128. 最长连续序列 题目 给定一个未排序的整数数组 nums ,找出数字连续的最长序列(不要求序列元素在原数组中连续)的长度。 请你设计并实现时间复杂度为 O(n) 的算法解决此问题。 示例 1: 输入:nums = [100,4,200,1,3,2]
输出:4
解释:最长数字连续序列是 [1, 2, 3, 4]。它的长度为 4。 示例 2: 输入:nums = [0,3,7,2,5,8,4,6,0,1]
输出:9 示例 3: 输入:nums = [1,0,1,2]
输出:3 提示: 0 <= nums.length <= 10 5 -10 9 <= nums[i] <= 10 9 题解 我们需要在 \(O(1)\) 的时间内查找某个数是否存在。因此,首先将数组中的所有元素放入一个 HashSet 中。这不仅能去重,还能支持快速查找。 避免冗余计算 (关键优化) 如果我们对集合中的每一个数都尝试去向后计数(例如,对于 x ,尝试找 x+1 , x+2 ...),最坏情况下的时间复杂度会退化到 \(O(n^2)\) 。 优化策略 : 我们 只从序列的起点开始计数 。...
76. 最小覆盖子串 题目 给定两个字符串 s 和 t ,长度分别是 m 和 n ,返回 s 中的 最短窗口 子串 ,使得该子串包含 t 中的每一个字符( 包括重复字符 )。如果没有这样的子串,返回空字符串 "" 。 测试用例保证答案唯一。 示例 1: 输入:s = "ADOBECODEBANC", t = "ABC"
输出:"BANC"
解释:最小覆盖子串 "BANC" 包含来自字符串 t 的 'A'、'B' 和 'C'。 示例 2: 输入:s = "a", t = "a"
输出:"a"
解释:整个字符串 s 是最小覆盖子串。 示例 3: 输入: s = "a", t = "aa"
输出: ""
解释: t 中两个字符 'a' 均应包含在 s 的子串中,
因此没有符合条件的子字符串,返回空字符串。 提示: m == s.length n == t.length 1 <= m, n <= 10 5 s 和 t 由英文字母组成 题解 这是一个经典的 滑动窗口 (Sliding Window) 问题 我们需要维护一个动态的窗口 [left, right] : 右移扩大 :不断移动...

Quick Start 一个最简单的DDP Pytorch例子! 环境准备 PyTorch(gpu)=1.5,python=3.6 推荐使用官方打好的PyTorch docker,避免乱七八糟的环境问题影响心情。 [代码] 代码 单GPU代码 [代码] 加入DDP的代码 [代码] DDP的基本原理 大白话原理 假如我们有N张显卡, 1. (缓解GIL限制)在DDP模式下,会有N个进程被启动,每个进程在一张卡上加载一个模型,这些模型的参数在数值上是相同的。 1. (RingReduce加速)在模型训练时,各个进程通过一种叫RingReduce的方法与其他进程通讯,交换各自的梯度,从而获得所有进程的梯度; 1. (实际上就是Data Parallelism)各个进程用平均后的梯度更新自己的参数,...
Python
2026-01-11
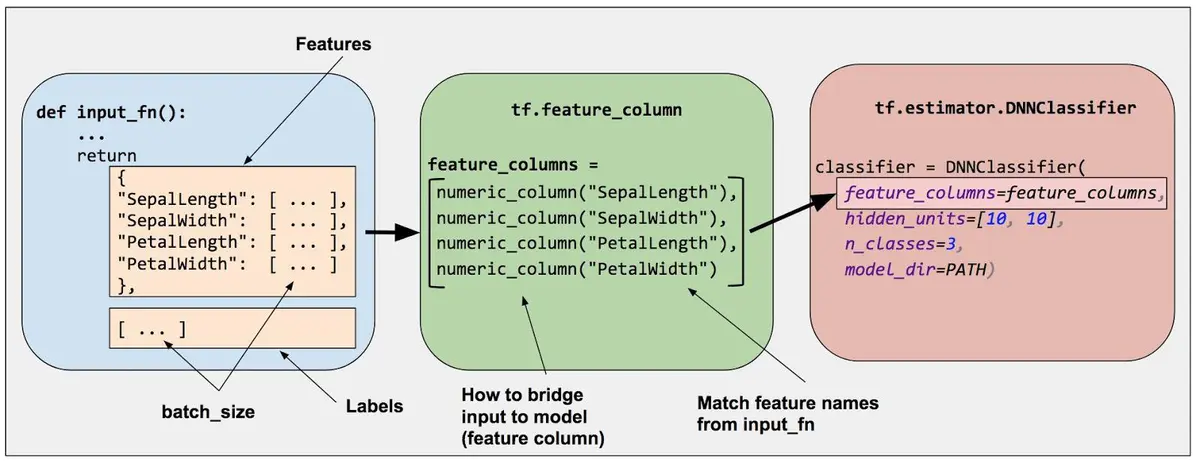
Overview 特征工程是机器学习流程中重要的一个环节,即使是通常用来做端到端学习的深度学习模型在训练之前也免不了要做一些特征工程相关的工作。Tensorflow平台提供的FeatureColumn API为特征工程提供了强大的支持。 Feature cloumns是原始数据和Estimator模型之间的桥梁,它们被用来把各种形式的原始数据转换为模型能够使用的格式。深度神经网络只能处理数值数据,网络中的每个神经元节点执行一些针对输入数据和网络权重的乘法和加法运算。然而,现实中的有很多非数值的类别数据,比如产品的品牌、类目等,这些数据如果不加转换,神经网络是无法处理的。另一方面,即使是数值数据,在仍给网络进行训练之前有时也需要做一些处理,比如标准化、离散化等。 在Tensorflow中,通过...
Python
2026-01-11
@tf_export为函数取了个名字! Tensorflow经常看到定义的函数前面加了@tf_export。例如,tensorflow/python/platform/app.py中有: [代码] 首先,@tf_export是一个修饰符。修饰符的本质是一个函数 tf_export的实现在tensorflow/python/util/tf_export.py中: [代码] 等号的右边的理解分两步: 1. functools.partial 1. api_export functools.partial是偏函数,它的本质简而言之是为函数固定某些参数。如:functools.partial(FuncA, p1)的作用是把函数FuncA的第一个参数固定为p1;又如functools.partial(...
Python
2026-01-11
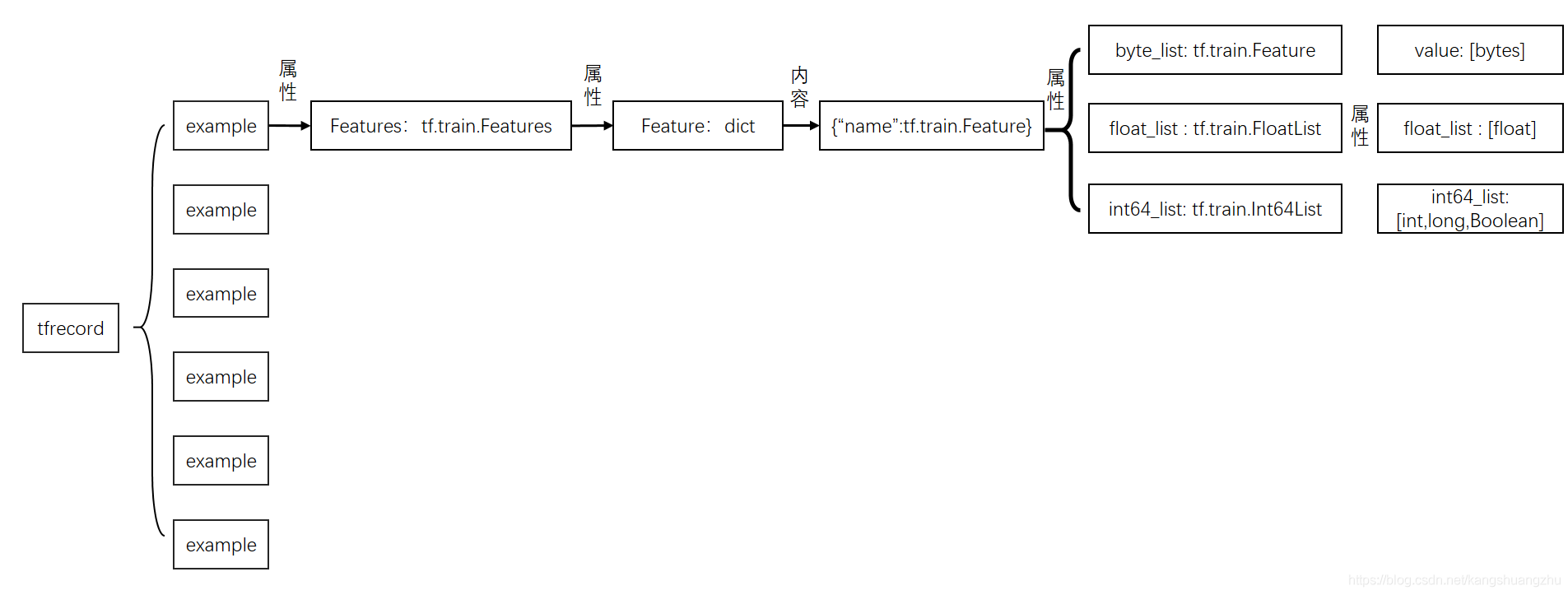
TFRecord TFRecord 是谷歌推荐的一种二进制文件格式,理论上它可以保存任何格式的信息。 tf.Example是一个Protobuffer定义的message,表达了一组string到bytes value的映射。TFRecord文件里面其实就是存储的序列化的tf.Example。关于Protobuffer参考Protobuf 终极教程。 example 我们可以具体到相关代码去详细地看下tf.Example的构成。作为一个Protobuffer message,它被定义在文件core/example/example.proto中: [代码] 只是包了一层Features的message。我们还需要进一步去查找Features的message定义: [代码] 到这里,我们可以看出...
Large Model
2026-01-11

引言与背景 FlashAttention的关键创新在于使用类似于在线Softmax的思想来对自注意力计算进行分块(tiling),从而能够融合整个多头注意力层的计算,而无需访问GPU全局内存来存储中间的logits和注意力分数 在深度学习中,Transformer模型的自注意力机制是计算密集型操作。传统实现需要在GPU全局内存中存储大量中间结果,这导致: 内存瓶颈:中间矩阵占用大量显存 I/O开销:频繁的全局内存访问降低效率 扩展性限制:难以处理超长序列 FlashAttention通过算法创新解决了这些问题。 SelfAtention 自注意力机制的计算可以总结为(为简化说明,忽略头数和批次维度,也省略注意力掩码和缩放因子 [Math] ): [公式] 其中: Q, K, V, O 都是形...
PyTorch中,所有神经网络的核心是 autograd 包。 autograd 包为张量上的所有操作提供了自动求导机制。它是一个在运行时定义(definebyrun)的框架,这意味着反向传播是根据代码如何运行来决定的,并且每次迭代可以是不同的. 让我们用一些简单的例子来看看吧。 张量 torch.Tensor 是这个包的核心类。如果设置它的属性 .requires_grad 为 True,那么它将会追踪对于该张量的所有操作。当完成计算后可以通过调用 .backward(),来自动计算所有的梯度。这个张量的所有梯度将会自动累加到.grad属性. 要阻止一个张量被跟踪历史,可以调用 .detach() 方法将其与计算历史分离,并阻止它未来的计算记录被跟踪。 为了防止跟踪历史记录(和使用内存),...
Python
2026-01-11

相同点 nn.Xxx和nn.functional.xxx的实际功能是相同的,即nn.Conv2d和nn.functional.conv2d 都是进行卷积,nn.Dropout 和nn.functional.dropout都是进行dropout,。。。。。; 运行效率也是近乎相同。 nn.functional.xxx是函数接口,而nn.Xxx是nn.functional.xxx的类封装,并且nn.Xxx都继承于一个共同祖先nn.Module。这一点导致nn.Xxx除了具有nn.functional.xxx功能之外,内部附带了nn.Module相关的属性和方法,例如train(), eval(),load_state_dict, state_dict 等。 不同点 两者的调用方式不同。 nn.X...
Large Model
2026-01-11

通常我们训练神经网络模型的时候默认使用的数据类型为单精度FP32。近年来,为了加快训练时间、减少网络训练时候所占用的内存,并且保存训练出来的模型精度持平的条件下,业界提出越来越多的混合精度训练的方法。这里的混合精度训练是指在训练的过程中,同时使用单精度(FP32)和半精度(FP16)。 浮点数据类型 浮点数据类型主要分为双精度(FP64)、单精度(FP32)、半精度(FP16)。在神经网络模型的训练过程中,一般默认采用单精度(FP32)浮点数据类型,来表示网络模型权重和其他参数。在了解混合精度训练之前,这里简单了解浮点数据类型。 根据IEEE二进制浮点数算术标准(IEEE 754)的定义,浮点数据类型分为双精度(FP64)、单精度(FP32)、半精度(FP16)三种,其中每一种都有三个不同的...
Large Model
2026-01-11

概述 Medusa 是自投机领域较早的一篇工作,对后续工作启发很大,其主要思想是 multidecoding head + tree attention + typical acceptance(threshold)。Medusa 没有使用独立的草稿模型,而是在原始模型的基础上增加多个解码头(MEDUSA heads),并行预测多个后续 token。 正常的LLM只有一个用于预测 t 时刻token的head。Medusa 在 LLM 的最后一个 Transformer层之后保留原始的 LM Head,然后额外增加多个(假设是 k 个) 可训练的Medusa Head(解码头),分别负责预测 ...
Large Model
2026-01-11

概述 MTP(Multitoken Prediction)的总体思路是:让模型使用n个独立的输出头来预测接下来的n个token,这n个独立的输出头共享同一个模型主干。这样通过解码阶段的优化,将1token的生成,转变成multitoken的生成,从而提升训练和推理的性能。 在DeepSeek之前也有几个MTP方案,其侧重点各自不同。 侧重推理时解码加速。比如论文“MEDUSA: Simple LLM Inference Acceleration Framework with Multiple Decoding Heads”、论文“EAGLE: Speculative Sampling Requires Rethinking Feature Uncertainty”等。这些方案通过一次生成多个...