76. 最小覆盖子串 题目 给定两个字符串 s 和 t ,长度分别是 m 和 n ,返回 s 中的 最短窗口 子串 ,使得该子串包含 t 中的每一个字符( 包括重复字符 )。如果没有这样的子串,返回空字符串 "" 。 测试用例保证答案唯一。 示例 1: 输入:s = "ADOBECODEBANC", t = "ABC"
输出:"BANC"
解释:最小覆盖子串 "BANC" 包含来自字符串 t 的 'A'、'B' 和 'C'。 示例 2: 输入:s = "a", t = "a"
输出:"a"
解释:整个字符串 s 是最小覆盖子串。 示例 3: 输入: s = "a", t = "aa"
输出: ""
解释: t 中两个字符 'a' 均应包含在 s 的子串中,
因此没有符合条件的子字符串,返回空字符串。 提示: m == s.length n == t.length 1 <= m, n <= 10 5 s 和 t 由英文字母组成 题解 这是一个经典的 滑动窗口 (Sliding Window) 问题 我们需要维护一个动态的窗口 [left, right] : 右移扩大 :不断移动...
Generative Model
2026-01-18

2022年中旬,以扩散模型为核心的图像生成模型将AI绘画带入了大众的视野。实际上,在更早的一年之前,就有了一个能根据文字生成高清图片的模型——VQGAN。VQGAN不仅本身具有强大的图像生成能力,更是传承了前作VQVAE把图像压缩成离散编码的思想,推广了「先压缩,再生成」的两阶段图像生成思路,启发了无数后续工作。 VQGAN 核心思想 VQGAN的论文名为 Taming Transformers for High-Resolution Image Synthesis,直译过来是「驯服Transformer模型以实现高清图像合成」。可以看出,该方法是在用Transformer生成图像。可是,为什么这个模型叫做VQGAN,是一个GAN呢?这是因为,VQGAN使用了两阶段的图像生成方法: 训练时,先训练一个图像压缩模型(包括编码器和解码器两个子模型),再训练一个生成压缩图像的模型。 生成时, 先用第二个模型生成出一个压缩图像,再用第一个模型复原成真实图像 。 其中,第一个图像压缩模型叫做VQGAN,第二个压缩图像生成模型是一个基于Transformer的模型。...
Generative Model
2026-01-18
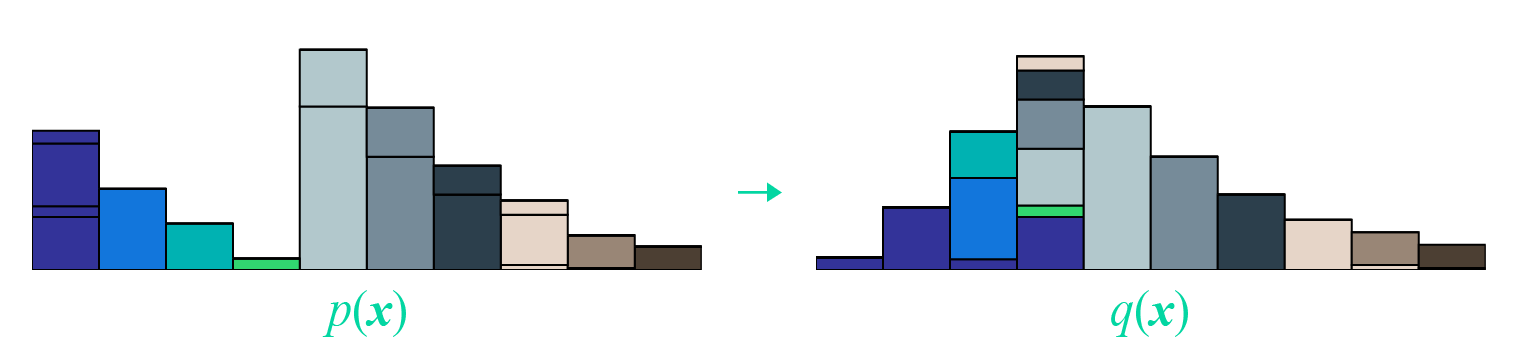
本文受启发于著名的国外博文 《Wasserstein GAN and the Kantorovich-Rubinstein Duality》 ,内容跟它大体上相同,但是删除了一些冗余的部分,对不够充分或者含糊不清的地方作了补充。 Wasserstein距离 显然,整篇文章必然围绕着Wasserstein距离( \(\mathcal{W}\) 距离)来展开。假设我们有了两个概率分布 \(p(x),q(x)\) ,那么Wasserstein距离的定义为 \[\mathcal{W}[p,q]=\inf_{\gamma\in \Pi[p,q]} \iint \gamma(\boldsymbol{x},\boldsymbol{y}) d(\boldsymbol{x},\boldsymbol{y}) d\boldsymbol{x}d\boldsymbol{y}\] 事实上,这也算是最优传输理论中最核心的定义了。 成本函数 首先 \(d(x,y)\) ,它不一定是距离,其准确含义应该是一个成本函数,代表着从 \(x\) 运输到 \(y\) 的成本。常用的 \(d\) 是基于 \(l\)...

简介 生成对抗网络 ( Generative Adversarial Network, GAN ) 是由 Goodfellow 于 2014 年提出的一种对抗网络。这个网络框架包含两个部分,一个生成模型 (generative model) 和一个判别模型 (discriminative model)。其中,生成模型可以理解为一个伪造者,试图通过构造假的数据骗过判别模型的甄别;判别模型可以理解为一个警察,尽可能甄别数据是来自于真实样本还是伪造者构造的假数据。两个模型都通过不断的学习提高自己的能力,即生成模型希望生成更真的假数据骗过判别模型,而判别模型希望能学习如何更准确的识别生成模型的假数据。 网络框架 GAN 由两部分构成,一个 生成器 ( Generator ) 和一个 判别器 ( Discriminator )。对于生成器,我们需要学习关于数据 \(x\) 的一个分布 \(p_g\) ,首先定义一个输入数据的先验分布 \(p_z(z)\) ,其次定义一个映射 \(G \left(\boldsymbol{z}; \theta_g\right): \boldsymbol{z}...
Computer Vision
2026-01-11

空洞卷积 Dilated/Atrous Convolution 或者是 Convolution with holes 从字面上就很好理解,是在标准的 convolution map 里注入空洞,以此来增加 reception field。相比原来的正常convolution,dilated convolution 多了一个 hyperparameter 称之为 dilation rate 指的是kernel的间隔数量(e.g. 正常的 convolution 是 dilatation rate 1)。 一个简单的例子 一维情况下空洞卷积的公式如下 [Formula] 不过光理解他的工作原理还是...
Computer Vision
2026-01-11
PA Pixel Accuracy(PA,像素精度):这是最简单的度量,为标记正确的像素占总像素的比例。 [公式] 图像中共有k+1(包含背景)类, p_{ii} 表示将第i类分成第 i 类的像素数量(正确分类的像素数量), p_{ij} 表示将第 i 类分成第 j 类的像素数量(所有像素数量) 因此该比值表示正确分类的像素数量占总像素数量的比例。 优点:简单 缺点:如果图像中大面积是背景,而目标较小,即使将整个图片预测为背景,也会有很高的PA得分,因此该指标不适用于评价以小目标为主的图像分割效果。 MPA Mean Pixel Accuracy(MPA,均像素精度):是PA的一种简单提升,计算每个类内被正确分类像素数的比例,之后求所有类的平均。 [公式] MIoU Mean Interse...
Computer Vision
2026-01-11

Segment Anything Segment Anything(SA)项目:一个用于图像分割的新任务、新模型和新数据集 通过FM(基础模型)+prompt解决了CV中难度较大的分割任务,给计算机视觉实现基础模型+提示学习+指令学习提供了一种思路 关键:加大模型容量(构造海量的训练数据,或者构造合适的自监督任务来预训练) Segment Anything Task SAM的一部分灵感是来源于NLP中的基座模型(Foundation Model),Foundation Model是OpenAI提出的一个概念,它指的是在超大量数据集上预训练过的大模型(如GPT系列、BERT),这些模型具有非常强大的 zeroshot 和 fewshot能力,结合prompt engineering和fine ...
Computer Vision
2026-01-11
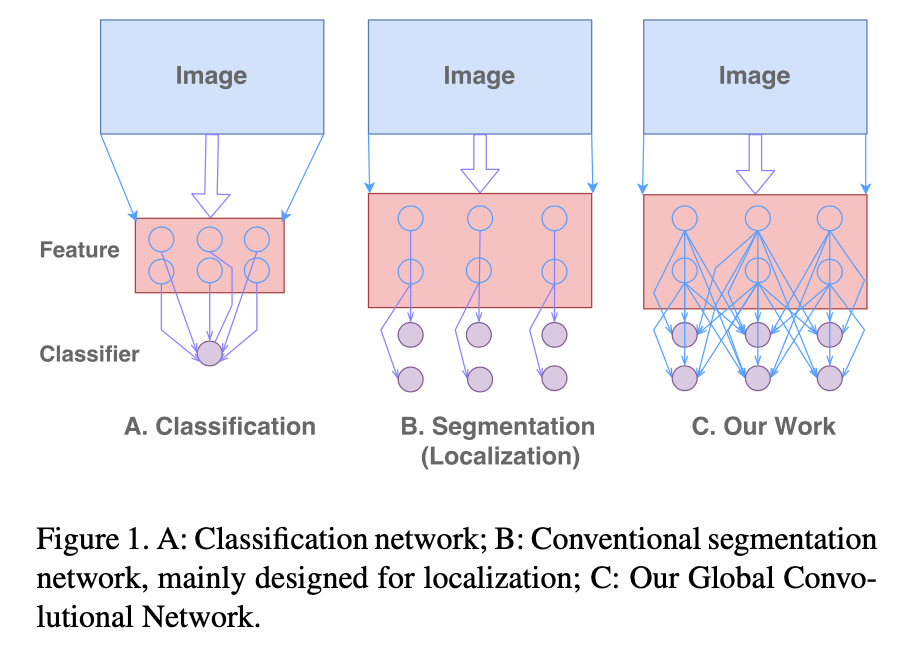
CVPR2017 算法 Global Convolutional Network(GCN),江湖人送外号“Large Kernel”。 Motivation GCN 主要将 Semantic Segmentation分解为:Classification 和 Localization两个问题。但是,这两个任务本质对特征的需求是矛盾的,Classification需要特征对多种Transformation具有不变性,而 Localization需要对 Transformation比较敏感。但是,普通的 Segmentation Model大多针对 Localization Issue设计,正如图(b)所示,而这不利于 Classification。 所以,为了兼顾这两个 Task,本文提出了两个...