
11. 盛最多水的容器 题目 给定一个长度为 n 的整数数组 height 。有 n 条垂线,第 i 条线的两个端点是 (i, 0) 和 (i, height[i]) 。 找出其中的两条线,使得它们与 x 轴共同构成的容器可以容纳最多的水。 返回容器可以储存的最大水量。 说明: 你不能倾斜容器。 示例 1: 输入:[1,8,6,2,5,4,8,3,7]
输出:49
解释:图中垂直线代表输入数组 [1,8,6,2,5,4,8,3,7]。在此情况下,容器能够容纳水(表示为蓝色部分)的最大值为 49。 示例 2: 输入:height = [1,1]
输出:1 提示: n == height.length 2 <= n <= 10 5 0 <= height[i] <= 10 4 题解 在初始时,左右指针分别指向数组的左右两端,它们可以容纳的水量为 \(min(1,7)∗8=8\) 。 此时我们需要移动一个指针。移动哪一个呢?直觉告诉我们,应该移动对应数字较小的那个指针(即此时的左指针)。这是因为,由于容纳的水量是由 两个指针指向的数字中较小值∗指针之间的距离...
Generative Model
2026-01-19
基于文章 《Elucidating the Design Space of Diffusion-Based Generative Models》 来统一扩散模型框架 通用扩散模型框架推导 加噪公式 Flow Matching的一步加噪公式 \[\mathbf{x}_t=(1-t)\mathbf{x}_0+t\varepsilon\] 写成概率分布形式: \[p(\mathbf{x}_t|\mathbf{x}_0)=\mathcal{N}(\mathbf{x}_t;(1-t)\mathbf{x}_0,t^2\mathbf{I})\] Score Matching的一步加噪公式 \[\mathbf{x}_t=\mathbf{x}_0+\sigma_t\varepsilon \] 写成概率分布形式: \[p(\mathbf{x}_t|\mathbf{x}_0)=\mathcal{N}(\mathbf{x}_t;\mathbf{x}_0,\sigma_t^2\mathbf{I})\] DDPM/DDIM的一步加噪公式...
Generative Model
2026-01-18
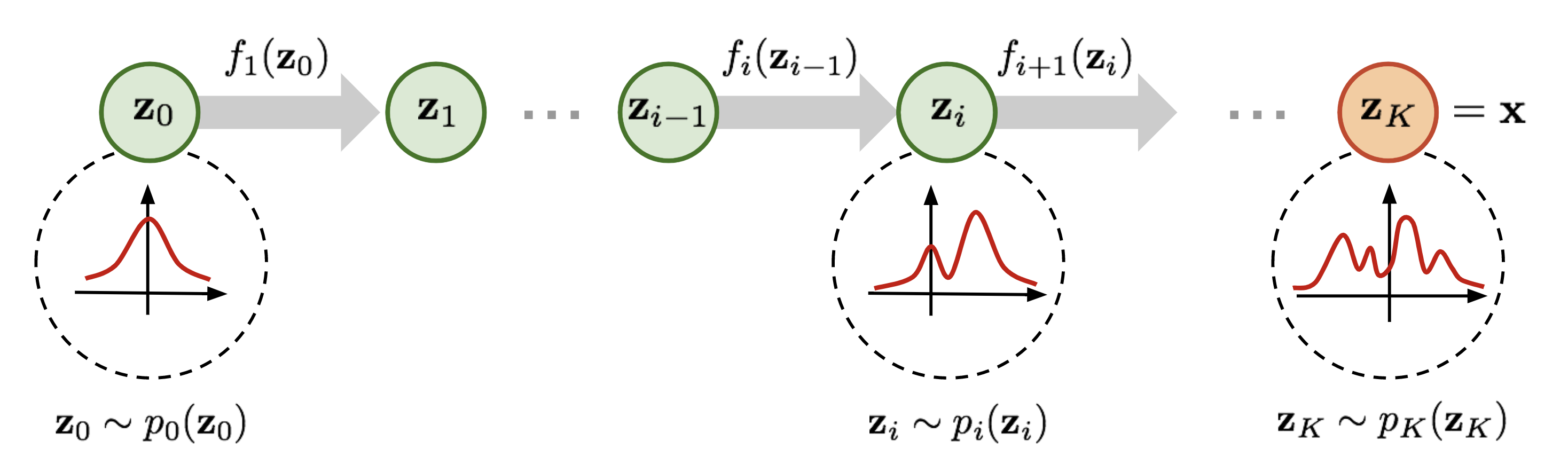
Normalizing flow(标准化流)是一类对概率分布进行建模的工具,它能完成简单的概率分布(例如高斯分布)和任意复杂分布之间的相互转换,经常被用于 data generation、density estimation、inpainting 等任务中,例如 Stability AI 提出的 Stable Diffusion 3 中用到的 rectified flow 就是 normalizing flow 的变体之一。 为了便于理解,在正式开始介绍之前先简要说明一下 normalizing flow 的做法。如上图所示,为了将一个高斯分布 \(z_0\) 转换为一个复杂的分布 \(z_K\) ,normalizing flow 会对初始的分布 \(z_0\) 进行多次可逆的变换,将其逐渐转换为 \(z_K\) 。由于每一次变换都是可逆的,从 \(z_K\) 出发也能得到高斯分布 \(z_0\) 。这样,我们就实现了复杂分布与高斯分布之间的互相转换,从而能从简单的高斯分布建立任意复杂分布。 对 diffusion models 比较熟悉的读者可能已经发现了,这个过程和...
Generative Model
2026-01-11

背景 本文主要是《NICE: Nonlinear Independent Components Estimation》一文的介绍和实现。这篇文章也是glow这个模型的基础文章之一,可以说它就是glow的奠基石。 艰难的分布 众所周知,目前主流的生成模型包括VAE和GAN,但事实上除了这两个之外,还有基于flow的模型(flow可以直接翻译为“流”,它的概念我们后面再介绍)。事实上flow的历史和VAE、GAN它们一样悠久,但是flow却鲜为人知。在我看来,大概原因是flow找不到像GAN一样的诸如“造假者鉴别者”的直观解释吧,因为flow整体偏数学化,加上早期效果没有特别好但计算量又特别大,所以很难让人提起兴趣来。不过现在看来,OpenAI的这个好得让人惊叹的、基于flow的glow模型,估...
Generative Model
2026-01-11

💡 原本随机采样的DDPM模型中,也隐含了一个确定性的采样过程DDIM,它的连续极限也是一个ODE。 细想上述过程,可以发现不管是“DDPM→DDIM”还是“SDE→ODE”,都是从随机采样模型过渡到确定性模型,而如果我们一开始的目标就是ODE,那么该过程未免显得有点“迂回”了。在本文中,笔者尝试给出ODE扩散模型的直接推导,并揭示了它与雅可比行列式、热传导方程等内容的联系。 Rectified Flow 理论推导 微分方程 像GAN这样的生成模型,它本质上是希望找到一个确定性变换,能将从简单分布(如标准正态分布)采样出来的随机变量,变换为特定数据分布的样本。flow模型也是生成模型之一,它的思路是反过来,先找到一个能将数据分布变换简单分布的可逆变换,再求解相应的逆变换来得到一个生成模型。 ...
Machine Learning
2026-01-11
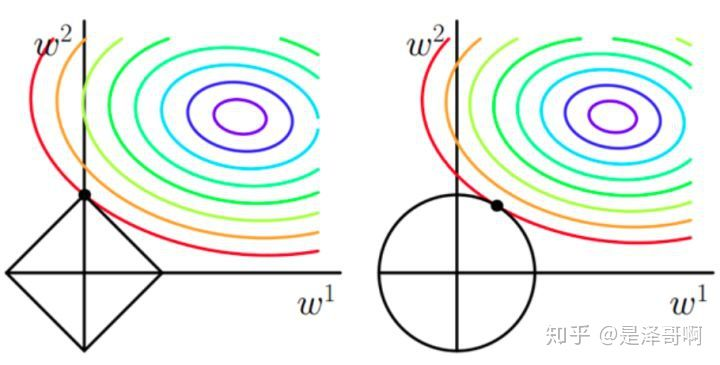
正则化 正则化是一个通用的算法和思想,所以会产生过拟合现象的算法都可以使用正则化来避免过拟合。 在经验风险最小化的基础上(也就是训练误差最小化),尽可能采用简单的模型,可以有效提高泛化预测精度。如果模型过于复杂,变量值稍微有点变动,就会引起预测精度问题。正则化之所以有效,就是因为其降低了特征的权重,使得模型更为简单。 正则化一般会采用 L1 范式或者 L2 范式,其形式分别为 [Math] 和 [Math] 。 L1正则化 LASSO 回归,相当于为模型添加了这样一个先验知识: w 服从零均值拉普拉斯分布。 首先看看拉普拉斯分布长什么样子: [公式] 由于引入了先验知识,所以似然函数这样写: [公式] 取 log 再取负,得到目标函数: [公式] 等价于原始损失函数的后面加上了 L1 正则,...
Machine Learning
2026-01-11
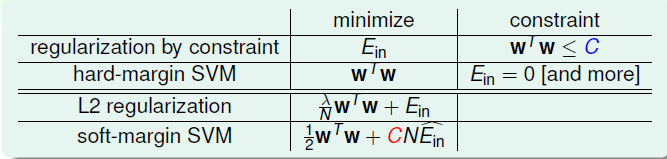
Kernel Logistic Regression 介绍如何将Kernel Trick引入到Logistic Regression,以及LR与SVM的结合 SVM与正则化 首先回顾SoftMargin SVM的原始问题: [公式] 其中 ξ_n 是训练数据违反边界的多少,没有违反的话, ξ_n=0 ,反之 ξ_n0 ,换句话说,目标函数的第二项就可以表示模型的损失。现在换一种方式来写,将二者结合起来: ξ_n=max(1−y_n(w^Tz^n+b),0) ,这一个等式就代表了上面的约束条件,这样上述问题,就与下面的无约束问题等价 [公式] 这种形式与之前的L2 正则项很类似: [公式] 在L2中,通过最小化 E_{in} 的同时控制 w 的大小,防止模型过度复杂。从正则化的角度来看的话,S...
Machine Learning
2026-01-11
EM算法也称期望最大化(ExpectationMaximum,简称EM)算法,它是一个基础算法,是很多机器学习领域算法的基础,比如隐式马尔科夫算法(HMM), LDA主题模型的变分推断等等。本文就对EM算法的原理做一个总结。 EM算法要解决的问题 我们经常会从样本观察数据中,找出样本的模型参数。 最常用的方法就是极大化模型分布的对数似然函数。 但是在一些情况下,我们得到的观察数据有未观察到的隐含数据,此时我们未知的有隐含数据和模型参数,因而无法直接用极大化对数似然函数得到模型分布的参数。怎么办呢?这就是EM算法可以派上用场的地方了。 EM算法解决这个的思路是使用启发式的迭代方法,既然我们无法直接求出模型分布参数,那么我们可以先猜想隐含数据(EM算法的E步),接着基于观察数据和猜测的隐含数据一...
Machine Learning
2026-01-11
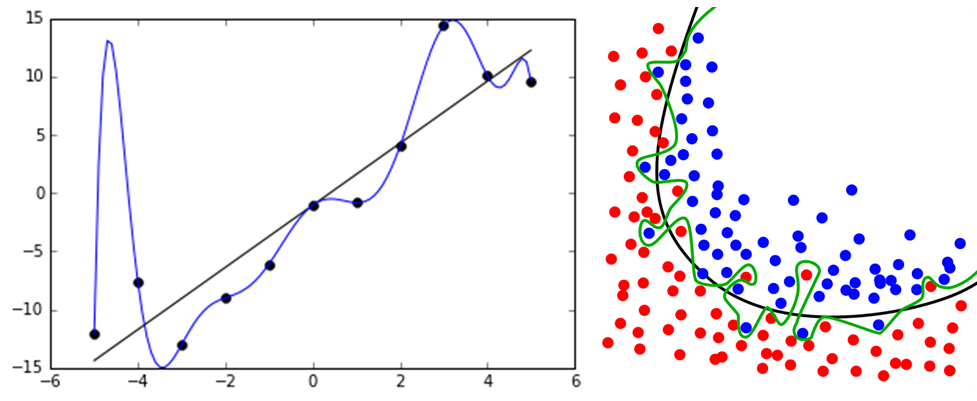
是什么 过拟合(overfitting)是指在模型参数拟合过程中的问题,由于训练数据包含抽样误差,训练时,复杂的模型将抽样误差也考虑在内,将抽样误差也进行了很好的拟合。 具体表现就是最终模型在训练集上效果好;在测试集上效果差。模型泛化能力弱。 为什么 为什么要解决过拟合现象?这是因为我们拟合的模型一般是用来预测未知的结果(不在训练集内),过拟合虽然在训练集上效果好,但是在实际使用时(测试集)效果差。同时,在很多问题上,我们无法穷尽所有状态,不可能将所有情况都包含在训练集上。所以,必须要解决过拟合问题。 为什么在机器学习中比较常见?这是因为机器学习算法为了满足尽可能复杂的任务,其模型的拟合能力一般远远高于问题复杂度,也就是说,机器学习算法有「拟合出正确规则的前提下,进一步拟合噪声」的能力。 而...
Machine Learning
2026-01-11
随机森林 (Random Forests) 是一种利用CART决策树作为基学习器的 Bagging 集成学习算法。随机森林模型的构建过程如下: 数据采样 作为一种 Bagging 集成算法,随机森林同样采用有放回的采样,对于总体训练集 T ,抽样一个子集 T_{sub} 作为训练样本集。除此之外,假设训练集的特征个数为 d ,每次仅选择 k(k<d) 个构建决策树。因此,随机森林除了能够做到样本扰动外,还添加了特征扰动,对于特征的选择个数,推荐值为 k=log_2d 。 树的构建 每次根据采样得到的数据和特征构建一棵决策树。在构建决策树的过程中,会让决策树生长完全而不进行剪枝。构建出的若干棵决策树则组成了最终的随机森林。 随机森林在众多分类算法中表现十分出众,其主要的优点包括: 1. 由于...
Machine Learning
2026-01-11
AdaBoost基本思路 分类问题 Adaboost 是 Boosting 算法中有代表性的一个。原始的 Adaboost 算法用于解决二分类问题,因此对于一个训练集 [公式] 其中 [Math] ,,首先初始化训练集的权重 [公式] 根据每一轮训练集的权重 D_m ,对训练集数据进行抽样得到 T_m ,再根据 T_m 训练得到每一轮的基学习器 h_m 。通过计算可以得出基学习器 h_m 的误差为 e_m [公式] 根据基学习器的误差计算得出该基学习器在最终学习器中的权重系数 [公式] 为什么这样计算弱学习器权重系数?从上式可以看出,如果分类误差率 𝑒_𝑘 越大,则对应的弱分类器权重系数 [Math] 越小。也就是说,误差率小的弱分类器权重系数越大。具体为什么采用这个权重系数公式,见AdaB...
Machine Learning
2026-01-11

GBDT (Gradient Boosting Decision Tree) 是另一种基于 Boosting 思想的集成算法,除此之外 GBDT 还有很多其他的叫法,例如:GBM (Gradient Boosting Machine),GBRT (Gradient Boosting Regression Tree),MART (Multiple Additive Regression Tree) 等等。GBDT 算法由 3 个主要概念构成:Gradient Boosting (GB),Regression Decision Tree (DT 或 RT) 和 Shrinkage。 0. Decision Tree:CART回归树 首先,GBDT使用的决策树是CART回归树,无论是处理回归问题还...