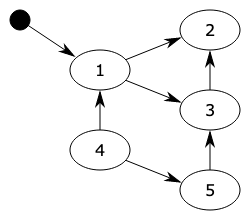
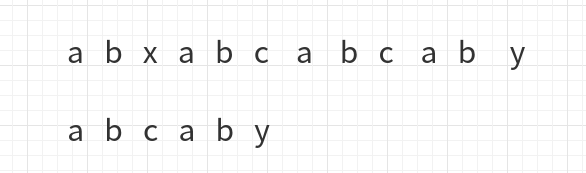杂七杂八
2026-03-27
生成器 什么是生成器? 通过列表生成式,我们可以直接创建一个列表,但是,受到内存限制,列表容量肯定是有限的,而且创建一个包含100万个元素的列表,不仅占用很大的存储空间,如果我们仅仅需要访问前面几个元素,那后面绝大多数元素占用的空间都白白浪费了。 所以,如果列表元素可以按照某种算法推算出来,那我们是否可以在循环的过程中不断推算出后续的元素呢?这样就不必创建完整的list,从而节省大量的空间,在Python中, 这种一边循环一边计算的机制,称为生成器:generator 生成器是一个特殊的程序,可以被用作控制循环的迭代行为,python中生成器是迭代器的一种,使用 yield 返回值函数,每次调用 yield 会暂停,而可以使用 next() 函数和 send() 函数恢复生成器。 生成器类似于返回值为数组的一个函数,这个函数可以接受参数,可以被调用,但是,不同于一般的函数会一次性返回包括了所有数值的数组,生成器一次只能产生一个值,这样消耗的内存数量将大大减小,而且允许调用函数可以很快的处理前几个返回值,因此生成器看起来像是一个函数,但是表现得却像是迭代器 python中的生成器...