Large Model
2026-01-20
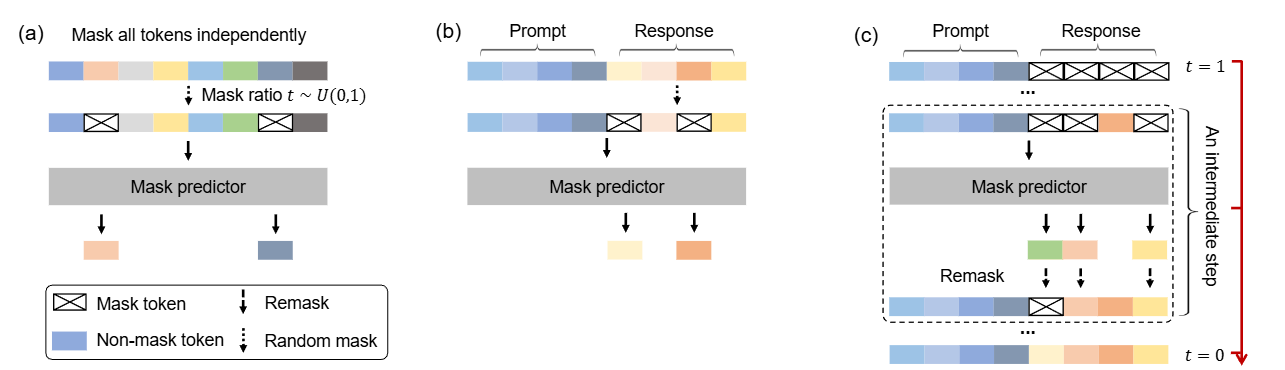
这是一篇尝试改变LLM「范式」的文章:当前主流的LLM架构都是「自回归」的,通俗地理解就是必须「从左到右依次生成」。这篇文章挑战了这一范式,探索扩散模型在 LLMs 上的可行性,通过 随机掩码 - 预测 的逆向思维,让模型学会「全局思考」。 论文: [2502.09992] Large Language Diffusion Models 背景 主流大语言模型架构:自回归模型 (Autoregressive LLMs) 过去几年, 自回归模型(Autoregressive Models, ARMs)一直是大语言模型(LLM)的主流架构。典型的自回归语言模型以Transformer解码器为基础,按照从左到右 的顺序依次预测下一个词元(token)。 形式化地,自回归模型将一个长度为 \(N\) 的文本序列 \(X=(x_1, x_2, ..., x_N)\) 的概率分解为各位置的条件概率连乘积: \[P_{\theta}(x_1, x_2, \dots, x_N) = \prod_{i=1}^{N} P_{\theta}(x_i \mid x_1, x_2, \dots,...