
进程 一个在内存中运行的应用程序。每个进程都有自己独立的一块内存空间,一个进程可以有多个线程,比如在Windows系统中,一个运行的xx.exe就是一个进程。 线程 进程中的一个执行任务(控制单元),负责当前进程中程序的执行。一个进程至少有一个线程,一个进程可以运行多个线程,多个线程可共享数据。 与进程不同的是同类的多个线程共享进程的堆和方法区资源,但每个线程有自己的程序计数器、虚拟机栈和本地方法栈,所以系统在产生一个线程,或是在各个线程之间作切换工作时,负担要比进程小得多,也正因为如此,线程也被称为轻量级进程。 Java 程序天生就是多线程程序,我们可以通过 JMX 来看一下一个普通的 Java 程序有哪些线程,代码如下。 public class MultiThread {
public static void main(String[] args) {
// 获取 Java 线程管理 MXBean
ThreadMXBean threadMXBean = ManagementFactory.getThreadMXBean();
// 不需要获取同步的 monitor...
杂七杂八
2026-04-02

分布式深度学习里的通信严重依赖于规则的集群通信,诸如 all-reduce, reduce-scatter, all-gather 等,因此,实现高度优化的集群通信,以及根据任务特点和通信拓扑选择合适的集群通信算法至关重要。 本文以数据并行经常使用的 all-reduce 为例来展示集群通信操作的数学性质。 All-reduce 在干什么? 图 1:all-reduce 如图 1 所示,一共 4个设备,每个设备上有一个矩阵(为简单起见,我们特意让每一行就一个元素), all-reduce 操作的目的是,让每个设备上的矩阵里的每一个位置的数值都是所有设备上对应位置的数值之和。 图2 如图 2 所示, all-reduce 可以通过 reduce-scatter 和 all-gather 这两个更基本的集群通信操作来实现。基于 ring 状通信可以高效的实现 reduce-scatter 和 all-gather,下面我们分别用示意图展示其过程。 reduce-scatter 的实现和性质 图 3:通过环状通信实现 reduce-scatter 从图 2...
Self-Supervised
2026-04-02
相关内容 自监督学习 (Self-supervised):属于无监督学习,其核心是自动为数据打标签(伪标签或其他角度的可信标签,包括图像的旋转、分块等等),通过让网络按照既定的规则,对数据打出正确的标签来更好地进行特征表示,从而应用于各种下游任务。 互信息 (Mutual Information):表示两个变量 \(X\) 和 \(Y\) 之间的关系,定义为: \[I(X;Y)=\sum_{x\in X}\sum_{y\in Y}p(x,y)log\frac{p(x|y)}{p(x)}\] 噪声对抗估计 (Noise Contrastive Estimation, NCE):在NLP任务中一种降低计算复杂度的方法,将语言模型估计问题简化为一个二分类问题。 Introduction 无监督学习一个重要的问题就是学习有用的 representation,本文的目的就是训练一个 representation learning 函数(即编码器encoder) ,其通过最大编码器输入和输出之间的互信息(MI)来学习对下游任务有用的 representation,而互信息可以通过 MINE...
Self-Supervised
2026-04-02

the machine predicts any parts of its input for any observed part 这是LeCun在AAAI 2020上对自监督学习的定义,再结合传统的自监督学习定义,可以总结如下两点特征: 通过“半自动”过程从数据本身获取“标签”; 从“其他部分”预测部分数据。 个人理解, 其实任意挖掘对象之间联系、探索不同对象共同本质的方法,都或多或少算是自监督学习的思想 。 自监督学习与无监督学习的区别主要在于,无监督学习专注于检测特定的数据模式,如聚类、社区发现或异常检测,而自监督学习的目标是恢复(recovering),仍处于监督学习的范式中。上图展示了三者之间的区别, 自监督中的“related information” 可以来自其他模态、输入的其他部分以及输入的不同形式。 Self-Supervised...
Self-Supervised
2026-04-02

如果把 近几年对比学习在视觉领域有代表性的工作做一下总结,那么对比学习的发展历程大概可以分为四个阶段: 百花齐放 这个阶段代表性工作有InstDisc(instance discrimination,)、CPC、CMC等。在这个阶段中,方法、模型、目标函数、代理任务都还没有统一,所以说是一个百花齐放的时代 CV双雄 代表作有MoCo v1、SimCLR v1、MoCo v2、SimCLR v2;CPC、CMC的延伸工作、SwAV等。这个阶段发展非常迅速,有的工作间隔甚至不到一个月,ImageNet上的成绩基本上每个月都在被刷新。 不用负样本 BYOL及其改进工作、SimSiam(CNN在对比学习中的总结性工作) transformer MoCo v3、DINO。这个阶段,无论是对比学习还是最新的掩码学习,都是用Vision Transformer做的。 第一阶段:百花齐放(2018-2019Mid) InstDisc(instance discrimination) 这篇文章提出了个体判别任务(代理任务)以及 memory bank ,非常经典,后人给它的方法起名为InstDisc。...
Deep Learning
2026-03-02

通过卷积和池化等技术可以将图像进行降维,因此,一些研究人员也想办法恢复原分辨率大小的图像,特别是在语义分割领域应用很成熟。 Upsampling(上采样)[没有学习过程] 在FCN、U-net等网络结构中,涉及到了上采样。上采样概念: 上采样指的是任何可以让图像变成更高分辨率的技术 。最简单的方式是 重采样和插值 :将输入图片进行rescale到一个想要的尺寸,而且计算每个点的像素点,使用如双线性插值等插值方法对其余点进行插值来完成上采样过程。 在PyTorch中,上采样的层被封装在 torch.nn 中的 Vision Layers 里面,一共有4种: PixelShuffle Upsample UpsamplingNearest2d UpsamplingBilinear2d PixelShuffle 当stride = (1/r) < 1时,可以让卷积后的feature map变大——即分辨率变大,这个新的操作叫做sub-pixel convolution,具体原理可以看 “PixelShuffle:Real-Time Single Image and Video...
Deep Learning
2026-02-28
现代深度学习库对大多数操作都具有生产级的、高度优化的实现,这并不奇怪。但这些库究竟是什么魔法?他们如何能够将性能提高100倍?究竟怎样才能“优化”或加速神经网络的运行呢?在讨论高性能/高效DNNs时,我经常会问(也经常被问到)这些问题。 在这篇文章中,我将尝试带你了解在DNN库中卷积层是如何实现的。它不仅是在模型中最常见的和最重的操作,我还发现卷积高性能实现的技巧特别具有代表性——一点点算法的小聪明,非常多的仔细的调优和低层架构的开发。 我在这里介绍的很多内容都来自Goto等人的开创性论文:Anatomy of a high-performance matrix multiplication,该论文为OpenBLAS等线性代数库中使用的算法奠定了基础。 最原始的卷积实现 “过早的优化是万恶之源”——Donald Knuth 在进行优化之前,我们先了解一下基线和瓶颈。这是一个朴素的numpy/for循环卷积: '''
Convolve `input` with `kernel` to generate `output`
input.shape =...
Computer Vision
2026-02-26
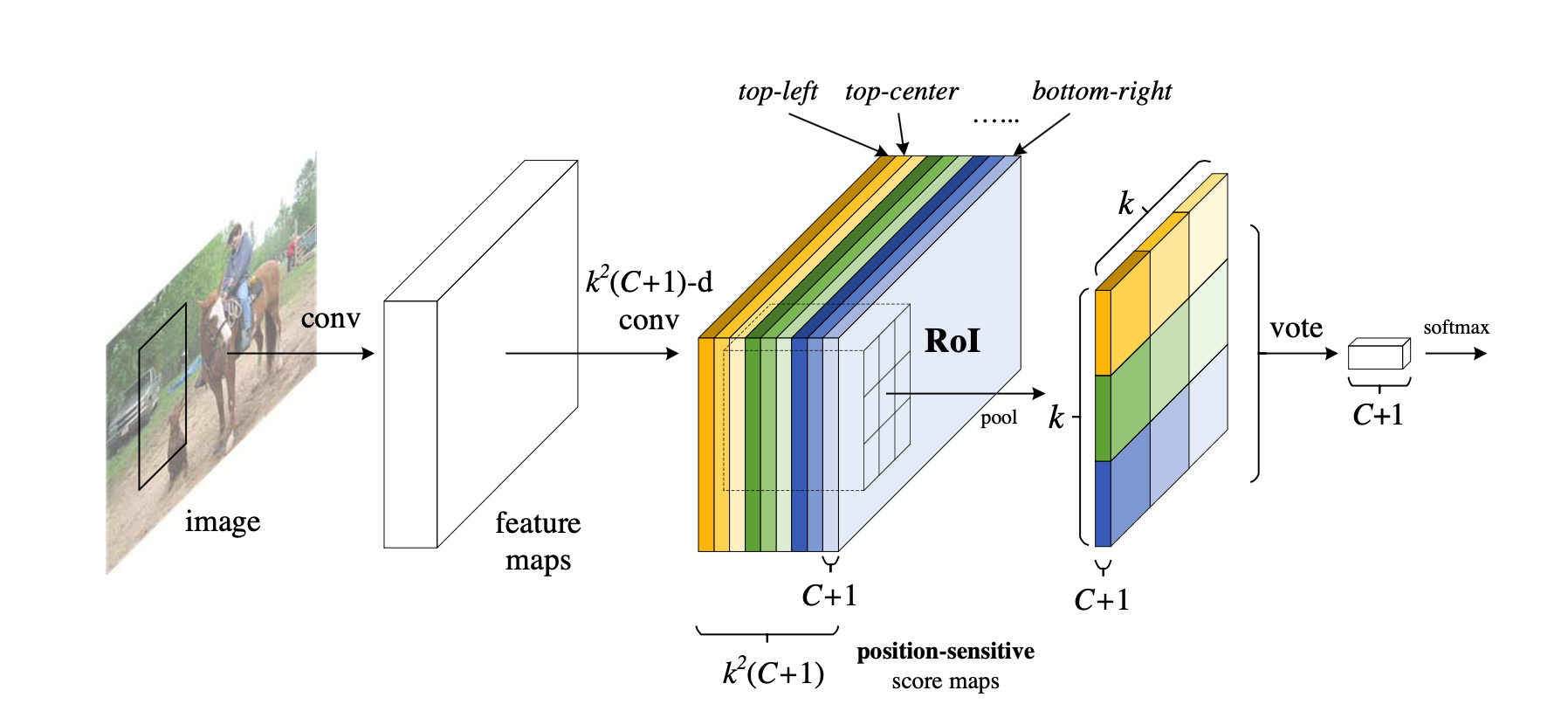
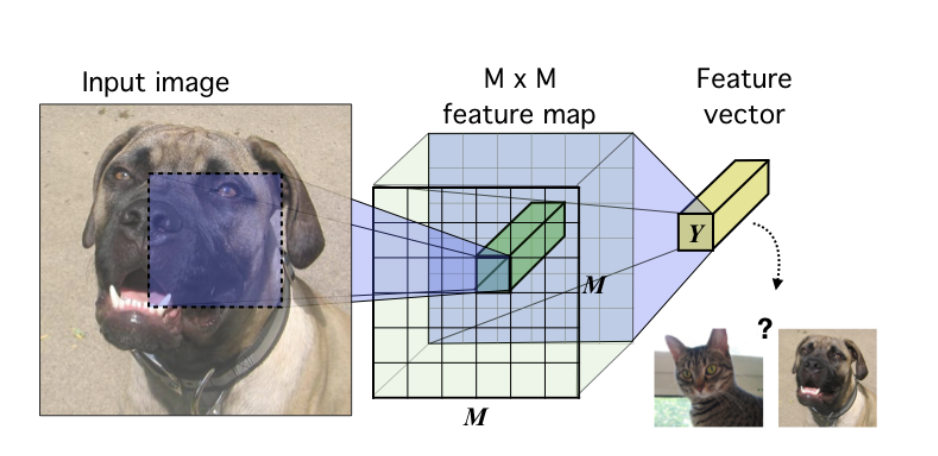
动机 Faster R-CNN是首个利用CNN来完成proposals的预测的,之后的很多目标检测网络都是借助了Faster R-CNN的思想。而Faster R-CNN系列的网络都可以分成2个部分: Fully Convolutional subnetwork before RoI Layer RoI-wise subnetwork 第1部分就是直接用普通分类网络的卷积层,用其来提取共享特征,然后一个RoI Pooling Layer在第1部分的最后一张特征图上进行提取针对各个RoIs的特征向量(或者说是特征图,维度变换一下即可),然后将所有RoIs的特征向量都交由第2部分来处理(分类和回归),而第二部分一般都是一些全连接层,在最后有2个并行的loss函数:softmax和smoothL1,分别用来对每一个RoI进行分类和回归,这样就可以得到每个RoI的真实类别和较为精确的坐标和长宽了。...
Computer Vision
2026-02-26
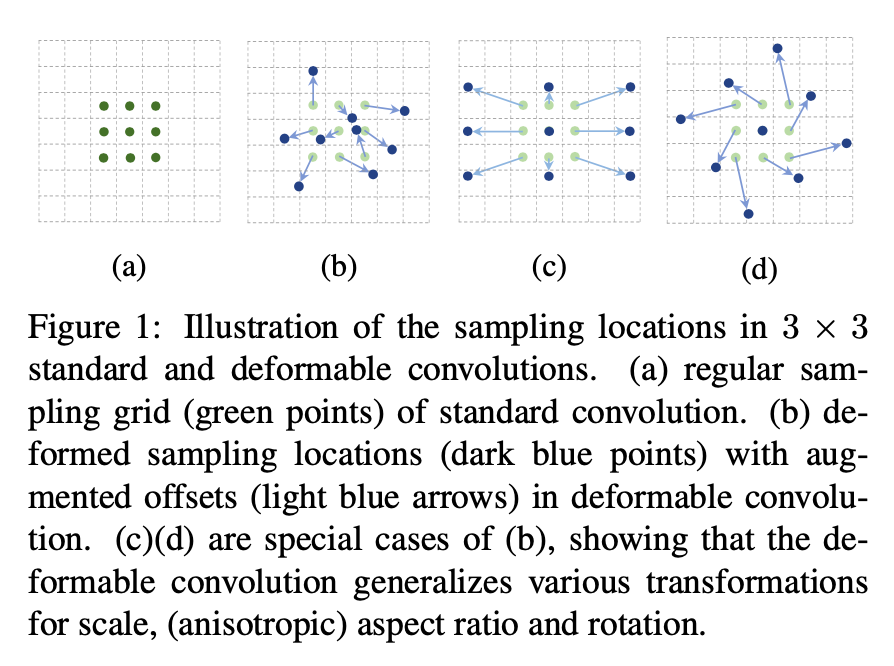
Deformable Conv v1 这篇文章其实比较老了,是 2017 年 5 月出的 Motivation Task 上的难点 视觉任务中一个难点就是如何 model 物体的几何变换,比如由于物体大小,pose, viewpoint 引起的。一般有两类做法: 在数据集上做文章,让 training dataset 就包含所有可能的集合变换。通过 affine transformation 去做 augmentation 另一种就是设计 transformation-invariant (对那些几何变换不变)的 feature 和算法。比如 SIFT 和 sliding window 的方式。 文章说上述两种方式有问题,几何变换我们是事先知道的,这种不能 generalize 到其它场景和任务中。以及 hand-crafted 的设计适应不了负责场景。 CNN 的缺陷 对于geometric transformation 的问题,目前的 CNN 主要是通过 data augmentation 和一些手工设计,比如 max-pooling 解决的(max-pooling...
Computer Vision
2026-02-26

Introduction Inception 在最初的版本 Inception/GoogleNet,其核心思想是利用多尺寸卷积核去观察输入数据。举个栗子,我们看某个景象由于远近不同,同一个物体的大小也会有所不同,那么不同尺度的卷积核观察的特征就会有这样的效果。于是就有了如下的网络结构图: 于是我们的网络就变胖了,通过增加网络的宽度,提高了对于不同尺度的适应程度。但这样的话,计算量有点大了。 Point-wise Conv 为了减少在上面结构的参数量并降低计算量,于是在 Inception V1 的基础版本上加上了 \(1\times 1\) 卷积核,这就形成了 Inception V1 的最终网络结构,如下图。 这个 \(1\times1 \) 卷积就是 Pointwise Convolution ,简称 PW。利用它的目的主要是为了减少维度,还用于引入更多的非线性。 我们来简单计算下:假定上一层输出的 feature map 维度为 \(100\times 100 \times 128\) ,经过256个大小为 \(5\times5 \) 的卷积后,输出的 feature map...
Self-Supervised
2026-01-23
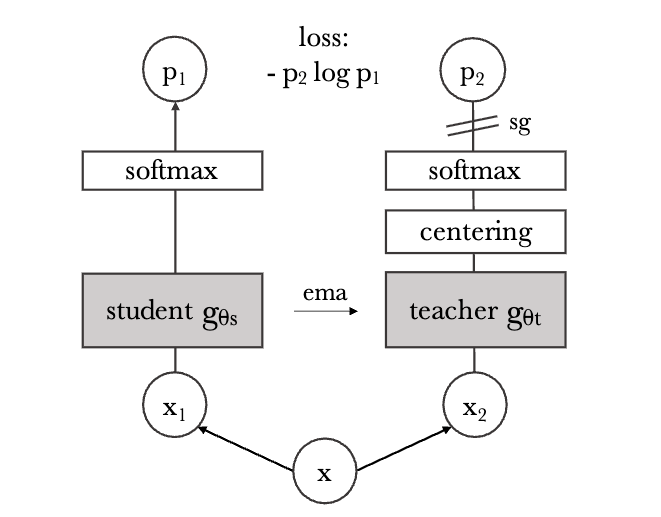
DINO Emerging Properties in Self-Supervised Vision Transformers 论文地址: arxiv.org/pdf/2104.14294 DINO摇摆到了动量式更新,果然【加动量】还是比【只用梯度停止】香。DINO的名字来自于Self- di stillation with no labels中的蒸馏和No标签。 DINO的训练步骤 其实以前的对比学习方案也可以理解为知识蒸馏,DINO里更具体得描述了知识蒸馏的含义。 下图展示了一个样本通过数据增强得到一对views \((x_1,x_2)\) 。注意DINO后面还会使用更复杂的裁剪和对比方案,但这里简单起见先不考虑那些。模型将输入图像的两种不同的随机变换 \(x_1\) 和 \(x_2\) 分别传递给学生和教师网络。 这两个网络具有相同的架构,但参数不同 。教师网络的输出以batch内计算的平均值,进行中心化(减去均值)。每个网络输出一个 \(K\)...
Self-Supervised
2026-01-23
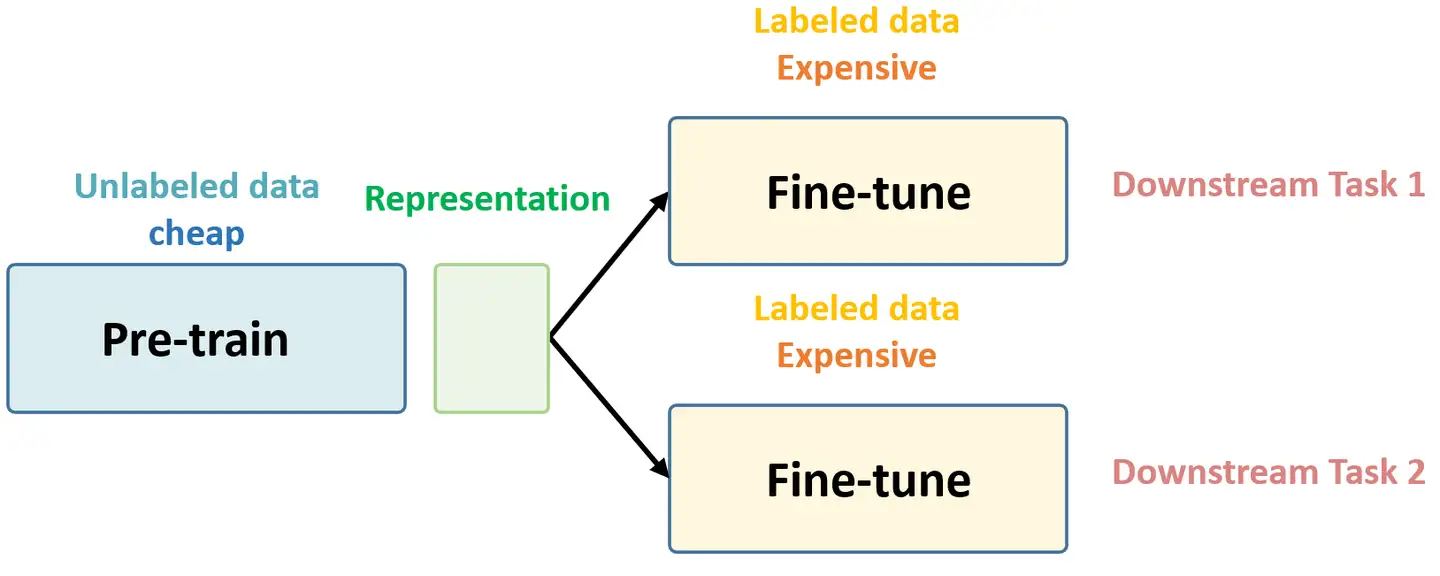
Self-Supervised Learning ,又称为自监督学习,我们知道一般机器学习分为有监督学习,无监督学习和强化学习。 而 Self-Supervised Learning 是无监督学习里面的一种,主要是希望能够学习到一种 通用的特征表达 用于 下游任务 (Downstream Tasks) 。 其主要的方式就是通过自己监督自己。作为代表作的 kaiming 的 MoCo 引发一波热议, Yann Lecun也在 AAAI 上讲 Self-Supervised Learning 是未来的大势所趋。所以在这个系列中,我会系统地解读 Self-Supervised Learning 的经典工作。 总结下 Self-Supervised Learning 的方法,用 4 个英文单词概括一下就是: Unsupervised Pre-train, Supervised Fine-tune. 这段话先放在这里,可能你现在还不一定完全理解,后面还会再次提到它。 在预训练阶段我们使用 无标签的数据集 (unlabeled data) ,因为有标签的数据集 很贵...