
进程 一个在内存中运行的应用程序。每个进程都有自己独立的一块内存空间,一个进程可以有多个线程,比如在Windows系统中,一个运行的xx.exe就是一个进程。 线程 进程中的一个执行任务(控制单元),负责当前进程中程序的执行。一个进程至少有一个线程,一个进程可以运行多个线程,多个线程可共享数据。 与进程不同的是同类的多个线程共享进程的堆和方法区资源,但每个线程有自己的程序计数器、虚拟机栈和本地方法栈,所以系统在产生一个线程,或是在各个线程之间作切换工作时,负担要比进程小得多,也正因为如此,线程也被称为轻量级进程。 Java 程序天生就是多线程程序,我们可以通过 JMX 来看一下一个普通的 Java 程序有哪些线程,代码如下。 public class MultiThread {
public static void main(String[] args) {
// 获取 Java 线程管理 MXBean
ThreadMXBean threadMXBean = ManagementFactory.getThreadMXBean();
// 不需要获取同步的 monitor...
Computer Vision
2026-04-09
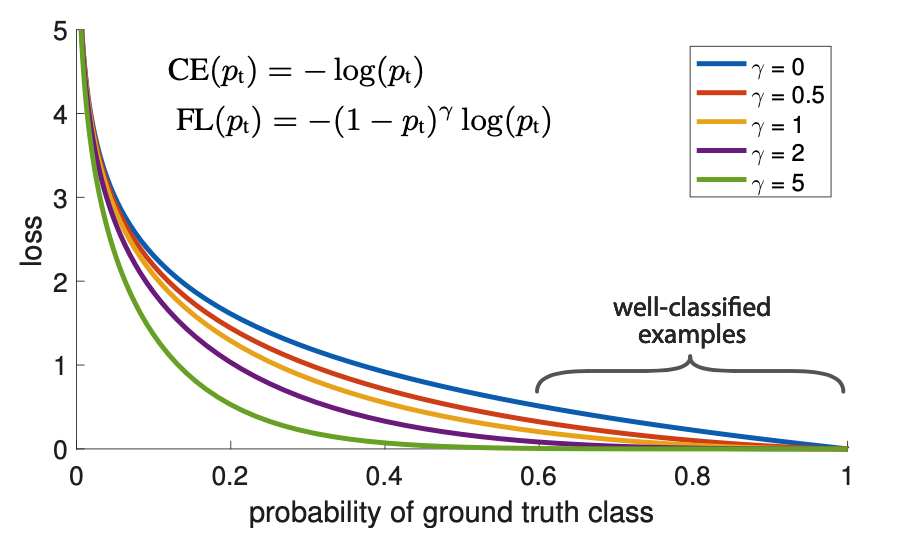
Focal Loss 在早期的目标检测中,最头疼的问题是 正负样本极度不平衡 (背景太多,物体太少),且大量背景是“容易分类的负样本”。传统的交叉熵损失(BCE)会被这些海量的简单样本淹没。 为了解决这个问题,Focal Loss (FL) 引入了一个动态缩放因子: 对于正样本,损失大致为: \(-(1-p)^\gamma \log(p)\) 核心逻辑: 如果模型已经预测得很准了(概率 \(p\) 接近 \(1\) ),那么 \((1−p)^\gamma\) 就会趋近于 \(0\) ,从而 降低简单样本的权重 ,强迫模型去关注那些还没学好的“困难样本”。 focal loss 形式如下 \[\text{FL}(p,y) = \begin{cases} -\alpha(1-p)^\gamma log(p) & y = 1 \\ -(1-\alpha)p^\gamma log(1-p) & y=0 \end{cases}\tag{1}\] 详情参考: Focal Loss & RetinaNet GFL(Generalized Focal Loss) 论文地址:...
Computer Vision
2026-04-08

原理分析 网络架构 本文的任务是Object detection,用到的工具是Transformers,特点是End-to-end。 目标检测的任务是要去预测一系列的Bounding Box的坐标以及Label, 现代大多数检测器通过定义一些proposal,anchor或者windows,把问题构建成为一个分类和回归问题来间接地完成这个任务。 文章所做的工作,就是将transformers运用到了object detection领域,取代了现在的模型需要手工设计的工作,并且取得了不错的结果。 在object detection上DETR准确率和运行时间上和Faster RCNN相当;将模型 generalize 到 panoptic segmentation 任务上,DETR表现甚至还超过了其他的baseline。DETR第一个使用End to End的方式解决检测问题,解决的方法是把检测问题视作是一个set prediction problem,如下图所示。...
杂七杂八
2026-04-02

分布式深度学习里的通信严重依赖于规则的集群通信,诸如 all-reduce, reduce-scatter, all-gather 等,因此,实现高度优化的集群通信,以及根据任务特点和通信拓扑选择合适的集群通信算法至关重要。 本文以数据并行经常使用的 all-reduce 为例来展示集群通信操作的数学性质。 All-reduce 在干什么? 图 1:all-reduce 如图 1 所示,一共 4个设备,每个设备上有一个矩阵(为简单起见,我们特意让每一行就一个元素), all-reduce 操作的目的是,让每个设备上的矩阵里的每一个位置的数值都是所有设备上对应位置的数值之和。 图2 如图 2 所示, all-reduce 可以通过 reduce-scatter 和 all-gather 这两个更基本的集群通信操作来实现。基于 ring 状通信可以高效的实现 reduce-scatter 和 all-gather,下面我们分别用示意图展示其过程。 reduce-scatter 的实现和性质 图 3:通过环状通信实现 reduce-scatter 从图 2...
Self-Supervised
2026-04-02
相关内容 自监督学习 (Self-supervised):属于无监督学习,其核心是自动为数据打标签(伪标签或其他角度的可信标签,包括图像的旋转、分块等等),通过让网络按照既定的规则,对数据打出正确的标签来更好地进行特征表示,从而应用于各种下游任务。 互信息 (Mutual Information):表示两个变量 \(X\) 和 \(Y\) 之间的关系,定义为: \[I(X;Y)=\sum_{x\in X}\sum_{y\in Y}p(x,y)log\frac{p(x|y)}{p(x)}\] 噪声对抗估计 (Noise Contrastive Estimation, NCE):在NLP任务中一种降低计算复杂度的方法,将语言模型估计问题简化为一个二分类问题。 Introduction 无监督学习一个重要的问题就是学习有用的 representation,本文的目的就是训练一个 representation learning 函数(即编码器encoder) ,其通过最大编码器输入和输出之间的互信息(MI)来学习对下游任务有用的 representation,而互信息可以通过 MINE...
Self-Supervised
2026-04-02

the machine predicts any parts of its input for any observed part 这是LeCun在AAAI 2020上对自监督学习的定义,再结合传统的自监督学习定义,可以总结如下两点特征: 通过“半自动”过程从数据本身获取“标签”; 从“其他部分”预测部分数据。 个人理解, 其实任意挖掘对象之间联系、探索不同对象共同本质的方法,都或多或少算是自监督学习的思想 。 自监督学习与无监督学习的区别主要在于,无监督学习专注于检测特定的数据模式,如聚类、社区发现或异常检测,而自监督学习的目标是恢复(recovering),仍处于监督学习的范式中。上图展示了三者之间的区别, 自监督中的“related information” 可以来自其他模态、输入的其他部分以及输入的不同形式。 Self-Supervised...
Self-Supervised
2026-04-02

如果把 近几年对比学习在视觉领域有代表性的工作做一下总结,那么对比学习的发展历程大概可以分为四个阶段: 百花齐放 这个阶段代表性工作有InstDisc(instance discrimination,)、CPC、CMC等。在这个阶段中,方法、模型、目标函数、代理任务都还没有统一,所以说是一个百花齐放的时代 CV双雄 代表作有MoCo v1、SimCLR v1、MoCo v2、SimCLR v2;CPC、CMC的延伸工作、SwAV等。这个阶段发展非常迅速,有的工作间隔甚至不到一个月,ImageNet上的成绩基本上每个月都在被刷新。 不用负样本 BYOL及其改进工作、SimSiam(CNN在对比学习中的总结性工作) transformer MoCo v3、DINO。这个阶段,无论是对比学习还是最新的掩码学习,都是用Vision Transformer做的。 第一阶段:百花齐放(2018-2019Mid) InstDisc(instance discrimination) 这篇文章提出了个体判别任务(代理任务)以及 memory bank ,非常经典,后人给它的方法起名为InstDisc。...
Large Model
2026-03-10

问题背景 首先简化一下问题,本文所讨论的多模态,主要指图文混合的双模态,即输入和输出都可以是图文。可能有不少读者的第一感觉是:多模态模型难道不也是烧钱堆显卡,Transformer“一把梭”,最终“大力出奇迹”吗? 其实没那么简单。先看文本生成,事实上文本生成自始至终都只有一条主流路线,那就是语言模型,即建模条件概率 \(p(x_t|x_1,\cdots,x_{t-1})\) ,不论是最初的 n-gram语言模型,还是后来的Seq2Seq、GPT,都是这个条件概率的近似。也就是说,一直以来,人们对“实现文本生成需要往哪个方向走”是很明确的,只是背后所用的模型有所不同,比如LSTM、CNN、Attention乃至最近复兴的线性RNN等。所以, 文本生成确实可以All in Transformer来大力出奇迹,因为方向是标准的、清晰的。 然而,对于图像生成,并没有这样的“标准方向”。就本站所讨论过的图像生成模型,就有 VAE 、 GAN 、 Flow 、 Diffusion ,还有小众的 EBM...
Generative Model
2026-03-04

SD模型原理 SD是CompVis、Stability AI和LAION等公司研发的一个文生图模型,它的模型和代码是开源的,而且训练数据LAION-5B也是开源的。SD在开源90天github仓库就收获了 33K的stars ,可见这个模型是多受欢迎。 SD是一个 基于latent的扩散模型 ,它在UNet中引入text condition来实现基于文本生成图像。SD的核心来源于 Latent Diffusion 这个工作,常规的扩散模型是基于pixel的生成模型,而Latent Diffusion是基于latent的生成模型,它先采用一个autoencoder将图像压缩到latent空间,然后用扩散模型来生成图像的latents,最后送入autoencoder的decoder模块就可以得到生成的图像。 基于latent的扩散模型的优势在于计算效率更高效,因为图像的latent空间要比图像pixel空间要小,这也是SD的核心优势...
Generative Model
2026-03-04
技术分析 从方法上来看,条件控制生成的方式分两种: 事后修改(Classifier-Guidance)和事前训练(Classifier-Free) 。 对于大多数人来说,一个SOTA级别的扩散模型训练成本太大了,而分类器(Classifier)的训练还能接受,所以就想着直接复用别人训练好的无条件扩散模型,用一个分类器来调整生成过程以实现控制生成,这就是事后修改的Classifier-Guidance方案;而对于“财大气粗”的Google、OpenAI等公司来说,它们不缺数据和算力,所以更倾向于往扩散模型的训练过程中就加入条件信号,达到更好的生成效果,这就是事前训练的Classifier-Free方案。 Classifier-Guidance方案最早出自 《Diffusion Models Beat GANs on Image Synthesis》 ,最初就是用来实现按类生成的;后来 《More Control for Free! Image Synthesis with Semantic Diffusion Guidance》...
Generative Model
2026-03-04

Flow Matching 其实是将 flow 的离散形式转换为连续形式(连续标准化流CNF),进而可以看成是一个ODE方程,实际求解的是这个ODE 求解的核心思路是:构建速度场通过数值积分求解位移,也就是通过预测速度场,从而转为ode求解 从概率路径的角度上来说,解是无穷多的,不同的方法本质上讲是在于构造尽可能简单、直接、易解的概率路径 通过不同的条件概率路径,可以构造出VP(score matching)、 VE(diffusion)、OT(1-rectified flow)等形式 实际的边缘概率分布路径并不是一条直线 ,我们是通过拟合条件速度场来逼近边缘速度场, 即使我们证明了对于参数 \(\theta\) 来说优化目标是等价的,但终究还是有一些gap Flow-based Models Normalizing Flow Normalizing Flow 是一种基于 变换 对概率分布进行建模的模型,其通过一系列 离散且可逆的变换 实现任意分布与先验分布(例如标准高斯分布)之间的相互转换。在 Normalizing Flow...
Generative Model
2026-03-04

Diffusion Models from SDE 连续扩散模型 (Continuous Diffusion Models) 将传统的离散时间扩散过程扩展到连续时间域,可以被视为一个随机过程,使用随机微分方程(SDE)来描述。其前向过程可以写成如下形式: \[\mathrm d\mathbf x=\mathbf f(\mathbf x,t)\mathrm dt+g(t)\mathrm d\mathbf w\tag{1}\] 其中, \(f(x,t)\) 可以看成偏移系数, \(g(t)\) 可以看成是扩散系数, \(dw\) 是标准布朗运动。这个SDE 描述了数据在连续时间域内如何被噪声逐渐破坏。 这个随机过程的 逆向过程 存在(更准确的描述:下面的逆向时间SDE具有 与正向过程SDE相同的联合分布 )为 \[d\mathbf{x}=[\mathbf{f}(\mathbf{x},t)-g^2(t)\nabla_{\mathbf{x}}\log p_t(\mathbf{x})]dt+g(t)d\bar{\mathbf{w}}\tag{2}\]...