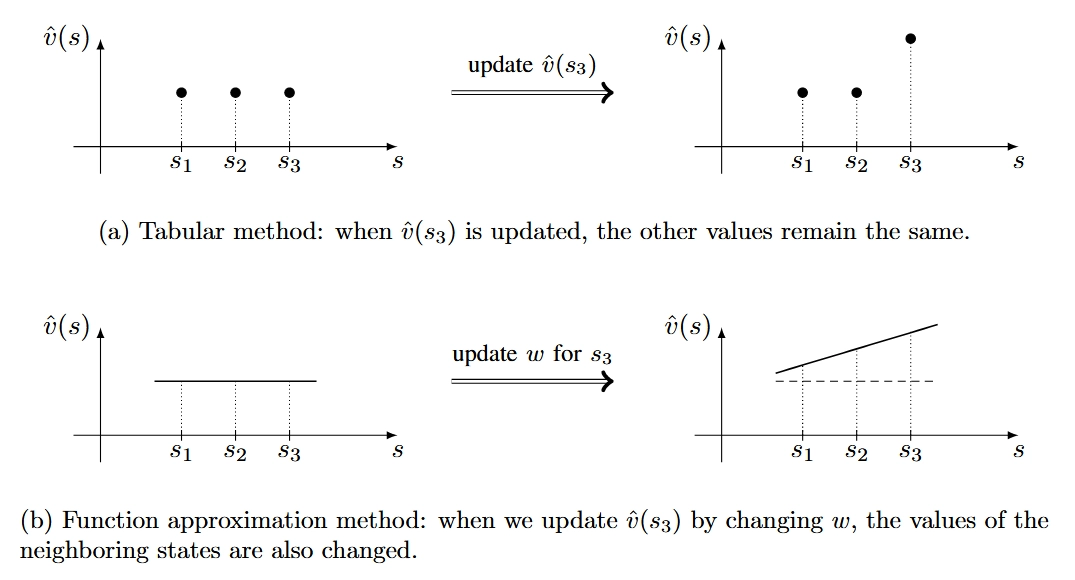
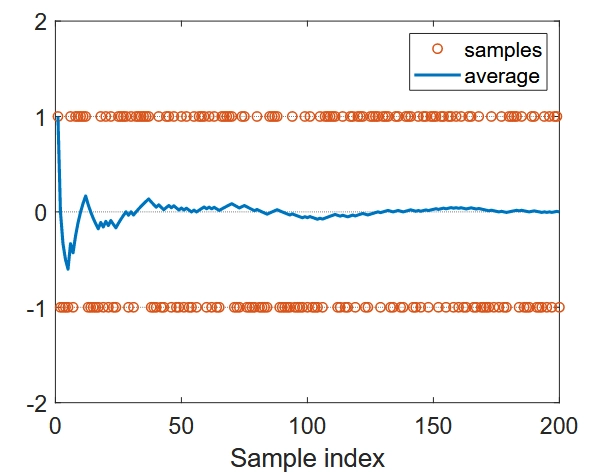
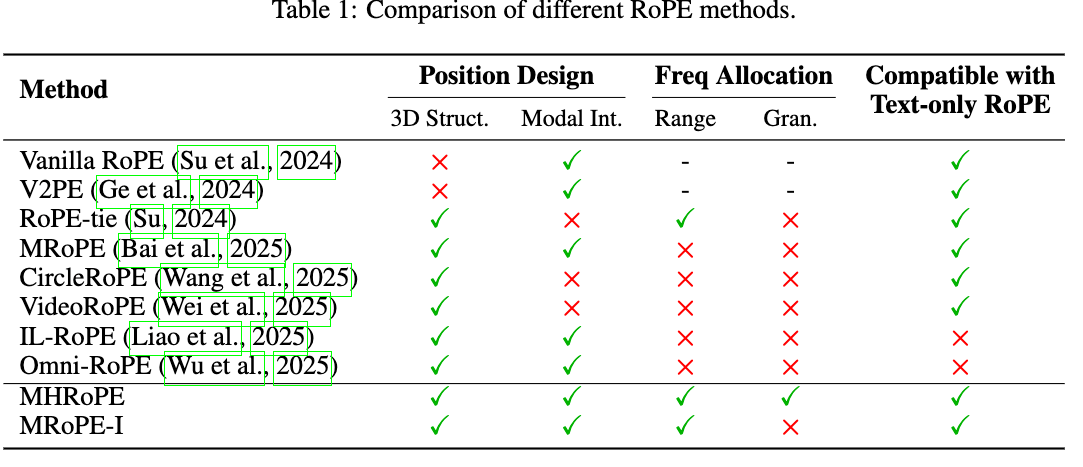
Reinforcement Learning
2026-03-31
回顾 PPO \[\begin{equation}\begin{aligned}\mathcal{J}_{\text{PPO}}(\theta) &= \mathbb{E}_{(q,a)\sim\mathcal{D}, o_{<t}\sim\pi_{\theta_{\text{old}}}(\cdot|q)} \\
&\left[ \min \left( \frac{\pi_\theta(o_t \mid q, o_{<t})}{\pi_{\theta_{\text{old}}}(o_t \mid q, o_{<t})} \hat{A}_t, \text{clip}\left(\frac{\pi_\theta(o_t \mid q, o_{<t})}{\pi_{\theta_{\text{old}}}(o_t \mid q, o_{<t})}, 1-\varepsilon, 1+\varepsilon\right) \hat{A}_t \right) \right]\end{aligned}\tag{1}\end{equation}\] 其中 \((q, a)\) 是 数据集...