
进程 一个在内存中运行的应用程序。每个进程都有自己独立的一块内存空间,一个进程可以有多个线程,比如在Windows系统中,一个运行的xx.exe就是一个进程。 线程 进程中的一个执行任务(控制单元),负责当前进程中程序的执行。一个进程至少有一个线程,一个进程可以运行多个线程,多个线程可共享数据。 与进程不同的是同类的多个线程共享进程的堆和方法区资源,但每个线程有自己的程序计数器、虚拟机栈和本地方法栈,所以系统在产生一个线程,或是在各个线程之间作切换工作时,负担要比进程小得多,也正因为如此,线程也被称为轻量级进程。 Java 程序天生就是多线程程序,我们可以通过 JMX 来看一下一个普通的 Java 程序有哪些线程,代码如下。 public class MultiThread {
public static void main(String[] args) {
// 获取 Java 线程管理 MXBean
ThreadMXBean threadMXBean = ManagementFactory.getThreadMXBean();
// 不需要获取同步的 monitor...
Computer Vision
2026-04-09
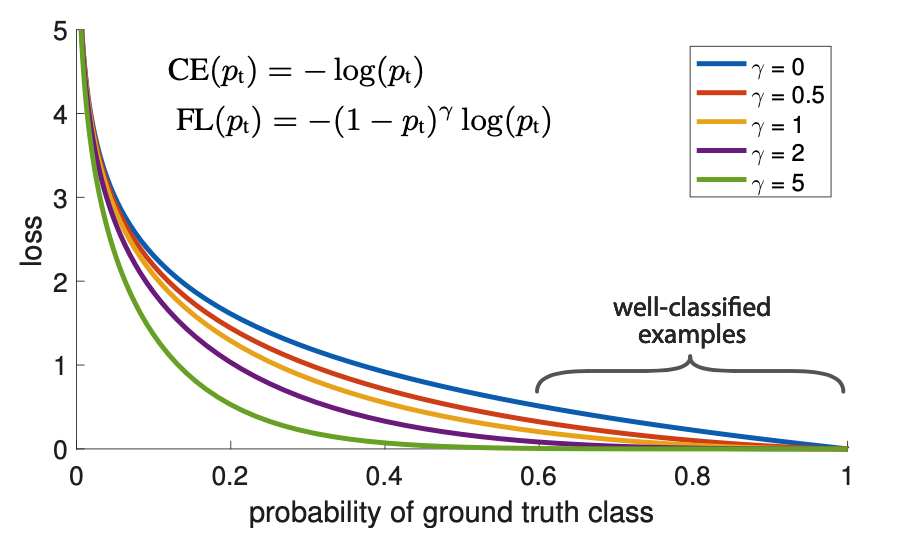
Focal Loss 在早期的目标检测中,最头疼的问题是 正负样本极度不平衡 (背景太多,物体太少),且大量背景是“容易分类的负样本”。传统的交叉熵损失(BCE)会被这些海量的简单样本淹没。 为了解决这个问题,Focal Loss (FL) 引入了一个动态缩放因子: 对于正样本,损失大致为: \(-(1-p)^\gamma \log(p)\) 核心逻辑: 如果模型已经预测得很准了(概率 \(p\) 接近 \(1\) ),那么 \((1−p)^\gamma\) 就会趋近于 \(0\) ,从而 降低简单样本的权重 ,强迫模型去关注那些还没学好的“困难样本”。 focal loss 形式如下 \[\text{FL}(p,y) = \begin{cases} -\alpha(1-p)^\gamma log(p) & y = 1 \\ -(1-\alpha)p^\gamma log(1-p) & y=0 \end{cases}\tag{1}\] 详情参考: Focal Loss & RetinaNet GFL(Generalized Focal Loss) 论文地址:...
Computer Vision
2026-04-08

原理分析 网络架构 本文的任务是Object detection,用到的工具是Transformers,特点是End-to-end。 目标检测的任务是要去预测一系列的Bounding Box的坐标以及Label, 现代大多数检测器通过定义一些proposal,anchor或者windows,把问题构建成为一个分类和回归问题来间接地完成这个任务。 文章所做的工作,就是将transformers运用到了object detection领域,取代了现在的模型需要手工设计的工作,并且取得了不错的结果。 在object detection上DETR准确率和运行时间上和Faster RCNN相当;将模型 generalize 到 panoptic segmentation 任务上,DETR表现甚至还超过了其他的baseline。DETR第一个使用End to End的方式解决检测问题,解决的方法是把检测问题视作是一个set prediction problem,如下图所示。...
杂七杂八
2026-04-02

分布式深度学习里的通信严重依赖于规则的集群通信,诸如 all-reduce, reduce-scatter, all-gather 等,因此,实现高度优化的集群通信,以及根据任务特点和通信拓扑选择合适的集群通信算法至关重要。 本文以数据并行经常使用的 all-reduce 为例来展示集群通信操作的数学性质。 All-reduce 在干什么? 图 1:all-reduce 如图 1 所示,一共 4个设备,每个设备上有一个矩阵(为简单起见,我们特意让每一行就一个元素), all-reduce 操作的目的是,让每个设备上的矩阵里的每一个位置的数值都是所有设备上对应位置的数值之和。 图2 如图 2 所示, all-reduce 可以通过 reduce-scatter 和 all-gather 这两个更基本的集群通信操作来实现。基于 ring 状通信可以高效的实现 reduce-scatter 和 all-gather,下面我们分别用示意图展示其过程。 reduce-scatter 的实现和性质 图 3:通过环状通信实现 reduce-scatter 从图 2...
Reinforcement Learning
2026-03-30
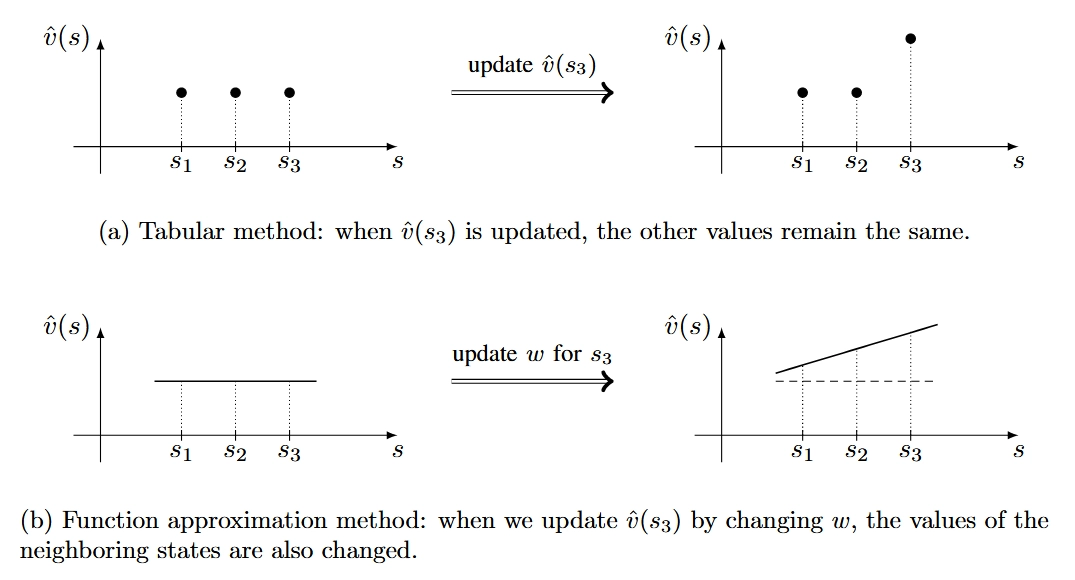
引言与背景 价值函数方法是强化学习中的核心技术,它解决了传统表格方法在处理大型状态或动作空间时的效率问题。本文探讨了从表格表示向函数表示的转变,这是强化学习算法发展的重要里程碑。 在强化学习的发展路径中,价值函数方法位于从基于模型到无模型、从表格表示到函数表示的演进过程中。它结合了时序差分学习的思想,并通过函数近似技术来处理复杂环境。 价值表示:从表格到函数 表格与函数表示的对比 传统的表格方法将状态值存储在一个表格中: 状态 \(s_1\) \(s_2\) \(\cdots\) \(s_n\) 估计值 \(\hat{v}(s_1)\) \(\hat{v}(s_2)\) \(\cdots\) \(\hat{v}(s_n)\) 而函数近似方法则使用参数化函数来表示这些值,例如: \[\hat{v}(s, w) = as + b = [s, 1] \begin{bmatrix} a \\ b \end{bmatrix} = \phi^T(s)w\] 其中 \(\phi(s)\in\mathbb{R}^2\) 称作是状态 \(s\) 的特征向量, \(w\) 是参数向量。...
Reinforcement Learning
2026-03-30

引言 时序差分(Temporal-Difference,TD)方法是强化学习中的一类核心算法,它结合了动态规划与蒙特卡洛方法的优点。TD方法是无模型(model-free)学习方法,不需要环境模型即可学习价值函数和最优策略。 TD方法的核心特点是通过比较不同时间步骤的估计值之间的差异来更新价值函数,这种差异被称为"时序差分误差"(TD error)。TD方法可以被视为解决贝尔曼方程或贝尔曼最优方程的特殊随机逼近算法。 基础TD算法:状态值函数学习 给定策略 \(\pi\) ,基础TD算法用于估计状态值函数 \(v_\pi(s)\) 。假设我们有一些按照策略 \(\pi\) 生成的经验样本 \((s_0, r_1, s_1, ..., s_t, r_{t+1}, s_{t+1}, ...)\) ,TD算法的更新规则为: \[\begin{equation}\begin{aligned}v_{t+1}(s_t) &= v_t(s_t) - \alpha_t(s_t)[v_t(s_t) - (r_{t+1} + \gamma v_t(s_{t+1}))]\\
v_{t+1}(s) &=...
Reinforcement Learning
2026-03-30
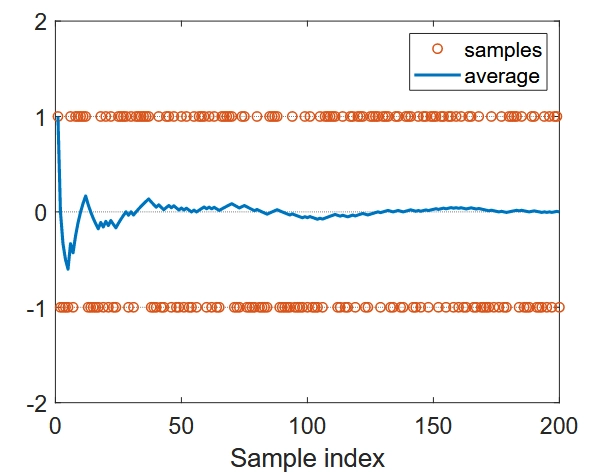
引言与背景 蒙特卡洛方法是强化学习中的重要算法类别,它标志着从基于模型到无模型算法的转变。这类算法不依赖环境模型,而是通过与环境的直接交互获取经验数据来学习最优策略。 蒙特卡洛方法在强化学习算法谱系中处于"无模型"方法的起始位置,是从基于模型的方法(如值迭代和策略迭代)向无模型方法过渡的第一步。 无模型强化学习的核心理念可以简述为: 如果没有模型,我们必须有数据;如果没有数据,我们必须有模型;如果两者都没有,我们就无法找到最优策略。在强化学习中,"数据"通常指智能体与环境交互的经验 。 均值估计问题 在介绍蒙特卡洛强化学习算法之前,我们首先需要理解均值估计问题,这是理解从数据而非模型中学习的基础。 考虑一个可以取有限实数集合 \(X\) 中值的随机变量 \(X\) ,我们的任务是计算 \(X\) 的均值或期望值: \(E[X]\) 有两种方法可以计算 \(E[X]\) : 基于模型的方法 :当已知随机变量的概率分布时,可以直接根据期望值的定义计算: \[E[X] = \sum_{x \in X} p(x) \cdot x\] 其中 \(p(x)\) 是 \(X\) 取值为 \(x\)...
NLP
2026-03-26

这篇文章主要去“复盘”一下主流的长度外推结果,并试图从中发现免训练长度外推的关键之处。 问题定义 顾名思义,免训练长度外推,就是不需要用长序列数据进行额外的训练,只用短序列语料对模型进行训练,就可以得到一个能够处理和预测长序列的模型,即“Train Short, Test Long”。那么如何判断一个模型能否用于长序列呢?最基本的指标就是模型的长序列Loss或者PPL不会爆炸,更加符合实践的评测则是输入足够长的Context,让模型去预测答案,然后跟真实答案做对比,算BLEU、ROUGE等, LongBench 就是就属于这类榜单。 但要注意的是,长度外推应当不以牺牲远程依赖为代价——否则考虑长度外推就没有意义了,倒不如直接截断文本——这意味着通过显式地截断远程依赖的方案都需要谨慎选择,比如ALIBI,还有带显式Decay的 线性RNN ,这些方案当序列长度足够大时都表现为局部注意力,即便有可能实现长度外推,也会有远程依赖不足的风险,需要根据自己的场景斟酌使用。 如何判断在长度外推的同时有没有损失远程依赖呢?比较严谨的是像 ReRoPE...
Large Model
2026-03-18
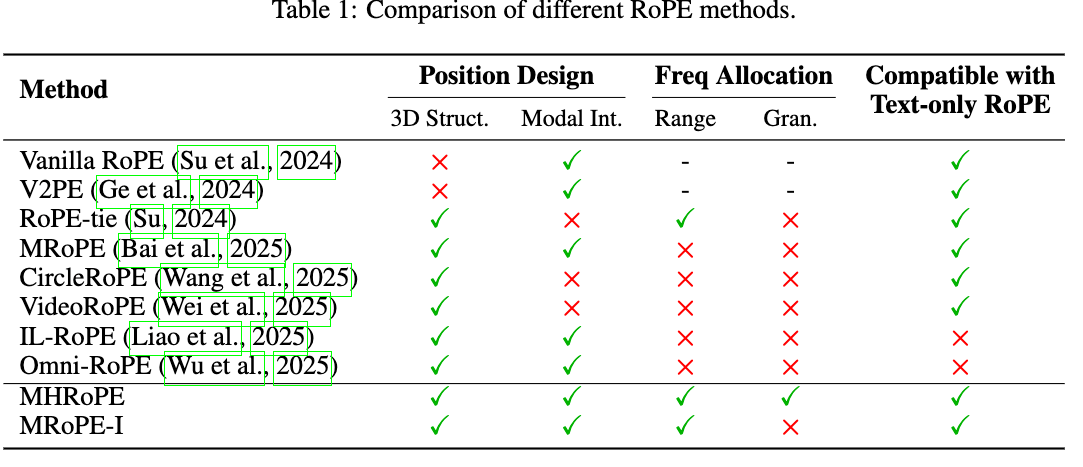
简介 论文: 《REVISITING MULTIMODAL POSITIONAL ENCODING IN VISION–LANGUAGE MODELS》 通过对多模态旋转位置嵌入(RoPE)的两个核心组件——位置设计和频率分配进行综合分析。通过实验,确定了三个关键指南:位置一致性、频率全利用和保留文本先验。基于这些见解,提出了多头RoPE(MHRoPE)和MRoPE-Interleave(MRoPE-I),这两种简单且即插即用的变体不需要任何架构更改。 为了构建更稳健的多模态位置编码,作者在MRoPE的基础上,系统地探索了三个未充分研究的方案: 位置设计——如何为文本和视觉标记分配无歧义、分离良好的坐标; 频率分配——如何将旋转频率分配到每个位置轴的嵌入维度; 与纯文本RoPE的兼容性——确保设计默认为标准RoPE,以便进行有效的迁移学习。 Vanilla RoPE RoPE与加性位置嵌入不同,RoPE对query和key向量应用旋转变换,从而将相对位置依赖直接纳入自注意力机制。给定位置 \(m\) 的查询向量 \(q\) 和位置 \(n\) 的键向量 \(k\) ,注意力分数...
NLP
2026-03-16
不同于RNN、CNN等模型,对于Transformer模型来说,位置编码的加入是必不可少的,因为纯粹的Attention模块是无法捕捉输入顺序的,即无法区分不同位置的Token。为此我们大体有两个选择: 想办法将位置信息融入到输入中,这构成了绝对位置编码的一般做法; 想办法微调一下Attention结构,使得它有能力分辨不同位置的Token,这构成了相对位置编码的一般做法。 虽然说起来主要就是绝对位置编码和相对位置编码两大类,但每一类其实又能衍生出各种各样的变种,为此研究人员可算是煞费苦心、绞尽脑汁了,此外还有一些不按套路出牌的位置编码。本文就让我们来欣赏一下研究人员为了更好地表达位置信息所构建出来的“八仙过海,各显神通”般的编码方案。 绝对位置编码 形式上来看,绝对位置编码是相对简单的一种方案,但即便如此,也不妨碍各路研究人员的奇思妙想,也有不少的变种。一般来说,绝对位置编码会加到输入中:在输入的第 𝑘 个向量 \(𝑥_𝑘\) 中加入位置向量 \(𝑝_𝑘\) 变为 \(\boldsymbol{x}_k + \boldsymbol{p}_k\) ,其中 \(...
Deep Learning
2026-03-02

Random erasing data augmentation 论文名称:Random erasing data augmentation 论文地址: https://arxiv.org/pdf/1708.04896v2.pdf 随机擦除增强,非常容易理解。作者提出的目的主要是模拟遮挡,从而提高模型泛化能力,这种操作其实非常make sense,因为我把物体遮挡一部分后依然能够分类正确,那么肯定会迫使网络利用局部未遮挡的数据进行识别,加大了训练难度,一定程度会提高泛化能力。其也可以被视为add noise的一种,并且与随机裁剪、随机水平翻转具有一定的互补性,综合应用他们,可以取得更好的模型表现,尤其是对噪声和遮挡具有更好的鲁棒性。具体操作就是:随机选择一个区域,然后采用随机值进行覆盖,模拟遮挡场景。 在细节上,可以通过参数控制擦除的面积比例和宽高比,如果随机到指定数目还无法满足设置条件,则强制返回。 一些可视化效果如下: Cutout 论文名称:Improved Regularization of Convolutional Neural Networks with Cutout...
Computer Vision
2026-02-27

Segment Anything Segment Anything(SA)项目:一个用于图像分割的新任务、新模型和新数据集 通过FM(基础模型)+prompt解决了CV中难度较大的分割任务,给计算机视觉实现基础模型+提示学习+指令学习提供了一种思路 关键:加大模型容量(构造海量的训练数据,或者构造合适的自监督任务来预训练) Segment Anything Task SAM的一部分灵感是来源于NLP中的基座模型(Foundation Model),Foundation Model是OpenAI提出的一个概念,它指的是在超大量数据集上预训练过的大模型(如GPT系列、BERT),这些模型具有非常强大的 zero-shot 和 few-shot能力,结合prompt engineering和fine tuning等技术可以将基座模型应用在各种下游任务中并实现惊人的效果。 SAM就是想构建一个这样的图像分割基座模型,即使是一个未见过的数据集,模型也能自动或半自动(基于prompt)地完成下游的分割任务。为了实现这个目标,SAM定义了一种可提示化的分割任务(promptable...