128. 最长连续序列 题目 给定一个未排序的整数数组 nums ,找出数字连续的最长序列(不要求序列元素在原数组中连续)的长度。 请你设计并实现时间复杂度为 O(n) 的算法解决此问题。 示例 1: 输入:nums = [100,4,200,1,3,2]
输出:4
解释:最长数字连续序列是 [1, 2, 3, 4]。它的长度为 4。 示例 2: 输入:nums = [0,3,7,2,5,8,4,6,0,1]
输出:9 示例 3: 输入:nums = [1,0,1,2]
输出:3 提示: 0 <= nums.length <= 10 5 -10 9 <= nums[i] <= 10 9 题解 我们需要在 \(O(1)\) 的时间内查找某个数是否存在。因此,首先将数组中的所有元素放入一个 HashSet 中。这不仅能去重,还能支持快速查找。 避免冗余计算 (关键优化) 如果我们对集合中的每一个数都尝试去向后计数(例如,对于 x ,尝试找 x+1 , x+2 ...),最坏情况下的时间复杂度会退化到 \(O(n^2)\) 。 优化策略 : 我们 只从序列的起点开始计数 。...
76. 最小覆盖子串 题目 给定两个字符串 s 和 t ,长度分别是 m 和 n ,返回 s 中的 最短窗口 子串 ,使得该子串包含 t 中的每一个字符( 包括重复字符 )。如果没有这样的子串,返回空字符串 "" 。 测试用例保证答案唯一。 示例 1: 输入:s = "ADOBECODEBANC", t = "ABC"
输出:"BANC"
解释:最小覆盖子串 "BANC" 包含来自字符串 t 的 'A'、'B' 和 'C'。 示例 2: 输入:s = "a", t = "a"
输出:"a"
解释:整个字符串 s 是最小覆盖子串。 示例 3: 输入: s = "a", t = "aa"
输出: ""
解释: t 中两个字符 'a' 均应包含在 s 的子串中,
因此没有符合条件的子字符串,返回空字符串。 提示: m == s.length n == t.length 1 <= m, n <= 10 5 s 和 t 由英文字母组成 题解 这是一个经典的 滑动窗口 (Sliding Window) 问题 我们需要维护一个动态的窗口 [left, right] : 右移扩大 :不断移动...
Large Model
2026-01-15

简介 后训练(post-training)已成为完整训练流程中的重要组成部分。相比于预训练,后训练需要的计算资源相对较少,但能够: 提高推理任务的准确性 使模型与社会价值观保持一致 适应用户偏好 OpenAI 的 o1 系列模型首次引入了通过增加思维链(Chain-of-Thought)推理过程长度来实现推理时间,扩展这种方法在数学、编程和科学推理等各种推理任务上取得了显著改进 研究界已探索多种方法来提高模型的推理能力:比如 基于过程的奖励模型 (Process-based Reward Models) 强化学习 (Reinforcement Learning), 代表工作:InstructGPT, 以及 搜索算法( 蒙特卡洛树搜索(Monte Carlo Tree Search)、束搜索(Beam Search))。然而,这些方法尚未达到与 OpenAI o1 系列模型相当的通用推理性能。 DeepSeek-R1-Zero 本文首先探索使用纯强化学习(RL)来提高语言模型的推理能力,重点关注: 探索 LLM 在没有任何监督数据的情况下,通过纯 RL 过程的自我进化来发展推理能力...
Computer Vision
2026-01-11
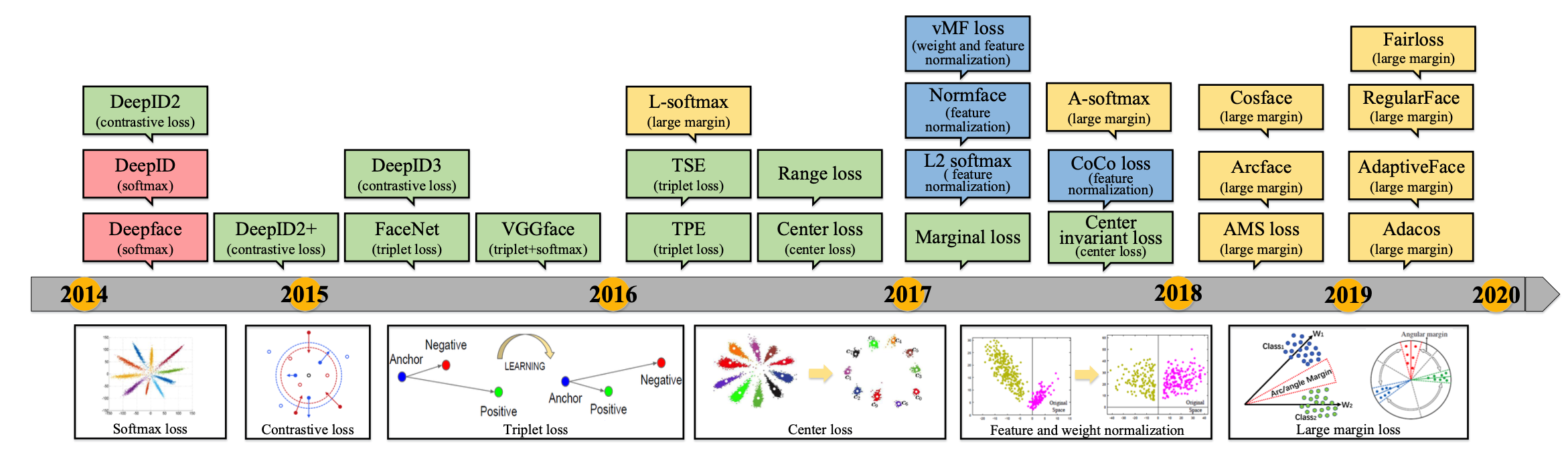
超多分类的Softmax 2014年CVPR两篇超多分类的人脸识别论文:DeepFace和DeepID DeepFace Taigman Y, Yang M, Ranzato M A, et al. Deepface: Closing the gap to humanlevel performance in face verification [C]// CVPR, 2014. 4.4M训练集,训练6层CNN + 4096特征映射 + 4030类Softmax,综合如3D Aligement, model ensembel等技术,在LFW上达到97.35%。 DeepID Sun Y, Wang X, Tang X. Deep learning face representation fro...
Computer Vision
2026-01-11
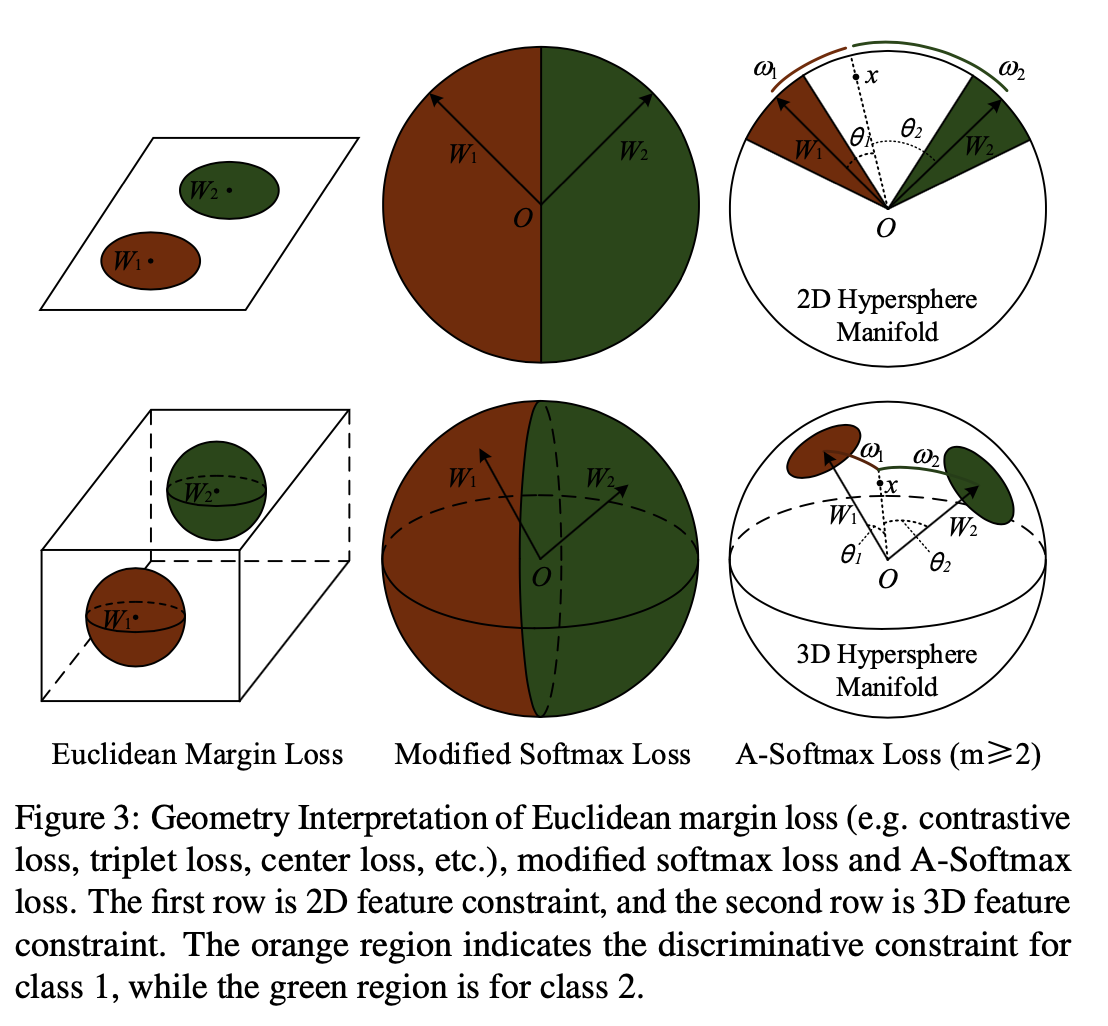
推导 回顾一下二分类下的Softmax后验概率,即: [公式] 显然决策的分界在当 𝑝_1=𝑝_2 时,所以决策界面是 (𝑊_1−𝑊_2)𝑥+𝑏_1−𝑏_2=0 。我们可以将 𝑊^𝑇_𝑖𝑥+𝑏_𝑖 写成 ‖W_i^T‖⋅‖x‖cos(θ_i)+b_i ,其中 θ_i 是 W_i 与 x 的夹角,如对 W_i 归一化且设偏置 b_i 为零( ‖W_i‖=1 , b_i=0 ),那么当 p_1=p_2 时,我们有 cos(θ_1)−cos(θ_2)=0 。从这里可以看到,如里一个输入的数据特征 x_i 属于 𝑦_𝑖 类,那么 θ_{y_i} 应该比其它所有类的角度都要小,也就是说在向量空间中 W_{y_i} 要更靠近 x_i 。 我们用的是Softmax Loss,对于输入 x_i ,So...
Deep Learning
2026-01-11

引言与背景 随机逼近(Stochastic Approximation)是一类用于求解寻根或优化问题的随机迭代算法,其特点是不需要知道目标函数或其导数的表达式。 随机逼近的核心优势在于: 能够处理带有随机噪声的观测数据 不需要目标函数的解析表达式 可以在线学习,每获得一个新样本就更新估计值 均值估计问题 考虑一个随机变量 X ,其取值来自有限集合 [Math] 。我们的目标是估计 E[X] 。假设我们有一个独立同分布的样本序列 \{x_i\}_{i=1}^n ,那么 X 的期望值可以近似为: [公式] 非增量方法与增量方法 非增量方法:先收集所有样本,然后计算平均值。缺点是如果样本数量很大,可能需要等待很长时间。 增量方法:定义 [公式] 可以推导出递归公式: [公式] 这个算法可以增量式地...
Reinforcement Learning
2026-01-11

引言与背景 蒙特卡洛方法是强化学习中的重要算法类别,它标志着从基于模型到无模型算法的转变。这类算法不依赖环境模型,而是通过与环境的直接交互获取经验数据来学习最优策略。 蒙特卡洛方法在强化学习算法谱系中处于"无模型"方法的起始位置,是从基于模型的方法(如值迭代和策略迭代)向无模型方法过渡的第一步。 无模型强化学习的核心理念可以简述为:如果没有模型,我们必须有数据;如果没有数据,我们必须有模型;如果两者都没有,我们就无法找到最优策略。在强化学习中,"数据"通常指智能体与环境交互的经验。 均值估计问题 在介绍蒙特卡洛强化学习算法之前,我们首先需要理解均值估计问题,这是理解从数据而非模型中学习的基础。 考虑一个可以取有限实数集合 X 中值的随机变量 X ,我们的任务是计算 X 的均值或期望值: E[...
Reinforcement Learning
2026-01-11

基础概念 GridWord Example 环境描述:网格世界是一个直观的二维环境,包含: 任务目标: 什么是强化学习:依据策略执行动作感知状态得到奖励 所谓强化学习(Reinforcement Learning,简称RL),是指基于智能体在复杂、不确定的环境中最大化它能获得的奖励,从而达到自主决策的目的。 a computational approach to learning whereby an agent tries to maximize the total amount of reward it receives while interacting with a complex and uncertain environment 经典的强化学习模型可以总结为下图的形式(你可以理解...
背景 RLHF 通常包括三个阶段: 有监督微调(SFT) 奖励建模阶段 (Reward Model) RL微调阶段 直接偏好优化(DPO) 传统的RLHF方法分两步走: 1. 先训练一个奖励模型来判断哪个回答更好 1. 然后用强化学习让语言模型去最大化这个奖励 这个过程很复杂,就像绕了一大圈:先学习"什么是好的",再学习"如何做好"。 DPO发现了一个数学上的捷径: 1. 关键发现:对于任何奖励函数,都存在一个对应的最优策略(语言模型);反过来说,任何语言模型也隐含着一个它认为最优的奖励函数 1. 直接优化:与其先训练奖励模型再训练语言模型,不如直接训练语言模型,让它自己内化"什么是好的" 1. 数学转换:DPO将"学习判断好坏"和"学习生成好内容"这两个任务合二为一,通过一个简单的数学变换...
Large Model
2026-01-11

模型概述 KimiVL 是一个高效的开源混合专家视觉语言模型(VLM),它提供先进的多模态推理、长上下文理解和强大的代理能力,同时在语言解码器中仅激活 2.8B 参数(KimiVLA3B)。该模型在多种挑战性任务中表现出色,包括一般用途的视觉语言理解、多轮代理任务、大学水平的图像和视频理解、OCR、数学推理和多图像理解等. 模型架构 KimiVL 的架构由三个主要部分组成: MoE语言模型 Moonlight MoE language model with only 2.8B activated (16B total) parameters 视觉模型 400M nativeresolution MoonViT vision encoder. MLP Projector MoonViT: 原生...
Computer Vision
2026-01-11
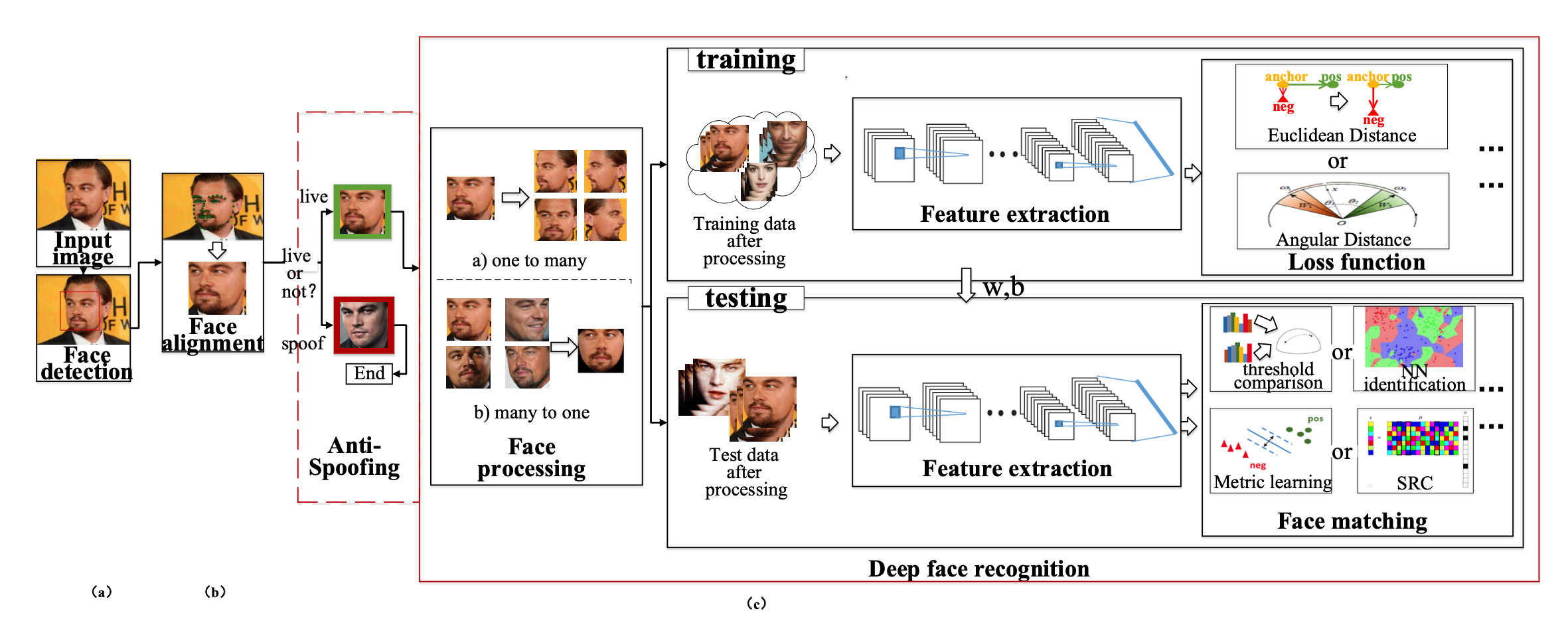
简介 一个完整的人脸识别系统包含以下几个模块 Face Detection: 人脸检测 Face Alignment:基于人脸关键点坐标对齐到正则坐标系下坐标 Face Recognition:基于对齐人脸进行识别 人脸识别的算法流程 人脸的识别流程:面部姿态处理(处理姿态,亮度,表情,遮挡),特征提取,人脸比对。 面部处理 face processing 这部分主要对姿态(主要)、亮度、表情、遮挡进行处理,可提升FR模型性能 主要包含两种处理方式: 1. "Onetomany Augmentation": 从单个图像生成不同姿态的图像,使模型学习到姿态不变性的表示 1. "Manytoone Normalization": 从多个不同姿态的图像中恢复人脸图像的标准视图 特征提取 Backb...
Reinforcement Learning
2026-01-11

引言 DDPG同样使用了ActorCritic的结构,Deterministic的确定性策略是和随机策略相对而言的,对于某一些动作集合来说,它可能是连续值,或者非常高维的离散值,这样动作的空间维度极大。如果我们使用随机策略,即像DQN一样研究它所有的可能动作的概率,并计算各个可能的动作的价值的话,那需要的样本量是非常大才可行的。于是有人就想出使用确定性策略来简化这个问题。 作为随机策略,在相同的策略,在同一个状态 s 处,采用的动作 [Math] 是基于一个概率分布的,即是不确定的。而确定性策略则决定简单点,虽然在同一个状态处,采用的动作概率不同,但是最大概率只有一个,如果我们只取最大概率的动作,去掉这个概率分布,那么就简单多了。即作为确定性策略,相同的策略,在同一个状态处,动作是唯一确定的...