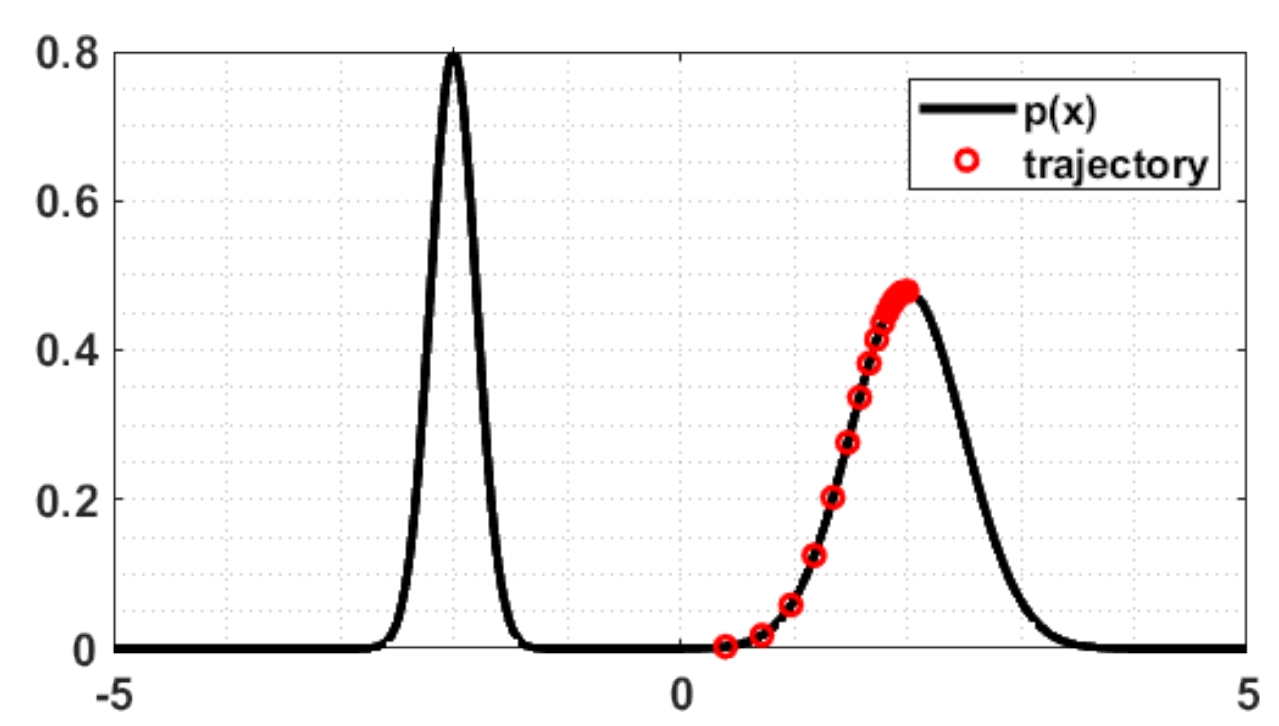
朗之万动力学(Langevin Dynamics)是扩散模型和score matching方法中的采样过程,是文本生成图像中的一个重要步骤。想要洞悉文生图的基本原理,朗之万动力学是绕不开的话题。 朗之万动力学原理简介 本文的主要内容是基于以下教程: Tutorial on Diffusion Models for Imaging and Vision 此教程写的非常好,非常推荐大家学习。教程的语言风格也很亲切,时不时地蹦出诸如“这是地球人能想出来的公式?”这样的话,为你枯燥的学习过程增添些许趣味。 朗之万动力学(Langevin Dynamics)是扩散模型和score matching方法中的采样过程,是文本生成图像中的一个重要步骤。想要洞悉文生图的基本原理,朗之万动力学是绕不开的话题。 给定一个已知的概率分布 \(p(x)\) ,我们的目标是采样出概率密度更大的那些样本。解决这个问题有多种方法,比如生成伪随机均匀分布,然后用概率分布变换的方法;或者用马尔可夫链蒙特卡洛方法(MCMC)。而朗之万动力学给出的方法是这样: 随机选取空间中一个点(这是很简单的,采用高斯生成与 \(x\)...
Computer Vision
2026-02-26

Introduction Inception 在最初的版本 Inception/GoogleNet,其核心思想是利用多尺寸卷积核去观察输入数据。举个栗子,我们看某个景象由于远近不同,同一个物体的大小也会有所不同,那么不同尺度的卷积核观察的特征就会有这样的效果。于是就有了如下的网络结构图: 于是我们的网络就变胖了,通过增加网络的宽度,提高了对于不同尺度的适应程度。但这样的话,计算量有点大了。 Point-wise Conv 为了减少在上面结构的参数量并降低计算量,于是在 Inception V1 的基础版本上加上了 \(1\times 1\) 卷积核,这就形成了 Inception V1 的最终网络结构,如下图。 这个 \(1\times1 \) 卷积就是 Pointwise Convolution ,简称 PW。利用它的目的主要是为了减少维度,还用于引入更多的非线性。 我们来简单计算下:假定上一层输出的 feature map 维度为 \(100\times 100 \times 128\) ,经过256个大小为 \(5\times5 \) 的卷积后,输出的 feature map...
Large Model
2026-01-23

SigLIP 概述 CLIP自提出以来在zero-shot分类、跨模态搜索、多模态对齐等多个领域得到广泛应用。得益于其令人惊叹的能力,激起了研究者广泛的关注和优化。 目前对CLIP的优化主要可以分为两大类: 其一是如何降低CLIP的训练成本; 其二是如何提升CLIP的performance。 对于第一类优化任务的常见思路有3种。 优化训练架构,如 LiT 通过freezen image encoder,单独训练text encoder来进行text 和image的对齐来加速训练; 减少训练token,如 FLIP 通过引入视觉mask,通过只计算非mask区域的视觉表征来实现加速(MAE中的思路) 优化目标函数,如 CatLIP 将caption转为class label,用分类任务来代替对比学习任务来实现加速。 对于第二类提升CLIP的performance最常用和有效的手段就是数据治理,即构建高质量、大规模、高多样性的图文数据,典型的工作如:DFN。 SigLIP这篇paper 提出用sigmoid...
Large Model
2026-01-22

BLIP 论文名称 :BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation (ICML 2022) 论文地址: https://arxiv.org/pdf/2201.12086.pdf 代码地址: https://github.com/salesforce/BLIP 官方解读博客: https://blog.salesforceairesearch.com/blip-bootstrapping-language-image-pretraining/ 背景和动机 视觉语言训练 (Vision-Language Pre-training, VLP) 最近在各种多模态下游任务上取得了巨大的成功。然而,现有方法有两个主要限制: 模型层面: 大多数现有的预训练模型仅在基于理解的任务或者基于生成的任务方面表现出色,很少有可以兼顾的模型。比如,基于编码器的模型,像 CLIP,ALBEF 不能直接转移到文本生成任务...
Large Model
2026-01-22

CLIP算法原理 CLIP 不预先定义图像和文本标签类别,直接利用从互联网爬取的 400 million 个image-text pair 进行图文匹配任务的训练,并将其成功迁移应用于30个现存的计算机视觉分类。简单的说,CLIP 无需利用 ImageNet 的数据和标签进行训练,就可以达到 ResNet50 在 ImageNet数据集上有监督训练的结果,所以叫做 Zero-shot。 CLIP(contrastive language-image pre-training)主要的贡献就是 利用无监督的文本信息,作为监督信号来学习视觉特征 。 CLIP 作者先是回顾了并总结了和上述相关的两条表征学习路线: 构建image和text的联系,比如利用已有的image-text pair数据集,从text中学习image的表征; 获取更多的数据(不要求高质量,也不要求full...