
11. 盛最多水的容器 题目 给定一个长度为 n 的整数数组 height 。有 n 条垂线,第 i 条线的两个端点是 (i, 0) 和 (i, height[i]) 。 找出其中的两条线,使得它们与 x 轴共同构成的容器可以容纳最多的水。 返回容器可以储存的最大水量。 说明: 你不能倾斜容器。 示例 1: 输入:[1,8,6,2,5,4,8,3,7]
输出:49
解释:图中垂直线代表输入数组 [1,8,6,2,5,4,8,3,7]。在此情况下,容器能够容纳水(表示为蓝色部分)的最大值为 49。 示例 2: 输入:height = [1,1]
输出:1 提示: n == height.length 2 <= n <= 10 5 0 <= height[i] <= 10 4 题解 在初始时,左右指针分别指向数组的左右两端,它们可以容纳的水量为 \(min(1,7)∗8=8\) 。 此时我们需要移动一个指针。移动哪一个呢?直觉告诉我们,应该移动对应数字较小的那个指针(即此时的左指针)。这是因为,由于容纳的水量是由 两个指针指向的数字中较小值∗指针之间的距离...
Large Model
2026-01-20
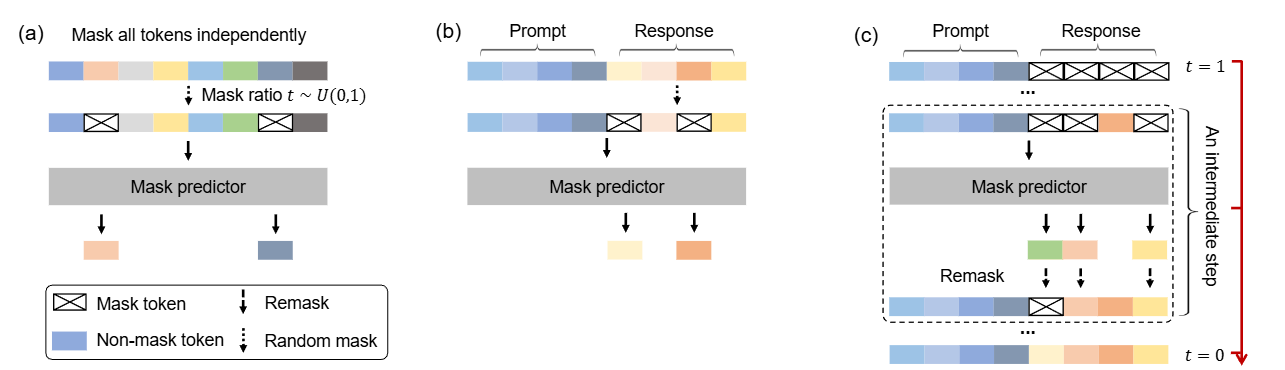
这是一篇尝试改变LLM「范式」的文章:当前主流的LLM架构都是「自回归」的,通俗地理解就是必须「从左到右依次生成」。这篇文章挑战了这一范式,探索扩散模型在 LLMs 上的可行性,通过 随机掩码 - 预测 的逆向思维,让模型学会「全局思考」。 论文: [2502.09992] Large Language Diffusion Models 背景 主流大语言模型架构:自回归模型 (Autoregressive LLMs) 过去几年, 自回归模型(Autoregressive Models, ARMs)一直是大语言模型(LLM)的主流架构。典型的自回归语言模型以Transformer解码器为基础,按照从左到右 的顺序依次预测下一个词元(token)。 形式化地,自回归模型将一个长度为 \(N\) 的文本序列 \(X=(x_1, x_2, ..., x_N)\) 的概率分解为各位置的条件概率连乘积: \[P_{\theta}(x_1, x_2, \dots, x_N) = \prod_{i=1}^{N} P_{\theta}(x_i \mid x_1, x_2, \dots,...
Large Model
2026-01-20

引言 Diffusion模型近年来在图像生成这一连续域任务中取得了显著成果,展现出强大的生成能力。然而,在文本生成这一离散域任务中整体效果仍不尽如人意,未能在该领域引起广泛关注。 去年,一篇研究离散扩散模型在文本生成的文章《Discrete Diffusion Modeling by Estimating the Ratios of the Data Distribution》获得ICML 2024的Best Paper,引发了学术界的广泛兴趣,也激发了新一轮的研究热潮。随后在2025年,越来越多高校和企业也开始积极探索基于Diffusion的文本生成方法。其中,近期备受关注的Block Diffusion也成功入选ICLR oral,进一步推动了该方向的发展。...
Generative Model
2026-01-19

💡 扩散模型:通过加噪的方式去学习原始数据的分布, 从学到的分布中去生成样本 DDPM 关键点: 1. 正向加噪是离散时间马尔可夫链:从 \(x_0\) 逐步加噪得到 \(x_1,x_2,...,x_T\) ;在合适的噪声调度与足够大的 \(T\) 下, \(x_T\) 近似服从 \( N(0,I) \) 的各向同性高斯。 2. 每一步噪声方差 \(β_t\) 满足 \(0<β_t<1\) ,通常随 \(t\) 增大;因此 \(q(x_t|x_{t-1}) \) 的均值缩放系数 \(\sqrt{1-β_t} \) 逐渐减小。 3. 训练通过最大化对数似然的变分下界(ELBO)来学习反向过程 \( p_θ(x_{t-1}|x_t)\) ,并将其参数化为高斯分布(神经网络预测均值/噪声或 score)。 4. 将目标写成 score/DSM 形式时,loss 的权重与对应噪声层的方差尺度(如 \(1-\bar{α}_t\) 或相关量)有关;采样通常是按学习到的反向转移逐步生成(祖先采样),与经典 Langevin MCMC 更新形式不同,但可在 SDE 视角下统一理解。...
Generative Model
2026-01-19
基于文章 《Elucidating the Design Space of Diffusion-Based Generative Models》 来统一扩散模型框架 通用扩散模型框架推导 加噪公式 Flow Matching的一步加噪公式 \[\mathbf{x}_t=(1-t)\mathbf{x}_0+t\varepsilon\] 写成概率分布形式: \[p(\mathbf{x}_t|\mathbf{x}_0)=\mathcal{N}(\mathbf{x}_t;(1-t)\mathbf{x}_0,t^2\mathbf{I})\] Score Matching的一步加噪公式 \[\mathbf{x}_t=\mathbf{x}_0+\sigma_t\varepsilon \] 写成概率分布形式: \[p(\mathbf{x}_t|\mathbf{x}_0)=\mathcal{N}(\mathbf{x}_t;\mathbf{x}_0,\sigma_t^2\mathbf{I})\] DDPM/DDIM的一步加噪公式...
Generative Model
2026-01-11

💡 原本随机采样的DDPM模型中,也隐含了一个确定性的采样过程DDIM,它的连续极限也是一个ODE。 细想上述过程,可以发现不管是“DDPM→DDIM”还是“SDE→ODE”,都是从随机采样模型过渡到确定性模型,而如果我们一开始的目标就是ODE,那么该过程未免显得有点“迂回”了。在本文中,笔者尝试给出ODE扩散模型的直接推导,并揭示了它与雅可比行列式、热传导方程等内容的联系。 Rectified Flow 理论推导 微分方程 像GAN这样的生成模型,它本质上是希望找到一个确定性变换,能将从简单分布(如标准正态分布)采样出来的随机变量,变换为特定数据分布的样本。flow模型也是生成模型之一,它的思路是反过来,先找到一个能将数据分布变换简单分布的可逆变换,再求解相应的逆变换来得到一个生成模型。 ...
Machine Learning
2026-01-11
随机森林 (Random Forests) 是一种利用CART决策树作为基学习器的 Bagging 集成学习算法。随机森林模型的构建过程如下: 数据采样 作为一种 Bagging 集成算法,随机森林同样采用有放回的采样,对于总体训练集 T ,抽样一个子集 T_{sub} 作为训练样本集。除此之外,假设训练集的特征个数为 d ,每次仅选择 k(k<d) 个构建决策树。因此,随机森林除了能够做到样本扰动外,还添加了特征扰动,对于特征的选择个数,推荐值为 k=log_2d 。 树的构建 每次根据采样得到的数据和特征构建一棵决策树。在构建决策树的过程中,会让决策树生长完全而不进行剪枝。构建出的若干棵决策树则组成了最终的随机森林。 随机森林在众多分类算法中表现十分出众,其主要的优点包括: 1. 由于...
Machine Learning
2026-01-11
AdaBoost基本思路 分类问题 Adaboost 是 Boosting 算法中有代表性的一个。原始的 Adaboost 算法用于解决二分类问题,因此对于一个训练集 [公式] 其中 [Math] ,,首先初始化训练集的权重 [公式] 根据每一轮训练集的权重 D_m ,对训练集数据进行抽样得到 T_m ,再根据 T_m 训练得到每一轮的基学习器 h_m 。通过计算可以得出基学习器 h_m 的误差为 e_m [公式] 根据基学习器的误差计算得出该基学习器在最终学习器中的权重系数 [公式] 为什么这样计算弱学习器权重系数?从上式可以看出,如果分类误差率 𝑒_𝑘 越大,则对应的弱分类器权重系数 [Math] 越小。也就是说,误差率小的弱分类器权重系数越大。具体为什么采用这个权重系数公式,见AdaB...
Python
2026-01-11

1. 列表和元组总结 列表和元组都是一个可以放置任意数据类型的有序集合,他们有以下共同点 列表和元组中的元素可以任意,并且都可以嵌套。 列表和元组都支持索引,且都支持负数索引,1表示最后一个元素,2表示倒数第二个元素 列表和元组都支持切片操作 都支持in关键词 都可以使用.index()、.count()、sorted()和enumerate()等方法 两者之间的相互转换,list()和tuple() 但是他们也是有区别 列表是动态的,长度大小不固定,可以随意地增加、删减或者改变元素(mutable) 元组是静态的,长度大小不固定,无法增删改,想要对已有的元组做任何“改变”,就只能开辟一块内存,创建新的元组 2. 列表和元组存储方式的差异 由于列表是动态的;元组是静态的,不可变的。这样的差异...
Python
2026-01-11
生成器 什么是生成器? 通过列表生成式,我们可以直接创建一个列表,但是,受到内存限制,列表容量肯定是有限的,而且创建一个包含100万个元素的列表,不仅占用很大的存储空间,如果我们仅仅需要访问前面几个元素,那后面绝大多数元素占用的空间都白白浪费了。 所以,如果列表元素可以按照某种算法推算出来,那我们是否可以在循环的过程中不断推算出后续的元素呢?这样就不必创建完整的list,从而节省大量的空间,在Python中,这种一边循环一边计算的机制,称为生成器:generator 生成器是一个特殊的程序,可以被用作控制循环的迭代行为,python中生成器是迭代器的一种,使用yield返回值函数,每次调用yield会暂停,而可以使用next()函数和send()函数恢复生成器。 生成器类似于返回值为数组的一...
Machine Learning
2026-01-11

GBDT (Gradient Boosting Decision Tree) 是另一种基于 Boosting 思想的集成算法,除此之外 GBDT 还有很多其他的叫法,例如:GBM (Gradient Boosting Machine),GBRT (Gradient Boosting Regression Tree),MART (Multiple Additive Regression Tree) 等等。GBDT 算法由 3 个主要概念构成:Gradient Boosting (GB),Regression Decision Tree (DT 或 RT) 和 Shrinkage。 0. Decision Tree:CART回归树 首先,GBDT使用的决策树是CART回归树,无论是处理回归问题还...
Python
2026-01-11
概念 可变对象与不可变对象的区别在于对象本身是否可变。 python内置的一些类型中 可变对象:list dict set 不可变对象:tuple string int float bool 举一个例子 [代码] 上面例子很直观地展现了,可变对象是可以直接被改变的,而不可变对象则不可以 地址问题 下面我们来看一下可变对象的内存地址变化 [代码] 我们可以看到,可变对象变化后,地址是没有改变的 如果两个变量同时指向一个地址 1.可变对象 [代码] 我们可以看到,改变a则b也跟着变,因为他们始终指向同一个地址 2.不可变对象 [代码] 我们可以看到,a改变后,它的地址也发生了变化,而b则维持原来的地址,原来地址中的内容也没有发生变化 作为函数参数 1.可变对象 [代码] 我们可以看到,可变对象作...