
进程 一个在内存中运行的应用程序。每个进程都有自己独立的一块内存空间,一个进程可以有多个线程,比如在Windows系统中,一个运行的xx.exe就是一个进程。 线程 进程中的一个执行任务(控制单元),负责当前进程中程序的执行。一个进程至少有一个线程,一个进程可以运行多个线程,多个线程可共享数据。 与进程不同的是同类的多个线程共享进程的堆和方法区资源,但每个线程有自己的程序计数器、虚拟机栈和本地方法栈,所以系统在产生一个线程,或是在各个线程之间作切换工作时,负担要比进程小得多,也正因为如此,线程也被称为轻量级进程。 Java 程序天生就是多线程程序,我们可以通过 JMX 来看一下一个普通的 Java 程序有哪些线程,代码如下。 public class MultiThread {
public static void main(String[] args) {
// 获取 Java 线程管理 MXBean
ThreadMXBean threadMXBean = ManagementFactory.getThreadMXBean();
// 不需要获取同步的 monitor...
杂七杂八
2026-04-02

分布式深度学习里的通信严重依赖于规则的集群通信,诸如 all-reduce, reduce-scatter, all-gather 等,因此,实现高度优化的集群通信,以及根据任务特点和通信拓扑选择合适的集群通信算法至关重要。 本文以数据并行经常使用的 all-reduce 为例来展示集群通信操作的数学性质。 All-reduce 在干什么? 图 1:all-reduce 如图 1 所示,一共 4个设备,每个设备上有一个矩阵(为简单起见,我们特意让每一行就一个元素), all-reduce 操作的目的是,让每个设备上的矩阵里的每一个位置的数值都是所有设备上对应位置的数值之和。 图2 如图 2 所示, all-reduce 可以通过 reduce-scatter 和 all-gather 这两个更基本的集群通信操作来实现。基于 ring 状通信可以高效的实现 reduce-scatter 和 all-gather,下面我们分别用示意图展示其过程。 reduce-scatter 的实现和性质 图 3:通过环状通信实现 reduce-scatter 从图 2...
Self-Supervised
2026-04-02
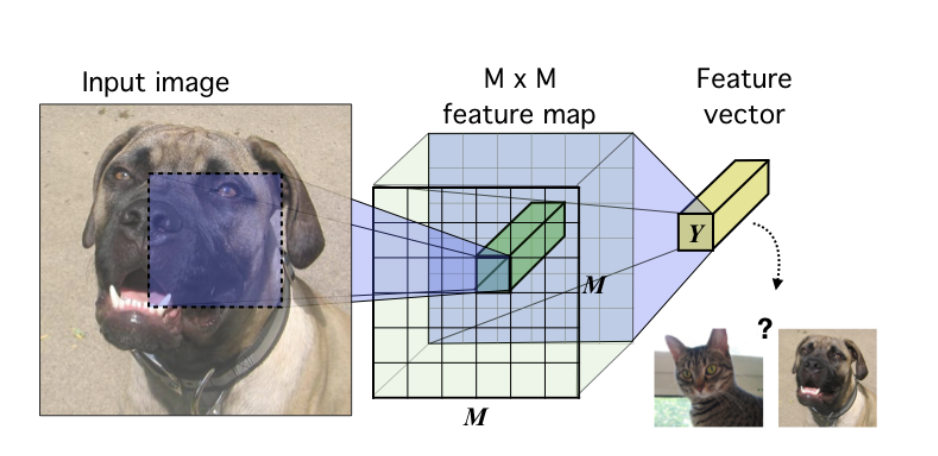
相关内容 自监督学习 (Self-supervised):属于无监督学习,其核心是自动为数据打标签(伪标签或其他角度的可信标签,包括图像的旋转、分块等等),通过让网络按照既定的规则,对数据打出正确的标签来更好地进行特征表示,从而应用于各种下游任务。 互信息 (Mutual Information):表示两个变量 \(X\) 和 \(Y\) 之间的关系,定义为: \[I(X;Y)=\sum_{x\in X}\sum_{y\in Y}p(x,y)log\frac{p(x|y)}{p(x)}\] 噪声对抗估计 (Noise Contrastive Estimation, NCE):在NLP任务中一种降低计算复杂度的方法,将语言模型估计问题简化为一个二分类问题。 Introduction 无监督学习一个重要的问题就是学习有用的 representation,本文的目的就是训练一个 representation learning 函数(即编码器encoder) ,其通过最大编码器输入和输出之间的互信息(MI)来学习对下游任务有用的 representation,而互信息可以通过 MINE...
Self-Supervised
2026-04-02

如果把 近几年对比学习在视觉领域有代表性的工作做一下总结,那么对比学习的发展历程大概可以分为四个阶段: 百花齐放 这个阶段代表性工作有InstDisc(instance discrimination,)、CPC、CMC等。在这个阶段中,方法、模型、目标函数、代理任务都还没有统一,所以说是一个百花齐放的时代 CV双雄 代表作有MoCo v1、SimCLR v1、MoCo v2、SimCLR v2;CPC、CMC的延伸工作、SwAV等。这个阶段发展非常迅速,有的工作间隔甚至不到一个月,ImageNet上的成绩基本上每个月都在被刷新。 不用负样本 BYOL及其改进工作、SimSiam(CNN在对比学习中的总结性工作) transformer MoCo v3、DINO。这个阶段,无论是对比学习还是最新的掩码学习,都是用Vision Transformer做的。 第一阶段:百花齐放(2018-2019Mid) InstDisc(instance discrimination) 这篇文章提出了个体判别任务(代理任务)以及 memory bank ,非常经典,后人给它的方法起名为InstDisc。...
NLP
2026-03-26

概述 众所周知,尽管基于Attention机制的Transformer类模型有着良好的并行性能,但它的空间和时间复杂度都是 \(\mathcal{O}(n^2)\) 级别的, \(n\) 是序列长度,所以当 \(n\) 比较大时Transformer模型的计算量难以承受。近来,也有不少工作致力于降低Transformer模型的计算量,比如模型剪枝、量化、蒸馏等精简技术,又或者修改Attention结构,使得其复杂度能降低到 \(\mathcal{O}(n\log n)\) 甚至 \(\mathcal{O}(n)\) 。 改变这一复杂度的思路主要有两种: 一是走稀疏化的思路,比如OpenAI的 Sparse Attention ,通过“只保留小区域内的数值、强制让大部分注意力为零”的方式,来减少Attention的计算量。经过特殊设计之后,Attention矩阵的大部分元素都是0,因此理论上它也能节省显存占用量和计算量。后续类似工作还有 《Explicit Sparse Transformer: Concentrated Attention Through Explicit...
NLP
2026-03-26

Attention 当前最流行的Attention机制当属 Scaled-Dot Attention,形式为 \[\begin{equation}Attention(\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V}) = softmax\left(\boldsymbol{Q}\boldsymbol{K}^{\top}\right)\boldsymbol{V}\tag{1}\end{equation}\] 这里的 \(\boldsymbol{Q}\in\mathbb{R}^{n\times d_k}, \boldsymbol{K}\in\mathbb{R}^{m\times d_k}, \boldsymbol{V}\in\mathbb{R}^{m\times d_v}\) ,简单起见我们就没显式地写出Attention的缩放因子了。本文我们主要关心Self Attention场景,所以为了介绍上的方便统一设 \(\boldsymbol{Q}, \boldsymbol{K}, \boldsymbol{V}\in\mathbb{R}^{n\times...
Attention 当前最流行的Attention机制当属 Scaled-Dot Attention,形式为 \[\begin{equation}Attention(\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V}) = softmax\left(\boldsymbol{Q}\boldsymbol{K}^{\top}\right)\boldsymbol{V}\tag{1}\end{equation}\] 这里的 \(\boldsymbol{Q}\in\mathbb{R}^{n\times d_k}, \boldsymbol{K}\in\mathbb{R}^{m\times d_k}, \boldsymbol{V}\in\mathbb{R}^{m\times d_v}\) ,简单起见我们就没显式地写出Attention的缩放因子了。本文我们主要关心Self Attention场景,所以为了介绍上的方便统一设 \(\boldsymbol{Q}, \boldsymbol{K}, \boldsymbol{V}\in\mathbb{R}^{n\times...
NLP
2026-03-26

概述 SSM的概念由来已久,但这里我们特指深度学习中的SSM,一般认为其开篇之作是2021年的 S4 ,不算太老,而SSM最新最火的变体大概是 Mamba 。当然,当我们谈到SSM时,也可能泛指一切线性RNN模型,这样 RWKV 、 RetNet 还有此前LRU都可以归入此类。不少SSM变体致力于成为Transformer的竞争者,尽管笔者并不认为有完全替代的可能性,但SSM本身优雅的数学性质也值得学习一番。 尽管我们说SSM起源于S4,但在S4之前,SSM有一篇非常强大的奠基之作 《HiPPO: Recurrent Memory with Optimal Polynomial Projections》 (简称HiPPO),所以本文从HiPPO开始说起。 另外值得一提的是,SSM代表作HiPPO、S4、Mamba的一作都是 Albert Gu ,他还有很多篇SSM相关的作品,毫不夸张地说,这些工作筑起了SSM大厦的基础。不论SSM前景如何,这种坚持不懈地钻研同一个课题的精神都值得我们由衷地敬佩。 今天,基本上你能叫出的任何语言模型都是 Transformer 模型。OpenAI 的...
NLP
2026-03-25

概述 本文模型脉络图 本文介绍一个比较有意思的高效Transformer工作——来自Google的 《Transformer Quality in Linear Time》 , 什么样的结果值得我们用“惊喜”来形容?有没有言过其实?我们不妨先来看看论文做到了什么: 提出了一种新的Transformer变体,它依然具有二次的复杂度,但是相比标准的Transformer,它有着更快的速度、更低的显存占用以及更好的效果; 提出一种新的线性化Transformer方案,它不但提升了原有线性Attention的效果,还保持了做Decoder的可能性,并且做Decoder时还能保持高效的训练并行性。 说实话,笔者觉得做到以上任意一点都是非常难得的,而这篇论文一下子做到了两点,所以我愿意用“惊喜满满”来形容它。更重要的是,论文的改进总的来说还是比较自然和优雅的,不像很多类似工作一样显得很生硬。此外,笔者自己也做了简单的复现实验,结果显示论文的可复现性应该是蛮好的,所以真的有种“Transformer危矣”的感觉了。 门控注意(Gated Attention Unit)...
NLP
2026-03-25

Attention 当前最流行的Attention机制当属 Scaled-Dot Attention,形式为 \[Attention(\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V}) = softmax\left(\boldsymbol{Q}\boldsymbol{K}^{\top}\right)\boldsymbol{V}\tag{1}\] 这里的 \(\boldsymbol{Q}\in\mathbb{R}^{n\times d_k}, \boldsymbol{K}\in\mathbb{R}^{m\times d_k}, \boldsymbol{V}\in\mathbb{R}^{m\times d_v}\) ,简单起见我们就没显式地写出Attention的缩放因子了。本文我们主要关心Self Attention场景,所以为了介绍上的方便统一设 \(\boldsymbol{Q}, \boldsymbol{K}, \boldsymbol{V}\in\mathbb{R}^{n\times d}\) ,一般场景下都有 \(n > d\) 甚至...
Computer Vision
2026-02-26

Introduction Inception 在最初的版本 Inception/GoogleNet,其核心思想是利用多尺寸卷积核去观察输入数据。举个栗子,我们看某个景象由于远近不同,同一个物体的大小也会有所不同,那么不同尺度的卷积核观察的特征就会有这样的效果。于是就有了如下的网络结构图: 于是我们的网络就变胖了,通过增加网络的宽度,提高了对于不同尺度的适应程度。但这样的话,计算量有点大了。 Point-wise Conv 为了减少在上面结构的参数量并降低计算量,于是在 Inception V1 的基础版本上加上了 \(1\times 1\) 卷积核,这就形成了 Inception V1 的最终网络结构,如下图。 这个 \(1\times1 \) 卷积就是 Pointwise Convolution ,简称 PW。利用它的目的主要是为了减少维度,还用于引入更多的非线性。 我们来简单计算下:假定上一层输出的 feature map 维度为 \(100\times 100 \times 128\) ,经过256个大小为 \(5\times5 \) 的卷积后,输出的 feature map...
Self-Supervised
2026-01-23
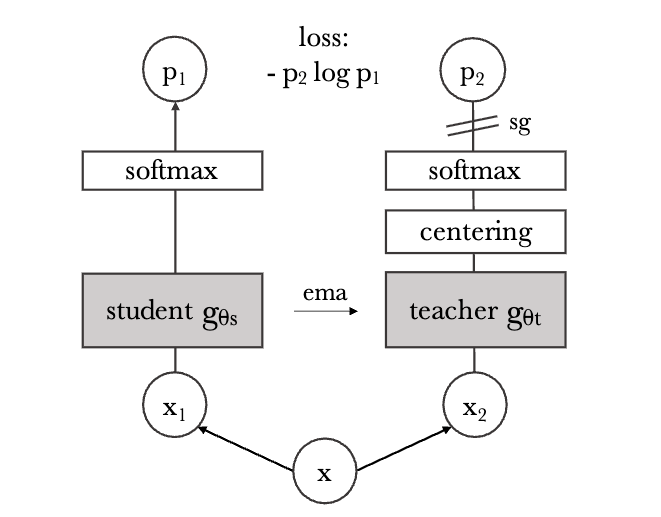
DINO Emerging Properties in Self-Supervised Vision Transformers 论文地址: arxiv.org/pdf/2104.14294 DINO摇摆到了动量式更新,果然【加动量】还是比【只用梯度停止】香。DINO的名字来自于Self- di stillation with no labels中的蒸馏和No标签。 DINO的训练步骤 其实以前的对比学习方案也可以理解为知识蒸馏,DINO里更具体得描述了知识蒸馏的含义。 下图展示了一个样本通过数据增强得到一对views \((x_1,x_2)\) 。注意DINO后面还会使用更复杂的裁剪和对比方案,但这里简单起见先不考虑那些。模型将输入图像的两种不同的随机变换 \(x_1\) 和 \(x_2\) 分别传递给学生和教师网络。 这两个网络具有相同的架构,但参数不同 。教师网络的输出以batch内计算的平均值,进行中心化(减去均值)。每个网络输出一个 \(K\)...