
11. 盛最多水的容器 题目 给定一个长度为 n 的整数数组 height 。有 n 条垂线,第 i 条线的两个端点是 (i, 0) 和 (i, height[i]) 。 找出其中的两条线,使得它们与 x 轴共同构成的容器可以容纳最多的水。 返回容器可以储存的最大水量。 说明: 你不能倾斜容器。 示例 1: 输入:[1,8,6,2,5,4,8,3,7]
输出:49
解释:图中垂直线代表输入数组 [1,8,6,2,5,4,8,3,7]。在此情况下,容器能够容纳水(表示为蓝色部分)的最大值为 49。 示例 2: 输入:height = [1,1]
输出:1 提示: n == height.length 2 <= n <= 10 5 0 <= height[i] <= 10 4 题解 在初始时,左右指针分别指向数组的左右两端,它们可以容纳的水量为 \(min(1,7)∗8=8\) 。 此时我们需要移动一个指针。移动哪一个呢?直觉告诉我们,应该移动对应数字较小的那个指针(即此时的左指针)。这是因为,由于容纳的水量是由 两个指针指向的数字中较小值∗指针之间的距离...
Large Model
2026-01-23

总览 由于是“图文多模态”,还是要从“图”和“文”的表征方法讲起,然后讲清楚图文表征的融合方法。这里只讲两件事情: 视觉表征 :分为两个部分问题,一是如何合理建模视觉输入特征,二是如何通过预训练手段进行充分学习表征,这两点是基于视觉完成具体算法任务的基础; 视觉与自然语言的对齐(Visul Language Alignment)或融合 :目的是将视觉和自然语言建模到同一表征空间并进行融合,实现自然语言和视觉语义的互通,这点同样离不开预训练这一过程。模态对齐是处理多模态问题的基础,也是现在流行的多模态大模型技术前提。 对于视觉表征,从发展上可以分为卷积神经网络(CNN)和Vision Transformer(VIT)两大脉络,二者分别都有各自的表征、预训练以及多模态对齐的发展过程。而对于VIT线,另有多模态大模型如火如荼的发展,可谓日新月异。 CNN:视觉理解的一代先驱 点击展开 卷积视觉表征模型和预训练...
Large Model
2026-01-23

SigLIP 概述 CLIP自提出以来在zero-shot分类、跨模态搜索、多模态对齐等多个领域得到广泛应用。得益于其令人惊叹的能力,激起了研究者广泛的关注和优化。 目前对CLIP的优化主要可以分为两大类: 其一是如何降低CLIP的训练成本; 其二是如何提升CLIP的performance。 对于第一类优化任务的常见思路有3种。 优化训练架构,如 LiT 通过freezen image encoder,单独训练text encoder来进行text 和image的对齐来加速训练; 减少训练token,如 FLIP 通过引入视觉mask,通过只计算非mask区域的视觉表征来实现加速(MAE中的思路) 优化目标函数,如 CatLIP 将caption转为class label,用分类任务来代替对比学习任务来实现加速。 对于第二类提升CLIP的performance最常用和有效的手段就是数据治理,即构建高质量、大规模、高多样性的图文数据,典型的工作如:DFN。 SigLIP这篇paper 提出用sigmoid...
Large Model
2026-01-22

BLIP 论文名称 :BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation (ICML 2022) 论文地址: https://arxiv.org/pdf/2201.12086.pdf 代码地址: https://github.com/salesforce/BLIP 官方解读博客: https://blog.salesforceairesearch.com/blip-bootstrapping-language-image-pretraining/ 背景和动机 视觉语言训练 (Vision-Language Pre-training, VLP) 最近在各种多模态下游任务上取得了巨大的成功。然而,现有方法有两个主要限制: 模型层面: 大多数现有的预训练模型仅在基于理解的任务或者基于生成的任务方面表现出色,很少有可以兼顾的模型。比如,基于编码器的模型,像 CLIP,ALBEF 不能直接转移到文本生成任务...
Large Model
2026-01-22

CLIP算法原理 CLIP 不预先定义图像和文本标签类别,直接利用从互联网爬取的 400 million 个image-text pair 进行图文匹配任务的训练,并将其成功迁移应用于30个现存的计算机视觉分类。简单的说,CLIP 无需利用 ImageNet 的数据和标签进行训练,就可以达到 ResNet50 在 ImageNet数据集上有监督训练的结果,所以叫做 Zero-shot。 CLIP(contrastive language-image pre-training)主要的贡献就是 利用无监督的文本信息,作为监督信号来学习视觉特征 。 CLIP 作者先是回顾了并总结了和上述相关的两条表征学习路线: 构建image和text的联系,比如利用已有的image-text pair数据集,从text中学习image的表征; 获取更多的数据(不要求高质量,也不要求full...
Computer Vision
2026-01-21
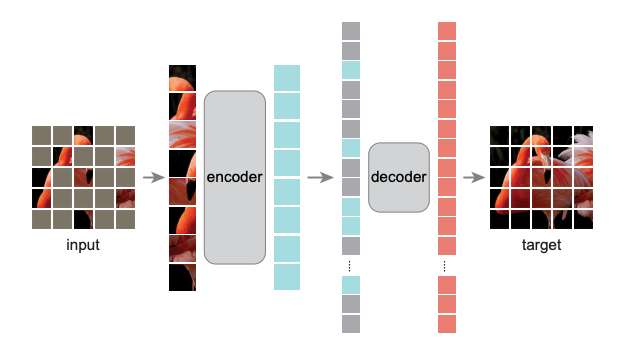
导言 自监督学习(Self-Supervised Learning)能利用大量无标注的数据进行表征学习,然后在特定下游任务上对参数进行微调。通过这样的方式,能够在较少有标注数据上取得优于有监督学习方法的精度。近年来,自监督学习受到了越来越多的关注,如Yann Lecun也在 AAAI 上讲 Self-Supervised Learning 是未来的大势所趋。在CV领域涌现了如SwAV、MOCO、DINO、MoBY等一系列工作。MAE是kaiming继MOCO之后在自监督学习领域的又一力作。首先,本文会对MAE进行解读,然后基于EasyCV库的精度复现过程及其中遇到的一些问题作出解答。 概述 MAE的做法很简单:随机mask掉图片中的一些patch,然后通过模型去重建这些丢失的区域。包括两个核心的设计:1.非对称编码-解码结构 2.用较高的掩码率(75%)。通过这两个设计MAE在预训练过程中可以取得3倍以上的训练速度和更高的精度,如ViT-Huge能够通过ImageNet-1K数据上取得87.8%的准确率。 模型拆解...
Computer Vision
2026-01-21
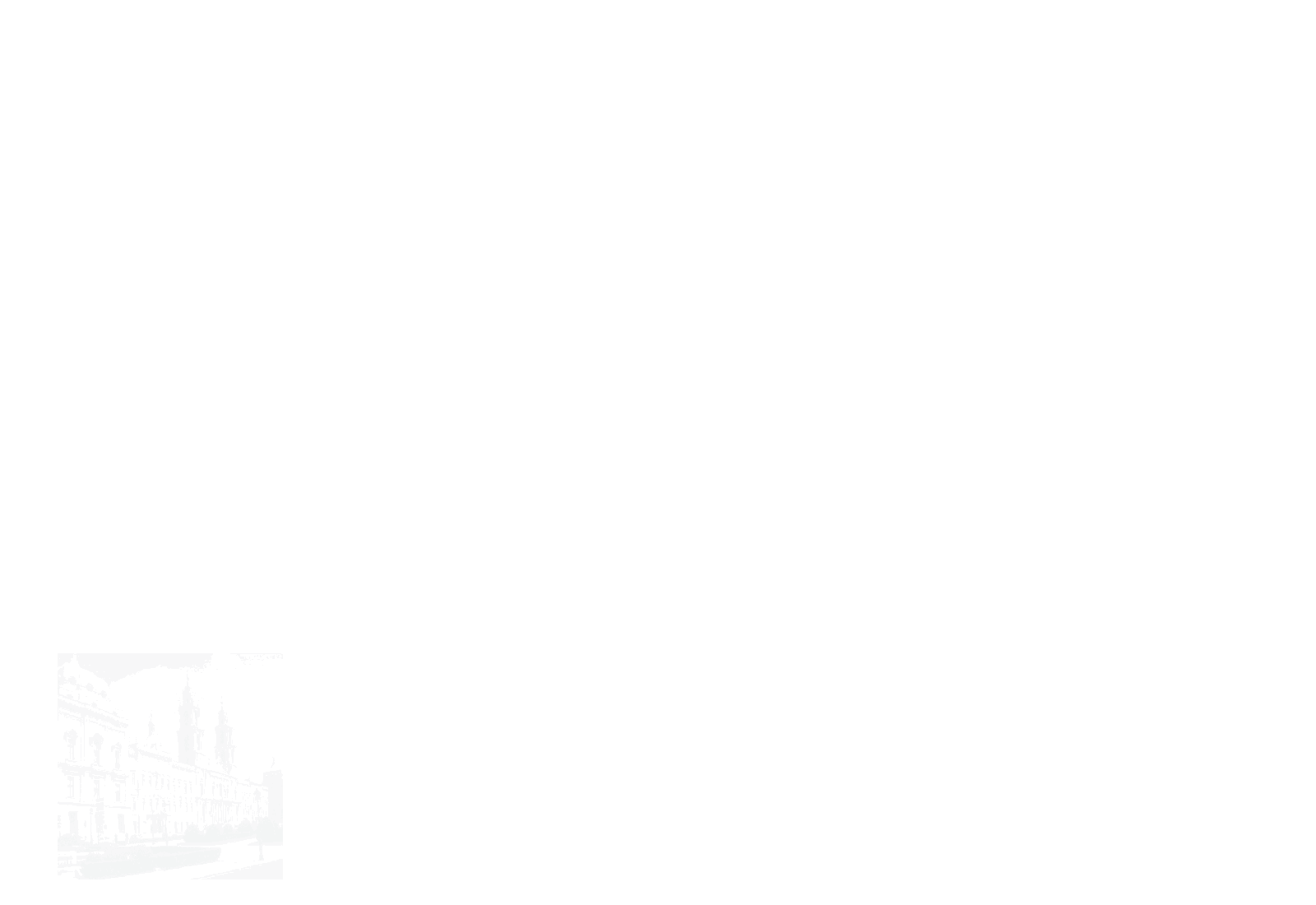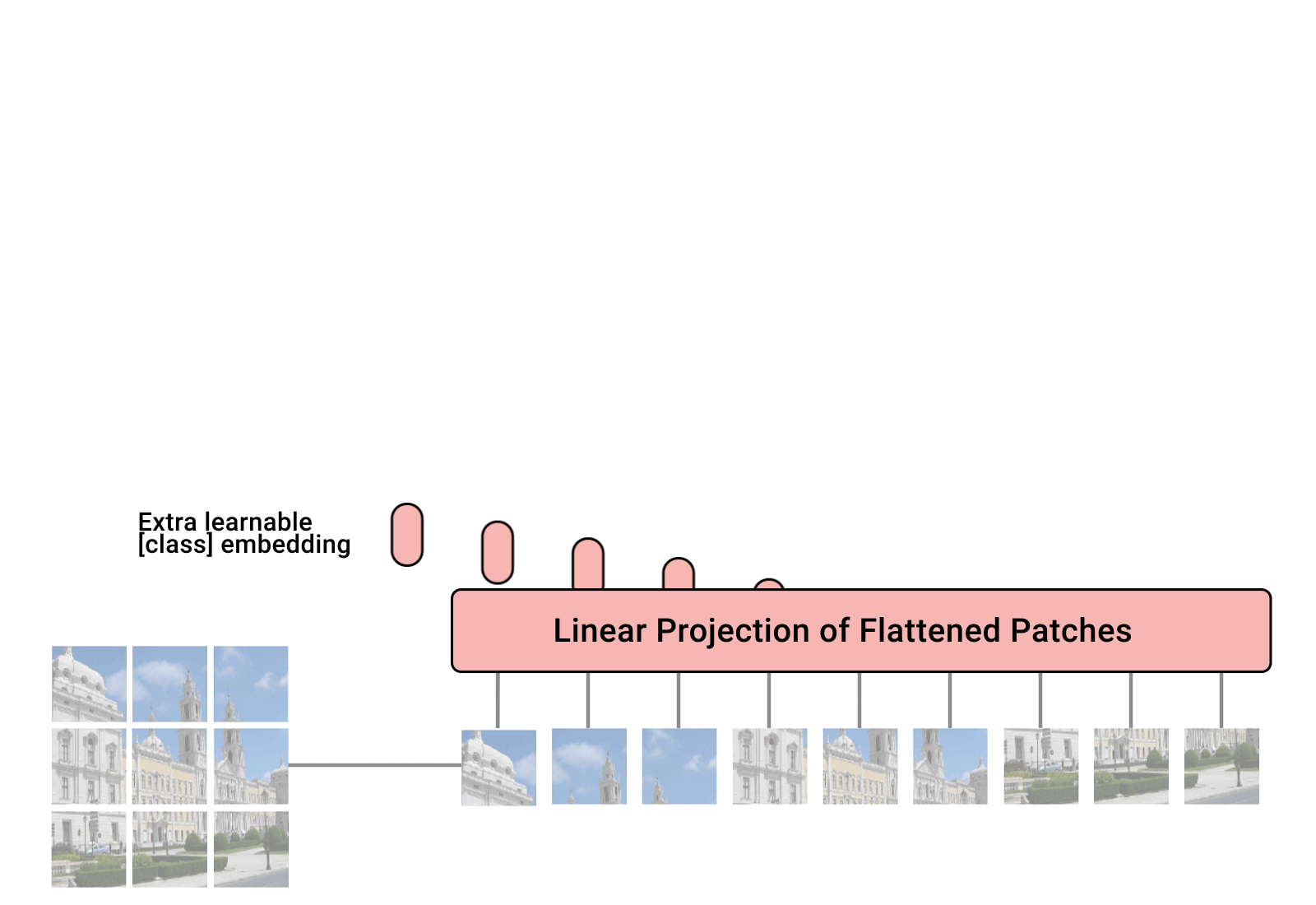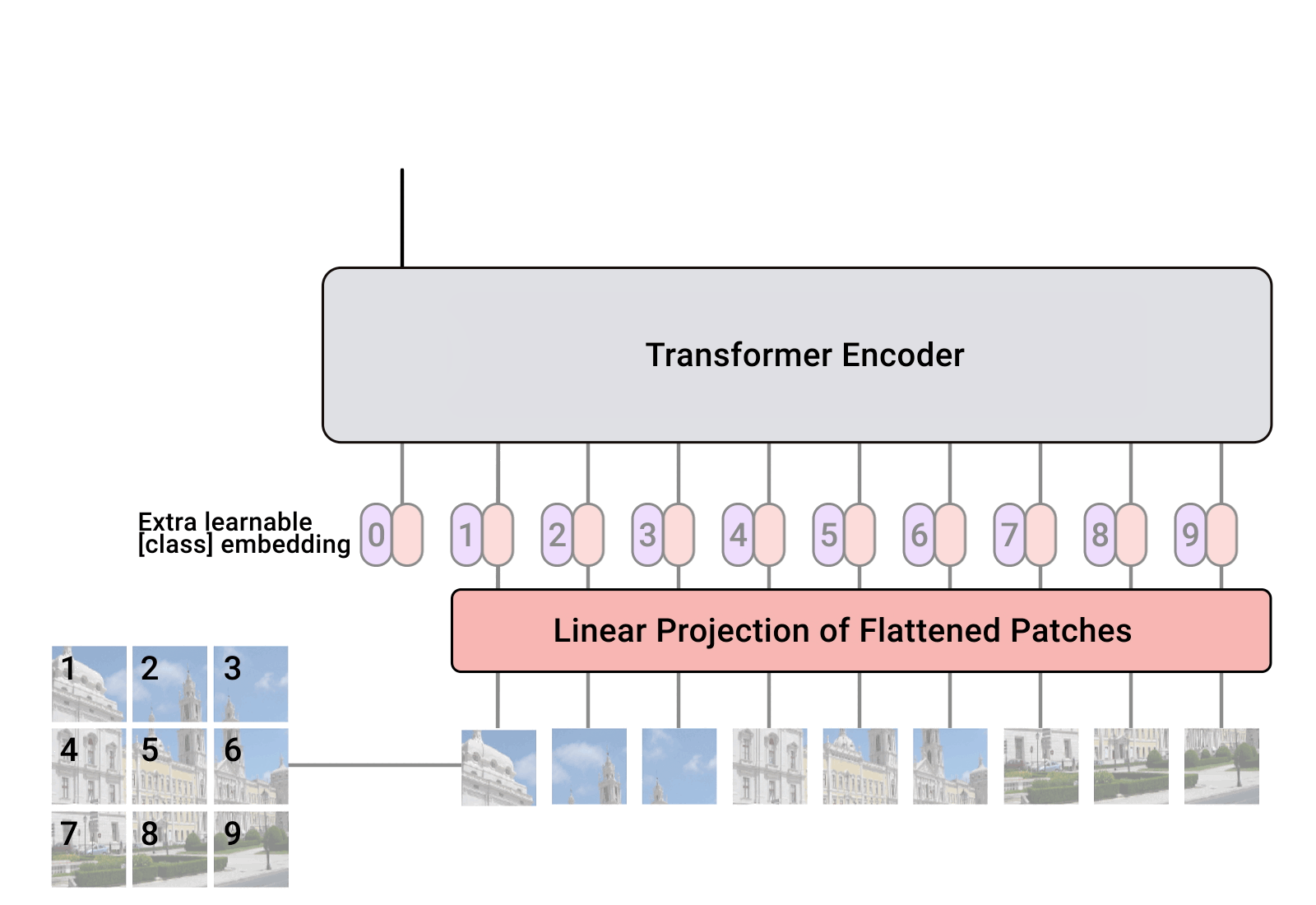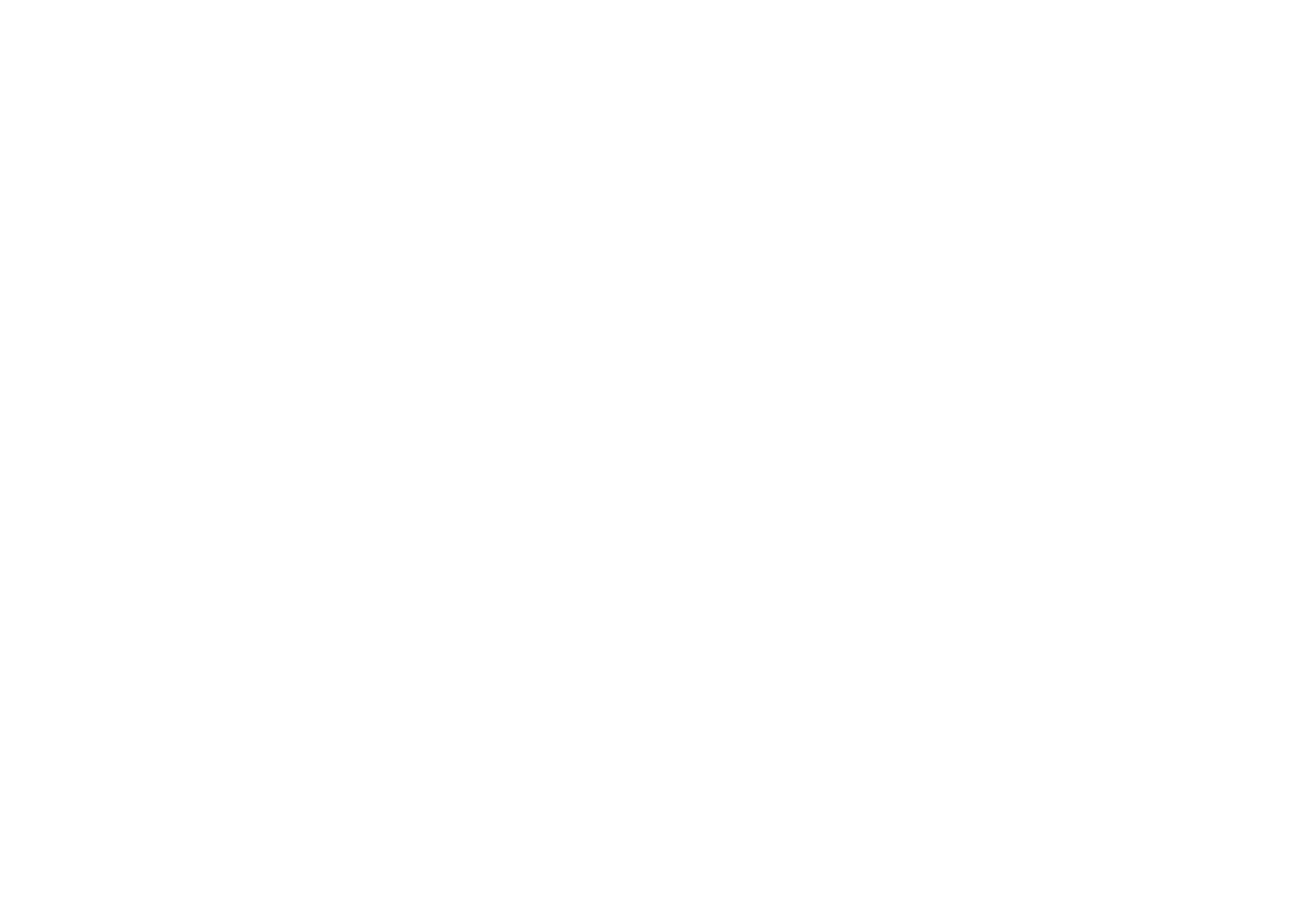
概述 在计算机视觉领域(CV),对视觉特征的理解CNN是长期处于主导地位的。而在NLP领域,Transformer框架的巨大成功,也激发了不少研究者探索将Transformer用于计算机视觉任务。ViT(Vision Transformer)的出现标志着在CV领域Transformer架构迈出了重要的一步。尤其在当前结合LLM的多模态探索上(MM-LLM),都是以LLM大语言模型为骨干架构的模型,多种模态的信息需要先做token化处理,再输入到LLM模型。ViT天然具有序列化特征的建模能力,自然在MM-LLM探索中大放异彩~ ViT在多模态模型中的角色类似于自然语言建模中的Tokenizer组件,对图像进行视觉特征编码,产出图像的序列特征。只不过ViT的编码过程本身也是采用了Transformer的模型结构。 本文主要结合几篇paper和源码讲讲ViT和针对ViT的一些优化方法~ ViT(Vision Transformer)...
Computer Vision
2026-01-21
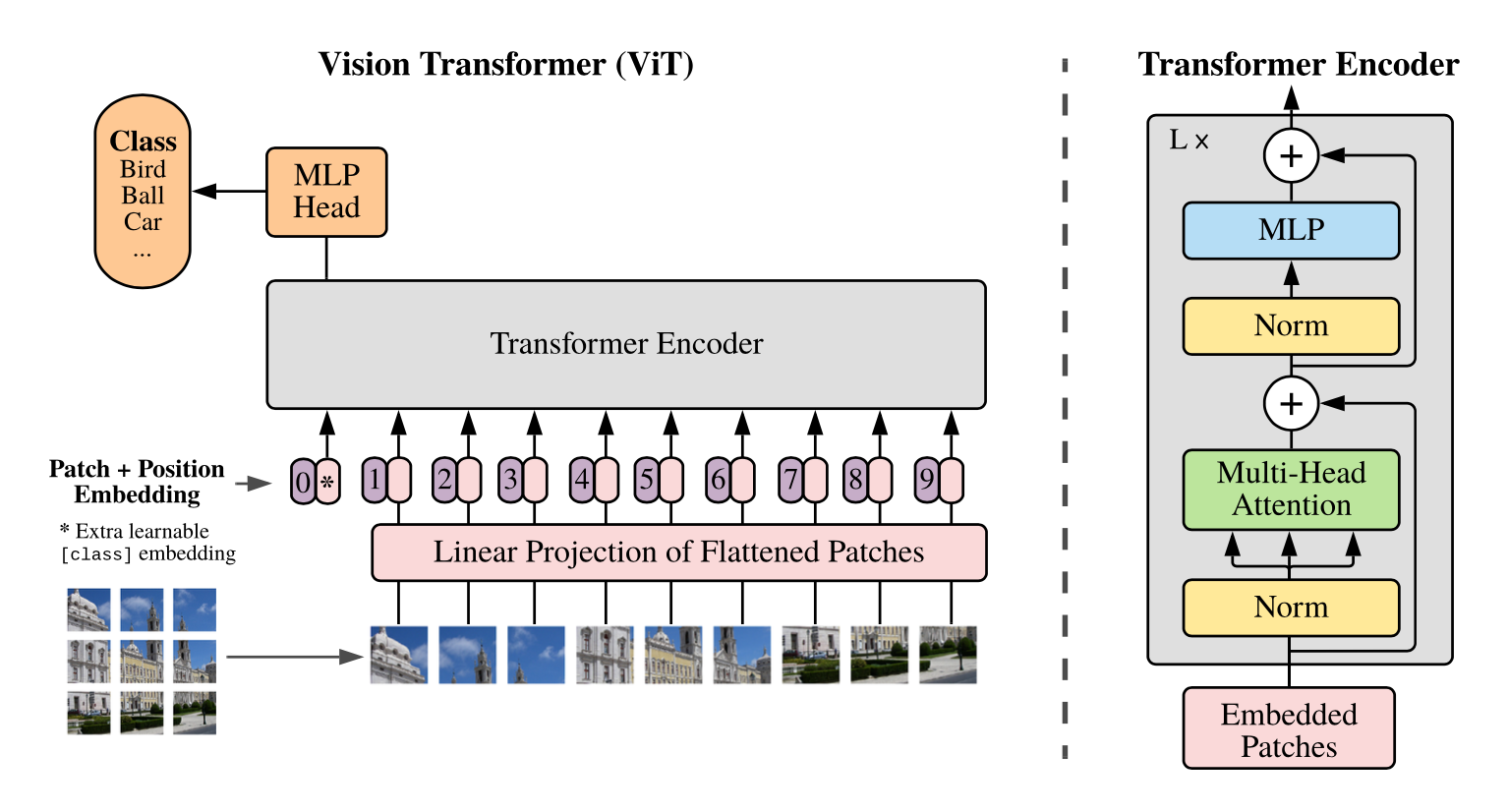
ViT(vision transformer)是Google在2020年提出的直接将transformer应用在图像分类的模型,后面很多的工作都是基于ViT进行改进的。ViT的思路很简单:直接把图像分成固定大小的patchs,然后通过线性变换得到patch embedding,这就类比NLP的words和word embedding,由于transformer的输入就是a sequence of token embeddings,所以将图像的patch embeddings送入transformer后就能够进行特征提取从而分类了。ViT模型原理如下图所示,其实ViT模型只是用了transformer的Encoder来提取特征(原始的transformer还有decoder部分,用于实现sequence to sequence,比如机器翻译)。下面将分别对各个部分做详细的介绍。 Patch Embedding 对于ViT来说,首先要将原始的2-D图像转换成一系列1-D的patch embeddings,这就好似NLP中的word embedding。输入的2-D图像记为 \(x\in...
Generative Model
2026-01-18

2022年中旬,以扩散模型为核心的图像生成模型将AI绘画带入了大众的视野。实际上,在更早的一年之前,就有了一个能根据文字生成高清图片的模型——VQGAN。VQGAN不仅本身具有强大的图像生成能力,更是传承了前作VQVAE把图像压缩成离散编码的思想,推广了「先压缩,再生成」的两阶段图像生成思路,启发了无数后续工作。 VQGAN 核心思想 VQGAN的论文名为 Taming Transformers for High-Resolution Image Synthesis,直译过来是「驯服Transformer模型以实现高清图像合成」。可以看出,该方法是在用Transformer生成图像。可是,为什么这个模型叫做VQGAN,是一个GAN呢?这是因为,VQGAN使用了两阶段的图像生成方法: 训练时,先训练一个图像压缩模型(包括编码器和解码器两个子模型),再训练一个生成压缩图像的模型。 生成时, 先用第二个模型生成出一个压缩图像,再用第一个模型复原成真实图像 。 其中,第一个图像压缩模型叫做VQGAN,第二个压缩图像生成模型是一个基于Transformer的模型。...
Generative Model
2026-01-18
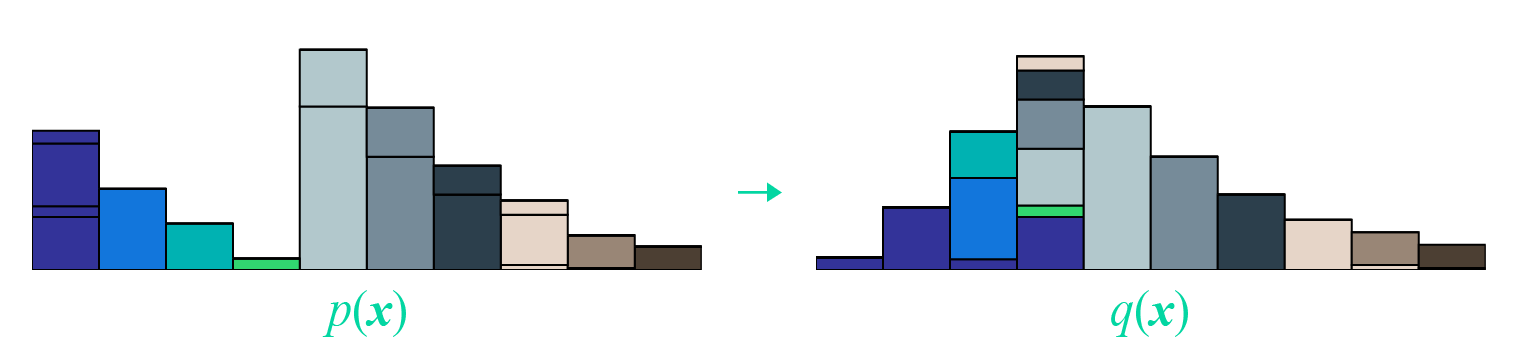
本文受启发于著名的国外博文 《Wasserstein GAN and the Kantorovich-Rubinstein Duality》 ,内容跟它大体上相同,但是删除了一些冗余的部分,对不够充分或者含糊不清的地方作了补充。 Wasserstein距离 显然,整篇文章必然围绕着Wasserstein距离( \(\mathcal{W}\) 距离)来展开。假设我们有了两个概率分布 \(p(x),q(x)\) ,那么Wasserstein距离的定义为 \[\mathcal{W}[p,q]=\inf_{\gamma\in \Pi[p,q]} \iint \gamma(\boldsymbol{x},\boldsymbol{y}) d(\boldsymbol{x},\boldsymbol{y}) d\boldsymbol{x}d\boldsymbol{y}\] 事实上,这也算是最优传输理论中最核心的定义了。 成本函数 首先 \(d(x,y)\) ,它不一定是距离,其准确含义应该是一个成本函数,代表着从 \(x\) 运输到 \(y\) 的成本。常用的 \(d\) 是基于 \(l\)...

简介 生成对抗网络 ( Generative Adversarial Network, GAN ) 是由 Goodfellow 于 2014 年提出的一种对抗网络。这个网络框架包含两个部分,一个生成模型 (generative model) 和一个判别模型 (discriminative model)。其中,生成模型可以理解为一个伪造者,试图通过构造假的数据骗过判别模型的甄别;判别模型可以理解为一个警察,尽可能甄别数据是来自于真实样本还是伪造者构造的假数据。两个模型都通过不断的学习提高自己的能力,即生成模型希望生成更真的假数据骗过判别模型,而判别模型希望能学习如何更准确的识别生成模型的假数据。 网络框架 GAN 由两部分构成,一个 生成器 ( Generator ) 和一个 判别器 ( Discriminator )。对于生成器,我们需要学习关于数据 \(x\) 的一个分布 \(p_g\) ,首先定义一个输入数据的先验分布 \(p_z(z)\) ,其次定义一个映射 \(G \left(\boldsymbol{z}; \theta_g\right): \boldsymbol{z}...
Computer Vision
2026-01-11
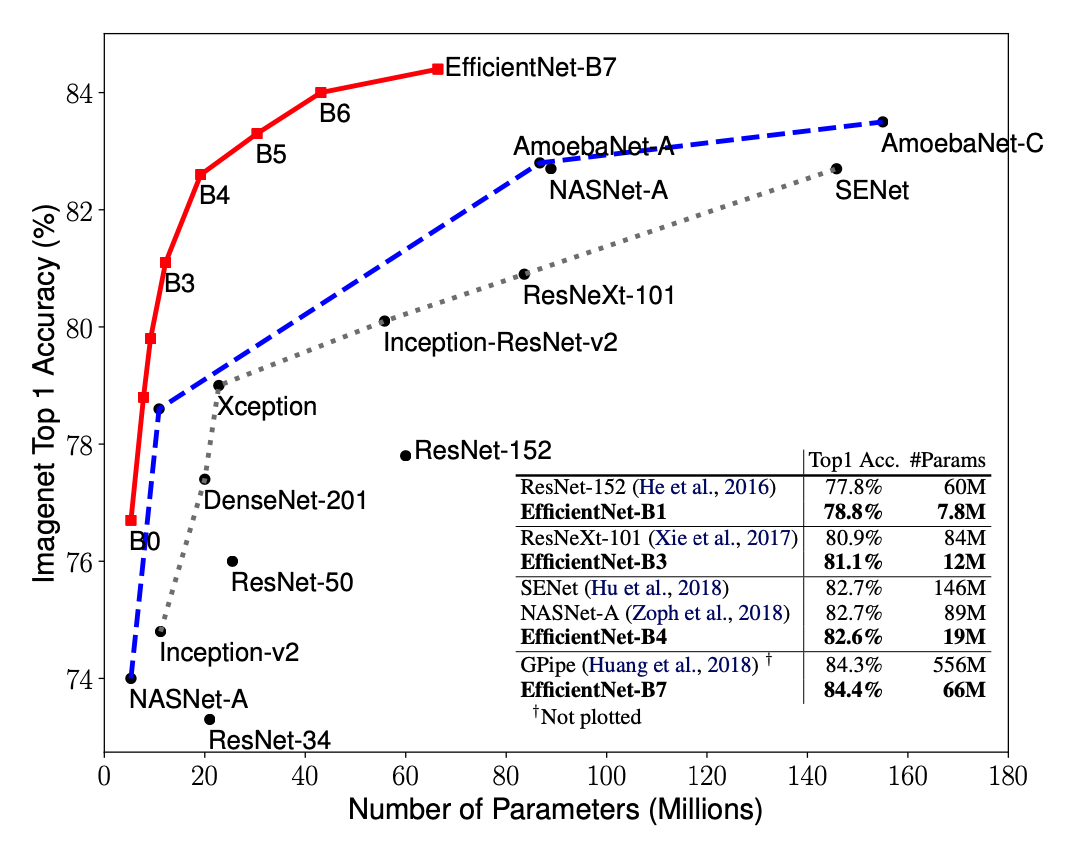
简介 EfficientNet源自Google Brain的论文EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. 从标题也可以看出,这篇论文最主要的创新点是Model Scaling. 论文提出了compound scaling,混合缩放,把网络缩放的三种方式:深度、宽度、分辨率,组合起来按照一定规则缩放,从而提高网络的效果。EfficientNet在网络变大时效果提升明显,把精度上限进一步提升,成为了当前最强网络。EfficientNetB7在ImageNet上获得了最先进的 84.4%的top1精度 和 97.1%的top5精度,比之前最好的卷积网络(GPipe, Top1: 84.3%, ...