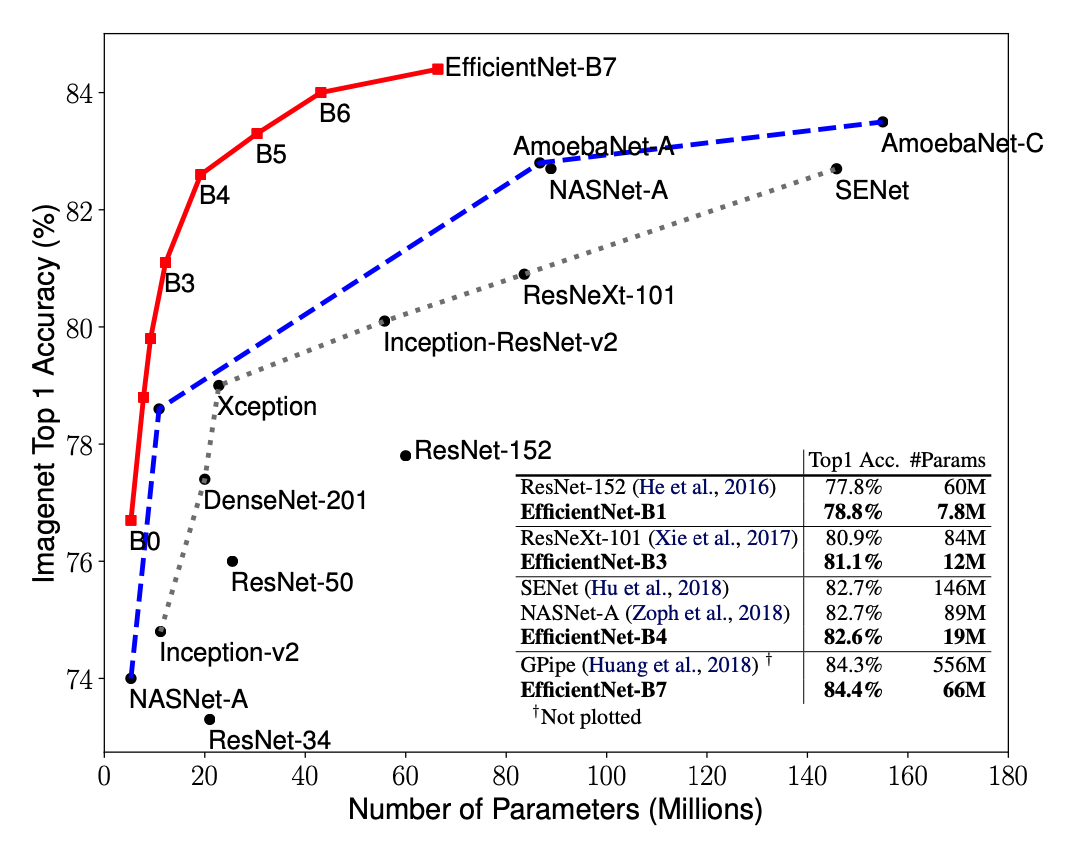
简介 EfficientNet源自Google Brain的论文EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. 从标题也可以看出,这篇论文最主要的创新点是Model Scaling. 论文提出了compound scaling,混合缩放,把网络缩放的三种方式:深度、宽度、分辨率,组合起来按照一定规则缩放,从而提高网络的效果。EfficientNet在网络变大时效果提升明显,把精度上限进一步提升,成为了当前最强网络。EfficientNetB7在ImageNet上获得了最先进的 84.4%的top1精度 和 97.1%的top5精度,比之前最好的卷积网络(GPipe, Top1: 84.3%, ...
Self-Supervised
2026-01-11
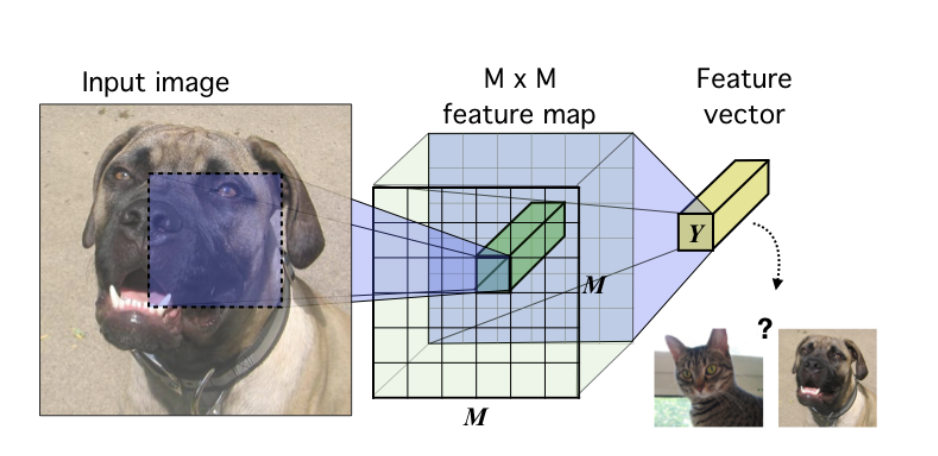
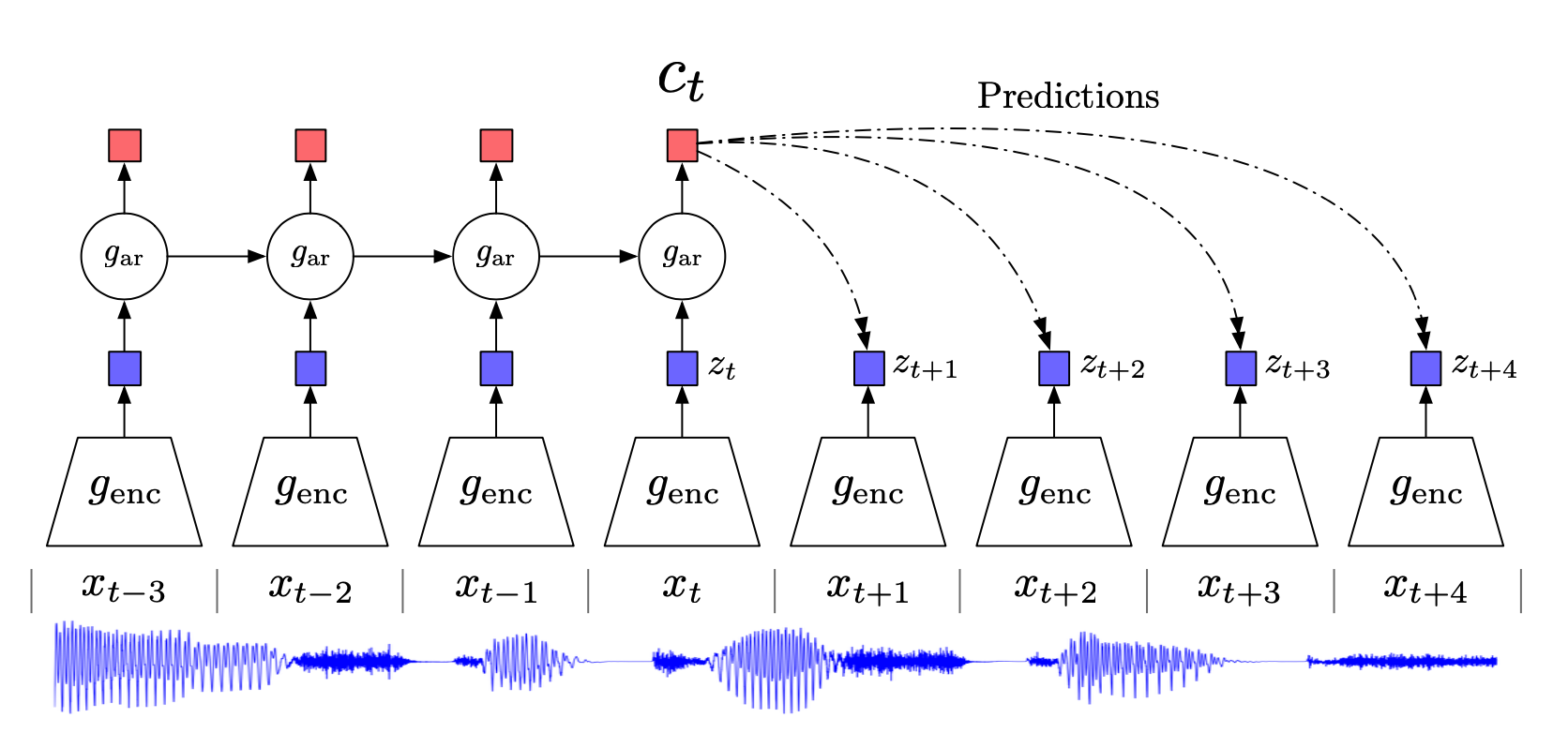
相关内容 自监督学习(Selfsupervised):属于无监督学习,其核心是自动为数据打标签(伪标签或其他角度的可信标签,包括图像的旋转、分块等等),通过让网络按照既定的规则,对数据打出正确的标签来更好地进行特征表示,从而应用于各种下游任务。 互信息(Mutual Information):表示两个变量 X 和 Y 之间的关系,定义为: 噪声对抗估计(Noise Contrastive Estimation, NCE):在NLP任务中一种降低计算复杂度的方法,将语言模型估计问题简化为一个二分类问题。 Introduction 无监督学习一个重要的问题就是学习有用的 representation,本文的目的就是训练一个 representation learning 函数(即编码器encod...

进程 一个在内存中运行的应用程序。每个进程都有自己独立的一块内存空间,一个进程可以有多个线程,比如在Windows系统中,一个运行的xx.exe就是一个进程。 线程 进程中的一个执行任务(控制单元),负责当前进程中程序的执行。一个进程至少有一个线程,一个进程可以运行多个线程,多个线程可共享数据。 与进程不同的是同类的多个线程共享进程的堆和方法区资源,但每个线程有自己的程序计数器、虚拟机栈和本地方法栈,所以系统在产生一个线程,或是在各个线程之间作切换工作时,负担要比进程小得多,也正因为如此,线程也被称为轻量级进程。 Java 程序天生就是多线程程序,我们可以通过 JMX 来看一下一个普通的 Java 程序有哪些线程,代码如下。 [代码] 上述程序输出如下(输出内容可能不同,不用太纠结下面每个线...
杂七杂八
2026-01-11

分布式深度学习里的通信严重依赖于规则的集群通信,诸如 allreduce, reducescatter, allgather 等,因此,实现高度优化的集群通信,以及根据任务特点和通信拓扑选择合适的集群通信算法至关重要。 本文以数据并行经常使用的 allreduce 为例来展示集群通信操作的数学性质。 Allreduce 在干什么? 如图 1 所示,一共 4个设备,每个设备上有一个矩阵(为简单起见,我们特意让每一行就一个元素),allreduce 操作的目的是,让每个设备上的矩阵里的每一个位置的数值都是所有设备上对应位置的数值之和。 如图 2 所示, allreduce 可以通过 reducescatter 和 allgather 这两个更基本的集群通信操作来实现。基于 ring 状通信可以高...
Computer Vision
2026-01-11

💡 轻量级网络系列 Introduction Inception 在最初的版本 Inception/GoogleNet,其核心思想是利用多尺寸卷积核去观察输入数据。举个栗子,我们看某个景象由于远近不同,同一个物体的大小也会有所不同,那么不同尺度的卷积核观察的特征就会有这样的效果。于是就有了如下的网络结构图: 于是我们的网络就变胖了,通过增加网络的宽度,提高了对于不同尺度的适应程度。但这样的话,计算量有点大了。 Pointwise Conv 为了减少在上面结构的参数量并降低计算量,于是在 Inception V1 的基础版本上加上了 1x1 卷积核,这就形成了 Inception V1 的最终网络结构,如下图。 这个 1x1 卷积就是 Pointwise Convolution,简称 PW。利...