
Apache Hadoop 是一款支持数据密集型分布式应用程序并以Apache 2.0许可协议发布的开源软件框架。它支持在商用硬件构建的大型集群上运行的应用程序。Hadoop是根据谷歌公司发表的MapReduce 和Google文件系统的论文自行实现而成。所有的Hadoop模块都有一个基本假设,即硬件故障是常见情况,应该由框架自动处理。具体参考 官方教程 。 Hadoop架构 HDFS: 分布式文件存储 YARN: 分布式资源管理 MapReduce: 分布式计算 Others: 利用YARN的资源管理功能实现其他的数据处理方式 内部各个节点基本都是采用Master-Woker架构 Hadoop HDFS 架构 Block数据块; 基本存储单位,一般大小为64M(配置大的块主要是因为:1)减少搜寻时间,一般硬盘传输速率比寻道时间要快,大的块可以减少寻道时间;2)减少管理块的数据开销,每个块都需要在NameNode上有对应的记录;3)对数据块进行读写,减少建立网络的连接成本)...
杂七杂八
2026-04-02

分布式深度学习里的通信严重依赖于规则的集群通信,诸如 all-reduce, reduce-scatter, all-gather 等,因此,实现高度优化的集群通信,以及根据任务特点和通信拓扑选择合适的集群通信算法至关重要。 本文以数据并行经常使用的 all-reduce 为例来展示集群通信操作的数学性质。 All-reduce 在干什么? 图 1:all-reduce 如图 1 所示,一共 4个设备,每个设备上有一个矩阵(为简单起见,我们特意让每一行就一个元素), all-reduce 操作的目的是,让每个设备上的矩阵里的每一个位置的数值都是所有设备上对应位置的数值之和。 图2 如图 2 所示, all-reduce 可以通过 reduce-scatter 和 all-gather 这两个更基本的集群通信操作来实现。基于 ring 状通信可以高效的实现 reduce-scatter 和 all-gather,下面我们分别用示意图展示其过程。 reduce-scatter 的实现和性质 图 3:通过环状通信实现 reduce-scatter 从图 2...

进程 一个在内存中运行的应用程序。每个进程都有自己独立的一块内存空间,一个进程可以有多个线程,比如在Windows系统中,一个运行的xx.exe就是一个进程。 线程 进程中的一个执行任务(控制单元),负责当前进程中程序的执行。一个进程至少有一个线程,一个进程可以运行多个线程,多个线程可共享数据。 与进程不同的是同类的多个线程共享进程的堆和方法区资源,但每个线程有自己的程序计数器、虚拟机栈和本地方法栈,所以系统在产生一个线程,或是在各个线程之间作切换工作时,负担要比进程小得多,也正因为如此,线程也被称为轻量级进程。 Java 程序天生就是多线程程序,我们可以通过 JMX 来看一下一个普通的 Java 程序有哪些线程,代码如下。 public class MultiThread {
public static void main(String[] args) {
// 获取 Java 线程管理 MXBean
ThreadMXBean threadMXBean = ManagementFactory.getThreadMXBean();
// 不需要获取同步的 monitor...
Reinforcement Learning
2026-03-31
回顾 PPO \[\begin{equation}\begin{aligned}\mathcal{J}_{\text{PPO}}(\theta) &= \mathbb{E}_{(q,a)\sim\mathcal{D}, o_{<t}\sim\pi_{\theta_{\text{old}}}(\cdot|q)} \\
&\left[ \min \left( \frac{\pi_\theta(o_t \mid q, o_{<t})}{\pi_{\theta_{\text{old}}}(o_t \mid q, o_{<t})} \hat{A}_t, \text{clip}\left(\frac{\pi_\theta(o_t \mid q, o_{<t})}{\pi_{\theta_{\text{old}}}(o_t \mid q, o_{<t})}, 1-\varepsilon, 1+\varepsilon\right) \hat{A}_t \right) \right]\end{aligned}\tag{1}\end{equation}\] 其中 \((q, a)\) 是 数据集...
Large Model
2026-03-18
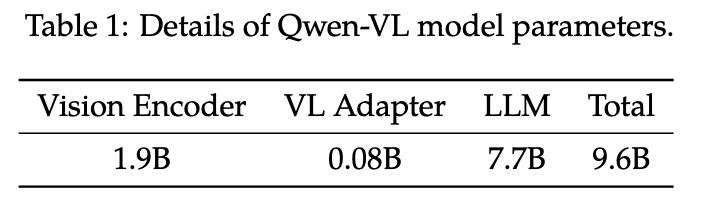
Qwen-VL 模型框架 Qwen-VL的整体网络架构由三个组件组成: LLM:使用 Qwen-7B 的预训练权重进行初始化。 视觉编码器:Qwen-VL 的可视化编码器使用ViT 架构,使用 Openclip 的 ViT-bigG 的预训练权重进行初始化。在训练和推理过程中,输入图像的大小都会调整为特定分辨率。视觉编码器通过以 14 步幅将图像分割成块来处理图像,生成一组图像特征。 位置感知视觉语言适配器:为了缓解长图像特征序列带来的效率问题,Qwen-VL 引入了一种视觉语言适配器来压缩图像特征。类似QFormer,该适配器包括一个随机初始化的单层交叉注意力模块。使用一组可训练向量(嵌入)作为query,并将视觉编码器中的图像特征作为交叉注意力作的key。该机制将视觉特征序列压缩到固定长度 256。 图像输入 图像不会直接以像素形式喂给语言模型(LLM)。 典型流程是: Visual Encoder :把图片编码成一串视觉特征(embedding/feature sequence)。 Adapter :把视觉特征映射到语言模型可接入的表征空间/维度。 最终得到:...
Large Model
2026-03-12

概述 MTP(Multi-token Prediction)的总体思路是:让模型使用n个独立的输出头来预测接下来的n个token,这n个独立的输出头共享同一个模型主干。这样通过解码阶段的优化,将1-token的生成,转变成multi-token的生成,从而提升训练和推理的性能。 在DeepSeek之前也有几个MTP方案,其侧重点各自不同。 侧重推理时解码加速。比如论文“MEDUSA: Simple LLM Inference Acceleration Framework with Multiple Decoding Heads”、论文“EAGLE: Speculative Sampling Requires Rethinking Feature Uncertainty”等。这些方案通过一次生成多个token,实现成倍的加速来提升推理性能。 侧重训练时提高效率。比如论文“Better & Faster Large Language Models via Multi-token...
Large Model
2026-03-12

概述 https://github.com/FasterDecoding/Medusa Medusa 是自投机领域较早的一篇工作,对后续工作启发很大,其主要思想是 multi-decoding head + tree attention + typical acceptance(threshold)。Medusa 没有使用独立的草稿模型,而是在原始模型的基础上增加多个解码头(MEDUSA heads),并行预测多个后续 token。 正常的LLM只有一个用于预测 \(t\) 时刻token的head。Medusa 在 LLM 的最后一个 Transformer层之后保留原始的 LM Head,然后额外增加多个(假设是 \(k\) 个) 可训练的Medusa Head(解码头),分别负责预测 \(t+1,t+2,...,\) 和 \(t+k\) 时刻的不同位置的多个 Token。 Medusa 让每个头生成多个候选 token,而非像投机解码那样只生成一个候选。然后将所有的候选结果组装成多个候选序列,多个候选序列又构成一棵树。再通过树注意力机制并行验证这些候选序列 。 原理...
Large Model
2026-03-10

概述 投机解码(Speculative Decoding)也叫预测解码/投机采样,它会利用小模型来预测大型模型的行为,从而提升模型在解码(decoding)阶段的解码效率问题,加速大型模型的执行。其核心思路如下图所示,首先以低成本的方式(以小模型为主,也有多头,检索,Early Exit 等方式)快速生成多个候选 Token(串行序列、树、多头树等),然后通过一次并行验证阶段快速验证多个 Token的正确性,只要平均每个 Step 验证的 Token 数 > 1,就可以一次性生成多个token,进而减少总的 Decoding 步数,实现加速的目的。 下图左侧是自回归解码模型,右侧是投机解码机制。 从本质上来说,投机解码希望在推理阶段在不大幅度改变模型的情况下,通过更好利用冗余算力来并行"投机"地猜测出模型接下来要输出的token。作为对比,也有一种方案是通过路由的方式组合多个不同规模和性能的模型。路由方式在调用之前已经确定好需要调用哪个模型,直到调用结束。而投机解码在一个 Query 内会反复调用大小模型。 背景 我们都知道,生成式 LLM 大部分是 Decoder-only...
Large Model
2026-03-10

引言 Structured Generation with LLM,是指 让LLM按照预先定义的schema,输出符合schema的结构化结果 。 常见的应用场景有: 数据处理 。主要功能为a -> b,即从源文本中 抽取/生成 符合schema的结果,例如给定新闻,进行分类、抽取关键词、生成总结等; Agent 。主要功能是Tool Calling,即根据用户query,选择适当的tool和入参。 将 LLM 限制为始终生成符合特定模式的、有效的 JSON 或 YAML,是许多应用的关键功能。 Kor Kor ,一个 基于prompt的技术方案 ;Kor比较适合 数据处理 场景,且原理简单、易于理解,适合作为入门, 并且Kor适用于那些不支持function calling的比较旧的模型。 使用Kor进行structured generation的流程如下: 定义schema,包括结构、注释还有例子; Kor用特定的 prompt template ,将用户提供的schema和待处理的raw text,组装成prompt; 将prompt发送给LLM,借助其通用的In...
Large Model
2026-03-10

k1.5—CoT强化训练 概述 Kimi k1.5采用了一种简化而有效的强化学习框架,其核心在于长上下文扩展和改进的策略优化方法,而不依赖于更复杂的技术如蒙特卡洛树搜索、价值函数和过程奖励模型。 问题设定 给定训练数据集 \(D = \{(x_i, y^*_i)\}_{i=1}^n\) ,其中包含问题 \(x_i\) 和对应的真实答案 \(y^*_i\) ,目标是训练一个策略模型 \(\pi_\theta\) 来准确解决测试问题。在复杂推理场景中,思维链(CoT)方法提出使用一系列中间步骤 \(z = (z_1, z_2, ..., z_m)\) 来连接问题 \(x\) 和答案 \(y\) ,每个 \(z_i\) 是解决问题的重要中间步骤。 当解决问题 \(x\) 时,思维 \(z_t \sim \pi_\theta(\cdot|x, z_1, ..., z_{t-1})\) 被自回归采样,最终答案 \(y \sim \pi_\theta(\cdot|x, z_1, ..., z_m)\) 。 强化学习目标 基于真实答案 \(y^*\) ,分配一个值 \(r(x, y, y^*)...